
阿里妹導讀:自然語言處理領域的殿堂標誌 BERT 並非橫空出世,背後有它的發展原理。今天,螞蟻金服財富對話算法團隊整理對比了深度學習模型在自然語言處理領域的發展歷程。從簡易的神經元到當前最複雜的BERT模型,深入淺出地介紹了深度學習在 NLP 領域進展,並結合工業界給出了未來的 NLP 的應用方向,相信讀完這篇文章,你對深度學習的整體脈絡會有更加深刻認識。
一個神經網絡結構通常包含輸入層、隱藏層、輸出層。輸入層是我們的 features (特徵),輸出層是我們的預測 (prediction)。神經網絡的目的是擬合一個函數 f*:features -> prediction。在訓練期間,通過減小 prediction 和實際 label 的差異的這種方式,來更改網絡參數,使當前的網絡能逼近於理想的函數 f*。
神經元(Neural Cell)
神經網絡層的基本組成成員爲神經元,神經元包含兩部分,一部分是上一層網絡輸出和當前網絡層參數的一個線性乘積,另外一部分是線性乘積的非線性轉換。(如果缺少非線性轉換,則多層線性乘積可以轉化爲一層的線性乘積)
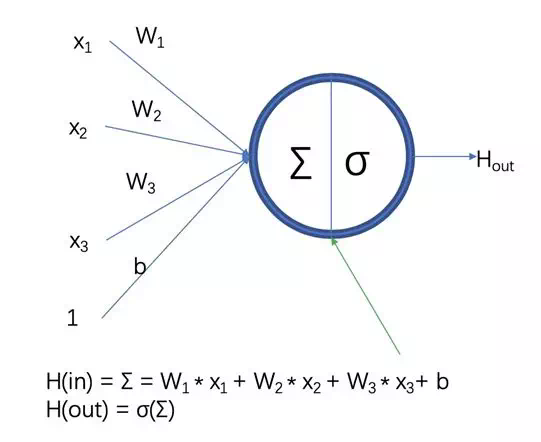
圖一
淺層神經網絡( Neural Network )
只有一層隱藏層的,我們稱爲淺層網絡。
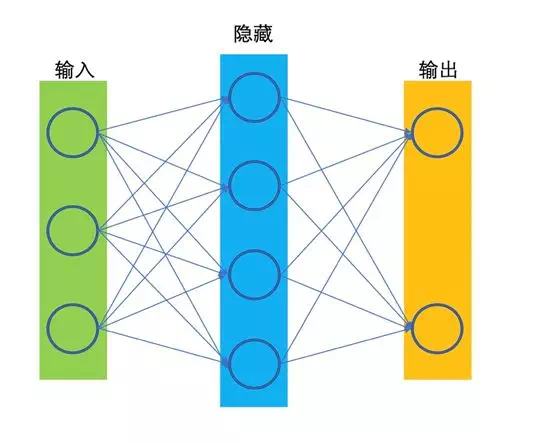
圖二
深度學習網絡(Multilayer Perceptron)
相對於淺層網絡結構,有兩層、三層及以上隱藏層的我們就可以稱爲深度網絡。
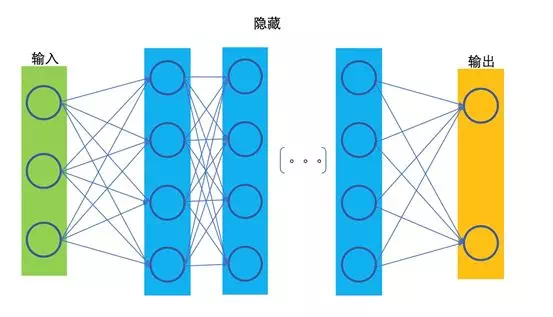
圖三
在通常的理解中,一個足夠寬的網絡,是能夠擬合任何函數的。而一個深層網絡,則能夠用更少的參數來擬合該函數,因爲深層的神經元可以獲取比淺層神經元更復雜的特徵表示。
在圖二及三所示網絡,我們稱爲全連接網絡,也就是隱藏層的神經元會和上一層所有的神經元輸出相關。和全連接網絡相對應的,是隻和上一層部分神經元輸出連接的網絡,如下文介紹的卷積網絡。
卷積網絡(CNN)
卷積網絡神經元只和上一層的部分神經元輸出是連接的。(在直覺上,是因爲人的視覺神經元觸突只對局部信息敏感,而不是全局所有信息都對同一個觸突產生等價作用)
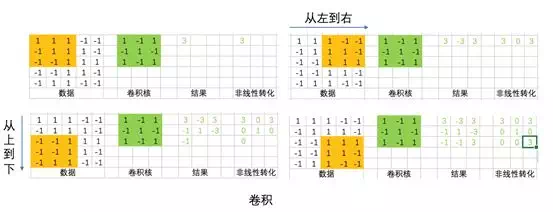
同一個卷積核從左到右,從上到下和輸入做乘積,得到了不同強度的輸出。從直覺上來理解,卷積覈對原始數據的不同數據分佈的敏感度是不一樣的。如果把卷積核理解爲是某種 pattern,那麼符合這種 pattern 的數據分佈會得到比較強的輸出,而不符合這種 pattern 的輸出則得到弱的,甚至是不輸出。
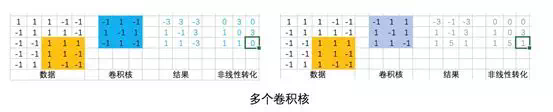 一個卷積核是一個 pattern 提取器, 多個卷積核就是多個 pattern 提取器。通過多個特徵提取器對原始數據做特徵提取轉換,就構成了一層卷積。
一個卷積核是一個 pattern 提取器, 多個卷積核就是多個 pattern 提取器。通過多個特徵提取器對原始數據做特徵提取轉換,就構成了一層卷積。
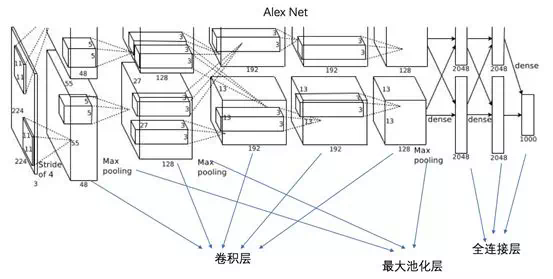
Alex Net, 因爲 GPU 內存的原因,Alex 使用了兩塊 GPU 對模型做了切割,本質上的卷積層是用於特徵提取, 最大池化層用於提取強特徵及減少參數,全連接層則是所有高級特徵參與到最後分類決策中去。
循環神經網絡(RNN)
CNN是對空間上特徵的提取, RNN則是對時序上特徵的提取。
