在預訓練 語言模型 BERT 對 自然語言處理的衝擊還未平息時,CMU 和 Google 的研究員又放出了一個猛料:在 20 多項任務上全線碾壓 BERT 的 XLNet。:由於在公衆號中插入方式不方便,對於一個符號 "a{b}^{c}","{b}" 代表下標,"{c}" 代表上標。
1. 語言表徵學習
深度學習的基本單元是向量。我們將建模對象對應到各自的向量 x (或者一組向量 x{1}, x{2}, ..., x{n}),然後通過變換、整合得到新的向量 h,再基於向量 h 得到輸出的判斷 y。這裏的 h 就是我們說的表徵 (Representation),它是一個向量,描述了我們的建模對象。而語言表徵學習就是解決怎麼樣將一個詞、一句話、一篇文章通過變換 (Transformation) 和整合 (Aggregation) 轉化成對應的向量 h 的問題。
深度學習解決這個問題的辦法是人工設計一個帶有可調參數的模型,通過指定一系列的 (輸入→輸出) 對 (x → y),讓模型學習得到最優的參數。當參數確定之後,模型除了可以完成從 x 預測 y 的任務之外,其中間把 x 變換成 h 的方法也是可以用到其他任務的。這也是我們爲什麼要做表徵學習。
所以我們要解決的問題便是:
怎麼確定 (輸入→輸出) 對,即模型的預測任務
這個模型怎麼設計
2. 分佈式語義假設
任何任務都可以用來做表徵學習:情感分析 (輸入句子,判斷句子是正向情感還是負向情感),機器翻譯 (輸入中文,輸出英文)。但是這些任務的缺點是需要大量的人工標註,這些標註耗時耗力。當標註量不夠時,模型很容易學出"三長一短選最短"的取巧方案 -- 但我們想要的是真正的語言理解。
所幸語言學的研究中有一個重要的假設 -- 分佈式語義假設 (Distributional Hypothesis):
One shall know a word by the company it keeps.[1]
我們可以通過一個詞出現的語境知道這個詞的意思。
所以我們可以將輸入 x 定爲目標詞的語境,輸出 y 定爲目標詞。這個任務的優點是我們並不需要人工標註的數據,只需要許多有意義的語段就可以了 -- 而在信息爆炸的互聯網時代,這種數據是取之不盡的。
如何更精細地建模語境,得到其對應的表徵向量 h?對這個問題的解答貫穿了語言表徵學習的發展歷程。我們希望能夠做到:
語境要包含所有區分目標詞的信息。只有這樣纔不會有歧義的出現,比如給定語境 ["我" "今天" "很"],目標詞 (下一個詞) 既可以是 "開心",也可以是"傷心",所以模型學不到 "開心" 和 "傷心" 的區別。語境要足夠大,如對於一篇文章中的一個目標詞,理想的語境是文章中除了目標詞的所有詞。
建模語境中詞的相互依賴關係。除了詞本身的性質外 (這決定了詞的依賴關係,比如形容詞可以修飾名詞短語,貓一般不會用巍峨來修飾),在大部分語言 (如中文,英文) 中,詞的相對位置也決定了詞間的依賴關係。
下文開始我們會圍繞這個句子展開討論:
["我1", "今天2", "很3", 「開心4」, 「<逗號>5」, 「因爲6」, 「我7」, 「中8」, 「了9」, 「彩票10」]
數字代表詞在句子中的位置編號。「我 1」和「我 7」雖然是同一個詞,但因爲出現在句子的不同位置,所以他們表達的意思可能不同。假設我們的目標詞是「開心 4」,語境中便不應該含有「開心 4」,因爲這會造成標籤泄露 -- 我們在提出問題的同時也直白地給出了答案 -- 此時模型很難學出有用的語言知識。所以理想的語境建模應基於["我1", "今天2", "很3", 「<逗號>5」, 「因爲6」, 「我7」, 「中8」, 「了9」, 「彩票10」] 以及位置 "4"。
3. 預訓練詞向量 (Word Embedding)
神經網絡剛開始進入自然語言處理的時候,預訓練詞向量 (Word Embedding) 的方法如 Skip-gram, Glove 等是語言表徵學習的主要手段。由於缺乏有效建模詞的相互依賴的手段,我們使用目標詞前後的窗口內的詞作爲目標詞的語境詞 (Context Word),每個詞/語境詞都有一個獨立的向量作爲其表徵。
假如窗口長度是 2 的話,在上述例子中,我們可以得到的 (輸入→輸出) 對爲 ("很" → "開心"),("<逗號>"→ "開心"),("今天" → "開心"),("因爲" → "開心")。這裏爲了避免統計稀疏性,我們丟棄了詞的位置信息。
這種語境建模方式非常粗糙。滑動窗口只是詞間相互依賴的一種粗略估計。同時單個語境詞不足以表達豐富的語境信息 -- 這是由語境中不同詞相互依賴共同決定的。這使得該預測任務存在大量的歧義。最後由於缺乏對語境的細緻建模,我們只能學到單個詞的模糊的表徵。
4. 循環神經網絡
用一個向量代表一個詞在預訓練詞向量流行之後已經變成標準做法,也是我們用上神經網絡模型組件的基礎。我們的句子可以表示成一個有順序的向量序列:
[x{我}, x{今天}, x{很}, x{開心}, x{<逗號>}, x{因爲}, x{我}, x{中}, x{了}, x{彩票}]
爲了從這個向量序列計算出對應的表徵向量 h,我們必須對這個向量序列進行變換 (Transformation) 和整合 (Aggregation)。循環神經網絡 (Recurrent Neural Network, RNN) 通過一個遞歸算子實現了這個目的:
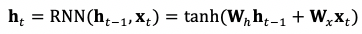
我們按照一個順序 (從左到右) 對上述向量序列編號:
[x{1}, x{2}, x{3}, x{4}, x{5}, x{6}, x{7}, x{8}, x{9}, x{10}]
按照編號的順序,在第 t 位時,循環神經網絡會根據第 t-1 位的表徵 h{t-1} 及當前的輸入 x{t} 算出當前位置的表徵 h{t} -- 這便是序列 [x{1}, x{2}, ..., x{t}] 對應的表徵。可以看到輸入向量的相對位置決定了循環神經網絡整合信息的計算順序,或者說相對位置決定了計算圖 (Computation Graph) 的構建。
5. 自迴歸語言模型
在擁有循環神經網絡這一序列建模利器之後,我們可以對語境進行更精細的建模。由於 RNN 的運算模式是按順序依次處理每個詞,所以語境可以是目標詞前面的所有詞。
對於例子 ["我 1", "今天 2", "很 3","開心 4","<逗號>5","因爲 6","我 7","中 8","了 9",彩票 10"],如果編號順序是從左到右的話,對應的輸入-輸出對爲 (["我", "今天", "很"] → "開心");而從右到左則對應的是 (["彩票", "了", "中", "我", "因爲", "<逗號>"] → "開心")。因爲目標詞總是語境的下一個詞,所以我們並不需要輸入目標詞的位置信息。如前所述,詞的相對位置決定了詞的輸入順序,所以詞的位置也不再需要輸入了。
自迴歸語言模型的優點是計算效率比較高。我們只要對["我1", "今天2", "很3", 「開心4」, 「<逗號>5」, 「因爲6」, 「我7」, 「中8」, 「了9」, 「彩票10」] 這句話做一次表徵計算,便可以得到許多輸入輸出對的語境表徵:(["我"] → "今天"),(["我", "今天"]→ "很"),(["我", "今天", "很"] → "開心") 等等。
自迴歸語言模型也是自然語言生成的標準方案 -- 一個句子的生成可以轉化成以前面的片段爲語境,預測下一個詞的任務。而新預測的詞可以拼到已經生成的片段,作爲預測下一個詞所依據的語境。
由於可以對語境進行建模,預訓練詞表徵便可以從語境無關的詞向量變成基於語境的詞表徵 (Contextual Representation)。再結合增大數據量帶來的巨大增益,這也使得 2018 年發表的 ELMo 成爲自然語言處理領域第一個刷榜的大新聞。
但這種語境建模方式只使用了目標詞左邊 (右邊) 單方向的所有詞,所以預測任務仍然會存在歧義。語料中輸入輸出對 (["我", "今天", "很"] → "開心") 和 (["我", "今天", "很"] → "傷心") 都有可能出現,所以模型學不到 "開心" 和 "傷心" 的區別。
如何將目標詞左右的語境 (雙向語境) 同時引入建模便成爲下一個需要解決的問題。一個簡單的做法是分別學一個前向及後向的自迴歸語言模型,然後再將兩個模型學出的表徵合併。這便是 ELMo 裏的標準做法。然而這種獨立建模雖然拿到了兩個方向的語境信息,但卻學不出兩個語境間細緻的依賴關係。
6. Transformer
雙向語境的建模困難主要源於循環神經網絡單向、順序的計算方式。除了限制依賴關係的方向之外,這種計算方式也限制了循環神經網絡能建模的最大依賴距離。x{1} 和 x{300} 的間依賴關係需要通過重複計算 300 次 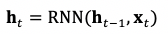 才能求得。而由於循環神經網絡中存在矩陣乘法,在計算 x{300} 時 x{1} 的信息被相同的矩陣乘了 300 次。視矩陣 W{h} 的模不同,會導致信息的爆炸 (|W{h}|>1) 或者消失 (|W{h}|<1)。
才能求得。而由於循環神經網絡中存在矩陣乘法,在計算 x{300} 時 x{1} 的信息被相同的矩陣乘了 300 次。視矩陣 W{h} 的模不同,會導致信息的爆炸 (|W{h}|>1) 或者消失 (|W{h}|<1)。
我們既要取得雙向依賴建模,又要讓長距離的依賴中間間隔的計算操作儘可能的少。Transformer 的提出實現了這兩個目的。細節如層歸一化 (Layer Normalization),多注意力算子 (Multi-Head Attention) 可以參考原論文,這裏主要介紹最核心的自注意力算子 (Self-Attention),及其基礎 -- 注意力算子 (Attention)。
我們先介紹注意力算子 (Attention)。注意力算子的基本元素爲查詢向量 (Query Vector) q{i},地址向量 (Key Vector) k{j} 以及內容向量 (Value Vector) v{j}。其輸出 h{i} 爲所有內容向量的加權求和,每個權重由查詢向量和地址向量算出的注意力權重 (Attention Score) 決定:
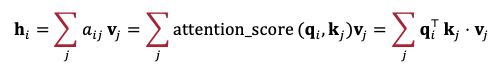
注意力算子達到的目的是基於查詢向量對一組表徵信息進行聚合。
回到建模依賴關係的問題上。既然每個詞都可能對其他詞產生依賴,那我們讓每個詞都用注意力算子從其他詞那裏聚合信息不就好了嘛!這便是自注意力 (Self-Attention) 的動機。
對於第 i 個詞,我們可以根據其詞向量 x{i} 算出其對應的查詢向量、地址向量以及內容向量:
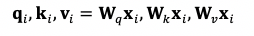
在進行表徵聚合時,q 來自要求表徵的詞,k 和 v 來自所有詞 (包括要求表徵的詞本身)。"自注意力 (Self-Attention)" 中之所以有 "自 (Self)",是因爲查詢、地址和內容的角色均來自同一個序列。
自注意力算子的引入解決了循環神經網絡的兩個問題:第 i 個詞表徵 h{i} 的構建可以同時基於雙向的語境;詞間不管依賴距離多長,都只間隔了一次運算操作。
但是自注意力算子會引入新的問題 -- 詞的相對位置的信息被丟棄了。回到我們的例句["我1", "今天2", "很3", 「開心4」, 「<逗號>5」, 「因爲6」, 「我7」, 「中8」, 「了9」, 「彩票10」],丟棄詞的相對位置意味着在自注意力算子眼裏,"我 1" 和「我 7」表達的意思是一樣的。解決這個問題的方法是將位置作爲詞表徵的一部分一併輸入模型。Transformer 採用的是簡單粗暴的加法:"我 1" 和「我 7」的表徵分別爲
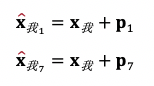 其中 p1 和 p7 是位置 1 和 7 對應的位置編碼 (Position Embedding)。這和循環神經網絡截然不同:在循環神經網絡裏,相對位置決定了計算的順序,而在 Transformer 裏則是決定了詞的表徵。在後文會提到,將位置納入詞表徵的做法在 XLNet 中被巧妙地利用了。
其中 p1 和 p7 是位置 1 和 7 對應的位置編碼 (Position Embedding)。這和循環神經網絡截然不同:在循環神經網絡裏,相對位置決定了計算的順序,而在 Transformer 裏則是決定了詞的表徵。在後文會提到,將位置納入詞表徵的做法在 XLNet 中被巧妙地利用了。
Transformer 在每個詞基於語境的表徵時會同時用上前後語境,但是自迴歸語言模型卻限制了語境的方向。鑑於自迴歸語言模型在自然語言生成中的普遍應用,爲了使用靈活的 Transformer 進行建模,我們需要對 Transformer 進行相應的修改。解決方案是對計算出的注意力權重進行屏蔽 -- 我們強行將不想要的注意力權重置爲 0,這樣計算表徵的時候就不會用到目標詞及其右邊的詞了 -- 這些詞的注意力權重爲 0。這稱之爲注意力掩碼 (Attention Mask)。這一點也是構建 XLNet 訓練目標所必須的技巧。再加上對下游任務的適配以及大量的數據,GPT 和 GPT-2 也搞了一波大新聞。
上述構造技巧再加上多注意力算子 (Multi-Head Attention) 以及標準深度學習組件的組合 (Dropout, Position-Wise FeedForwrd Layer, Layer Normalization),Transformer 給自然語言處理的建模方式帶來了變革性的貢獻,無愧其名 "Transformer"(改革者)。
7. 去噪自編碼模型/掩碼語言模型

加入 Transformer 後,我們的軍火庫多了建模雙向語境的武器。但是如前所述,自注意力算子構建的是第 i 個詞基於語境的表徵,使用這個表徵來預測第 i 個詞會帶來標籤泄露。這就好比在給你出題的時候順便直白地告訴了你答案。
我們既想用上 Transformer 的建模能力,又想從第 i 個詞的表徵中剔除這個詞的信息。以 BERT 爲代表的去噪自編碼模型 (Denoising Auto-Encoder)/掩碼語言模型 (Masked Language Modeling) 的做法是將這些詞替換成特殊字符 "MASK"。"MASK" 對應的表徵即爲原來詞的語境表徵,既獲得了雙向語境的信息,又避免了標籤泄露,可以用來預測原來的詞。爲了複用計算出的表徵,BERT 會隨機選取多個詞替換成 "MASK",然後在對應的位置分別預測原來的詞。由於這些詞都被替換成相同的字符 "MASK",他們對應的語境表徵計算的區別主要來自於其位置編碼。
對於本文開頭的例子,我們構建的 (輸入→輸出) 對爲 (["我1", "今天2", "很3", 「MASK4」,「<逗號>5」,「因爲6」,「我7」,「中8」,「了9」,「彩票10」]→ 開心)。
雖然結合 Transformer 和去噪自編碼模型的 BERT 可以說是拿到了語境建模的"雙向聖盃",其設計的次句判斷任務 (Next sentence prediction) 也對下游任務有重要幫助。但是人無完人,BERT 無完 BERT。BERT 中 "MASK" 字符的加入,使得非目標詞表徵的建模都會依賴於人造的 "MASK" 字符,這會使模型學出虛假的依賴關係 (比如 "MASK" 可以作爲不同詞信息交換的橋樑) -- 但 "MASK" 在下游任務中並不會出現。這便是 XLNet 中提到的預訓練-微調差異 (Pretrain-Finetune Discrepancy)。同時除了位置編碼 p 的區別外,同一句話內所有目標詞依賴的語境信息完全相同,這除了忽略被替換的詞間的依賴關係外,隨着網絡層數的加深,作爲輸入的位置編碼 p 的信息也可能被過多的計算操作抹去 (類似於上述循環神經網絡難以建模長程依賴的原因)。
8. XLNet 的核心貢獻: 亂序語言模型
如上所述,BERT 雖然充分地建模了雙向語境信息,但是其用來預測不同目標詞的語境信息只有目標位置編碼的區別,同時也建模不了被替換成 "MASK" 的詞間的依賴關係。自迴歸語言模型雖然只能建模單向的語境,但是其計算效率比較高,且預測每個詞所用的語境都是不一樣的。怎麼把這兩者的長處結合呢?
回顧我們對自迴歸語言模型的介紹。對於一句話["我1", "今天2", "很3", 「開心4」, 「<逗號>5」, 「因爲6」, 「我7」, 「中8」, 「了9」, 「彩票10」],我們得到的輸入輸出樣本爲(["我"] → "今天"),(["我", "今天"]→ "很"),(["我", "今天", "很"] → "開心")...等等。這些樣本中的語境毫無例外都是單向且有序的。
對樣本語境的選取是否可以更靈活一些?在上述對分佈式語義假設的介紹中我們提到,語境中的詞之間的相互依賴關係,一是取決於詞本身的性質,二是取決於語境中詞的相對位置。所以有了詞以及詞在語境中的位置,我們就有了從這個詞構建依賴關係的全部信息。所以對於同一句話 ["我 1", "今天 2", "很 3",「開心 4」,「<逗號>5」,「因爲 6」,「我 7」,「中 8」,「了 9」,「彩票 10」],我們可以使用更靈活的樣本選取辦法,得到(["我1"] → 「開心4」),([「我1」, 「開心4」] → 」今天2「),([」我1「, 」今天2「, 「開心4」] → 「很3」)...等等。這便是亂序語言模型 (Permutation Language Modeling) 的思想。和自迴歸語言模型不一樣,新的樣本中的語境需要輸入詞的位置,否則就退化成了詞帶模型 (Bag of Words)。這可以類比到人的閱讀方式:字詞在書本上的位置是一定的,但從左到右的閱讀順序並不是強制的,我們還可以跳讀。
從概率模型的角度考慮,上述對樣本的採樣方式的不同對應了對句子概率 P("我1", "今天2", "很3", 「開心4」, 「<逗號>5」, 「因爲6」, 「我7」, 「中8」, 「了9」, 「彩票10」) 的不同分解。
對於自迴歸語言模型,其分解方式爲P("我 1")P("今天 2" |"我 1")P("很 3"|"我 1", "今天 2")P("開心 4"|"我 1", "今天 2", "很 3")...
對於亂序語言模型,其分解方式可以爲P("我 1")P("開心 4"|"我 1")P("今天 2"|"我 1","開心 4")P("很 3"|"我 1","今天 2","開心 4")...
每一種分解方式由一個隨機排列 z 確定,如上述分解方式對應 z = [z{1} ,z{2} , z{4} , z{3} , ...] → ["我 1"→"今天 2"→"開心 4"→"很 3"→ ...]
其中 z{t} 代表隨機排列的第 t 個詞。亂序語言模型是自迴歸語言模型的一種推廣,因爲 z 可以是原來序列的順序。
亂序語言模型的語境可以同時來自目標詞的前向和後向,所以其建模了雙向的依賴。每個被預測的詞 (除最後一個詞外) 都會加入到語境中,所以既解決了 BERT 忽略被替換的詞間的依賴關係的問題,又解決了 BERT 不同目標詞依賴的語境趨同的問題。相比於 BERT 一次性輸入幾乎所有的語境信息,亂序語言模型可以認爲是對雙向語境進行了採樣 (或者 Embedding Dropout),這會產生類似於 Dropout 效果,可以讓模型學出更魯棒的語境依賴。
但需要注意的是,當構成語境的詞比較少時,根據語境預測目標詞的歧義性就會增大,訓練難度也會增大。這也是爲什麼 XLNet 只採樣了一小部分詞去預測的原因。
講了這麼多好處,那如何用 Transformer 實現亂序語言模型呢?
9. 亂序語言模型的實現:雙自注意力通道
Transformer 中每個詞的表徵由其詞向量和位置編碼共同決定 -- 我們既拿到了詞本身的性質,又有詞的位置信息。所以 Transformer 天然就和亂序語言模型相契合。
假設整句話爲 ["我 1", "今天 2", "很 3",「開心 4」],我們只採樣出一個樣本 (["今天 2", "很 3", "開心 4"] → "我 1" ),XLNet 的做法和 BERT 有同有異。
和 BERT 一樣,XLNet 同樣是將目標詞 "我 1" 替換成一個特殊字符 "MASK1"。和 BERT 不同,"MASK" 不會納入表徵的地址向量 k 以及內容向量 v 的計算,"MASK" 自始至終只充當了查詢向量 q 的角色,因此所有詞的表徵中都不會拿到 "MASK" 的信息。這也杜絕了 "MASK" 的引入帶來的預訓練-微調差異 (Pretrain-Finetune Discrepancy) -- 這個改動也可以直接應用到 BERT 上面。
在下圖中記 "MASK" 對應的詞向量爲 G,X2 - X4 爲各自的詞向量,G1, H1 - H4 爲各自的表徵。圖中省略了位置編碼 p。
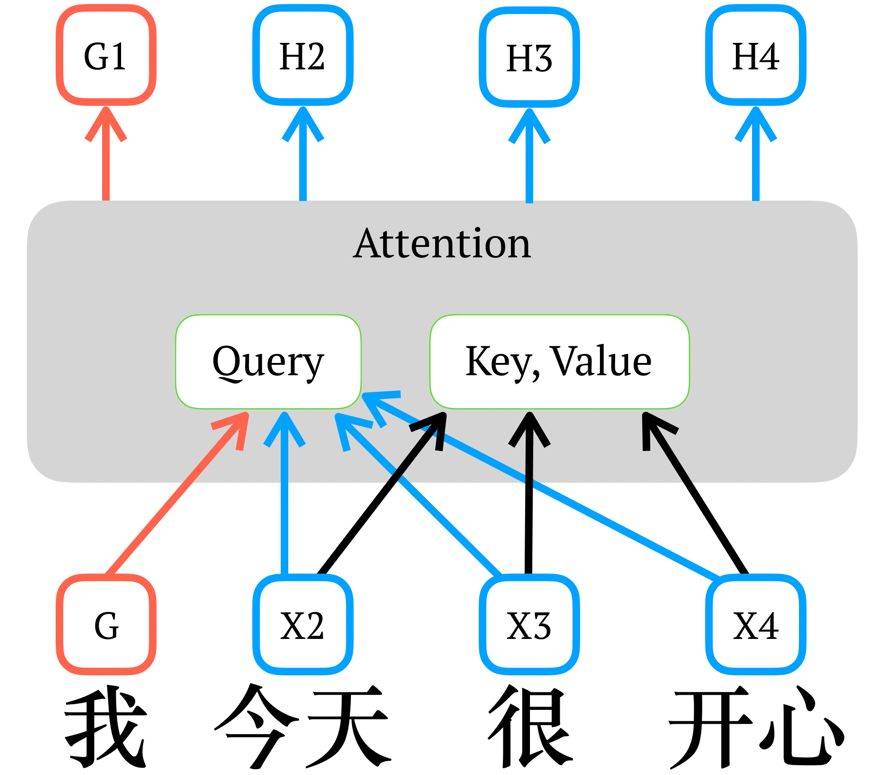
上面只是討論最簡單的情況 -- 即一句話只產生一個樣本。但我們還希望保證訓練效率 -- 我們想和自迴歸語言模型一樣,只進行一次整句的表徵計算便可以獲得所有樣本的語境表徵。這時所有詞的表徵就必須同時計算,此時便有標籤泄露帶來的矛盾:對於某個需要預測的目標詞,我們既需要得到包含它信息以及位置的表徵 h (用來進一步計算其他詞的表徵),又需要得到不包含它信息,只包含它位置的表徵 g (用來做語境的表徵)。
一個很自然的想法就是同時計算兩套表徵,這便是 XLNet 提出的雙通道自注意力 (Two Stream Self-Attention),同時計算內容表徵通道 (Content Stream) h 和語境表徵通道 (Query Stream) g。注意這裏採用的是意譯而不是直譯,請讀者諒解。
假設我們要計算第 1 個詞在第 l 層的語境表徵 g{1}^{l} 和內容表徵 h{1}^{l},我們只關注注意力算子查詢向量 Q、地址向量 K 以及內容向量 V 的來源:
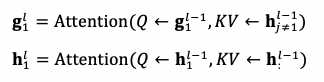
計算 g{1}^l 時用到了 h{j!=1}^{l-1},表示第 l-1 層除了第 1 個詞外所有詞的表徵,這是爲了保證標籤不泄露;計算 h{1}^{l} 時用到了 h{:}^{l-1},表示第 l-1 層所有詞的表徵,這和標準的 Transformer 計算表徵的過程一致。
但上述做法在堆疊多層自注意算子時仍然會帶來標籤泄露。
雖然計算 g{1}^{l} 時我們已經採取措施防止 h{1}^{l-1} 的信息泄露到 g{1}^{l} 中,但是考慮兩層自注意力算子的計算:
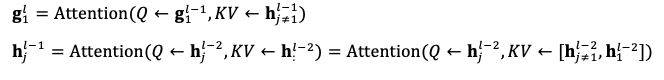
我們看到第 l-2 層第 1 個詞的表徵 h{1}^{l-2} 會通過第 l-1 層的所有表徵 h{j}^{l-1} 泄露給 g{1}^{l}。
和將 Transformer 應用到自迴歸語言模型的情況類似,我們還需要對每層的注意力使用注意力掩碼 (Attention Mask),根據選定的分解排列 z,將不合理的注意力權重置零。我們記 z{t} 爲分解排列中的第 t 個詞,那我們在詞 z{t} 的表徵時,g{t}^{l} 和 h{t}^{l} 分別只能看到排列中前 t-1 個詞 z{1:t-1} 和前 t 個詞 z{1:t},即
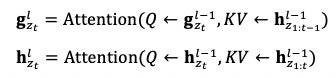
在如此做完注意力掩碼後,所有 g{z{t}}^l 便可以直接用來預測詞 z{t},而不會有標籤泄露的問題。
這裏我們也可以看到,在具體實現效率的限制下,想要獲得多樣的語境並防止標籤泄露,我們只能依據亂序語言模型的定義去使用注意力掩碼。這也體現了 XLNet 設計的精巧性。
10. XLNet 的重要元素:Transformer-XL
上面已經提到,和循環神經網絡不同,Transformer 是同時計算語段內所有詞的表徵的。受限於系統內存大小,Transformer 輸入的序列長度會有一個上限。通常我們會將過長的序列切成固定長度爲 N 的片段,再依次輸入 Transformer 計算表徵。所以 Transformer 的構造雖然降低了長程依賴的學習難度,但其最長只能建模長度爲 N 的依賴。
爲了在內存的限制下讓 Transformer 學到更長的依賴,Transformer-XL 借鑑了 TBPTT(Truncated Back-Propagation Through Time) 的思路,將上一個片段 s{t-1} 計算出來的表徵緩存在內存裏,加入到當前片段 s{t} 的表徵計算中。
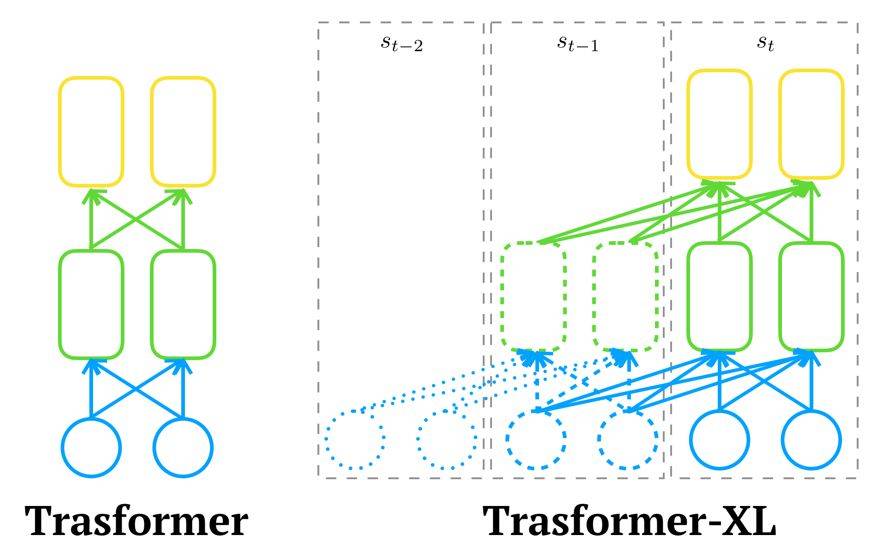
如上圖所示,由於計算第 l 層的表徵時,使用的第 l-1 層的表徵同時來自於片段 s{t} 和 s{t-1},所以每增加一層,模型建模的依賴關係長度就能增加 N。在上圖中,Transformer-XL 建模的最長依賴關係爲 3*2=6。
但這又會引入新的問題。Transformer 的位置編碼 (Position eEmbedding) 是絕對位置編碼 (Absolute Position Embedding),即每個片段內,各個位置都有其獨立的一個位置編碼向量。所以片段 s{t} 第一個詞和片段 s{t-1} 第一個詞共享同樣的位置編碼 -- 這會帶來歧義。
Transformer-XL 引入了更加優雅的相對位置編碼 (Relative Position Embedding)。
因爲位置編碼只在自注意力算子中起作用,我們將 Transformer 的自注意力權重的計算拆解成:
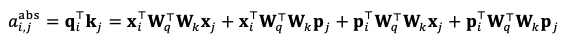
我們可以將其中的絕對位置編碼 p{j} 的計算替換成相對位置編碼 r{i-j},把 p{i} 替換成一個固定的向量 (認爲位置 i 是相對位置的原點)。這樣便得到相對位置編碼下的注意力權重:
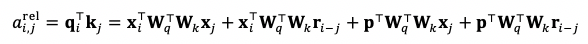
Transformer-XL 的實際實現方式與上式有所不同,但思想是類似的。
相對位置編碼解決了不同片段間位置編碼的歧義性。通過這種拆解,我們可以進一步將相對位置編碼從詞的表徵中抽離,只在計算注意力權重的時候加入。這可以解決 Transformer 隨着層數加深,輸入的位置編碼信息被過多的計算抹去的問題。Transformer-XL 在 XLNet 中的應用使得 XLNet 可以建模更長的依賴關係。
11. XLNet 的模型改進增益
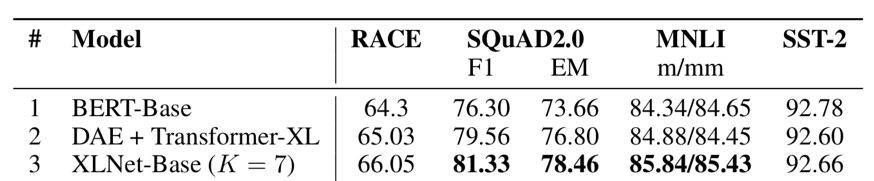
文章最後的消融分析很好地證明了亂序語言模型和 Transformer-XL 主幹網絡帶來的提升。這部分實驗採用和 BERT 一致的訓練數據。以 BERT 爲基礎,將 BERT 的主幹網絡從 Transformer 換成 Transformer-XL 後,在需要建模較長上下文的閱讀理解任務 RACE 和 SQuAD2.0 均有比較明顯地提升 (對比 1&2 行)。而在此基礎上加上亂序語言模型後,在所有任務上都有不同程度的提升 (對比 2&3 行)。
12. 如何評價 XLNet
自詞向量到如今以 XLNet 爲代表的預訓練語言模型,他們的主要區別在於對語境的不同粒度的建模:

XLNet 的成功來自於三點:
分佈式語義假設的有效性,即我們確實可以從語料的統計規律中習得常識及語言的結構。
對語境更加精細的建模:從"單向"語境到"雙向"語境,從"短程"依賴到"長程"依賴,XLNet 是目前對語境建模最精細的模型。
在模型容量足夠大時,數據量的對數和性能提升在一定範圍內接近正比 [3] [4]:XLNet 使用的預訓練數據量可能是公開模型裏面最大的。
可以預見的是資源豐富的大廠可以閉着眼睛繼續順着第三點往前走,或許還能造出些大新聞出來,這也是深度學習給的承諾。這些大新聞的存在也漸漸堵住調參式的工作的未來,迫使研究者去思考更加底層,更加深刻的問題。
對語境的更精細建模自然是繼續發展的道路,以語言模型爲代表的預訓練任務和下游任務之間的關係也亟待探討。
退後一步講,分佈式語義假設的侷限性在哪裏?根據符號關聯假設 (Symbol Interdependency Hypothesis)[5],雖然語境的統計信息可以構建出符號之間的關係,從而確定其相對語義。但我們仍需要確定語言符號與現實世界的關係 (Language Grounding),讓我們的 AI 系統知道,「紅色」對應的是紅色,「天空」對應的是天空,「國家」對應的是國家。這種對應信息是通過構建知識庫,還是通過和視覺、語音系統的聯合建模獲得?解決這一問題可能是下一大新聞的來源,也能將我們往 AI 推進一大步。
基於分佈式語義假設的預訓練同時受制於報道偏差 (Reporting Bias)[6]:不存在語料裏的表達可能是真知識,而存在語料裏面的表達也可能是假知識,更不用提普遍存在的模型偏見 (Bias) 了。我們不能因爲一百個人說了「世上存在獨角獸」就認爲其爲真,也不能因爲只有一個人說了「地球繞着太陽轉」便把它當做無益的噪聲丟棄掉。
爲了達到足夠大的模型容量,我們真的需要這麼大的計算量嗎?已經有工作證明訓練充分的 Transformer 裏面存在很多重複冗餘的模塊 [6]。除了把網絡加深加寬外,我們還有什麼辦法去增大模型容量的同時,保持一定的計算量?
參考文獻
[1] Firth, J. R. (1957). Papers in linguistics 1934–1951. London: Oxford University Press.
[2] Levy O, Goldberg Y. Neural word embedding as implicit matrix factorization[C]//Advances in neural information processing systems. 2014: 2177-2185.
[3] Mahajan D, Girshick R, Ramanathan V, et al. Exploring the limits of weakly supervised pretraining[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 181-196.
[4] Hestness J, Narang S, Ardalani N, et al. Deep learning scaling is predictable, empirically[J]. arXiv preprint arXiv:1712.00409, 2017.
[5] Louwerse M M. Knowing the meaning of a word by the linguistic and perceptual company it keeps[J]. Topics in cognitive science, 2018, 10(3): 573-589.
[6] Gordon J, Van Durme B. Reporting bias and knowledge acquisition[C]//Proceedings of the 2013 workshop on Automated knowledge base construction. ACM, 2013: 25-30.
[7] Michel P, Levy O, Neubig G. Are Sixteen Heads Really Better than One?[J]. arXiv preprint arXiv:1905.10650, 2019.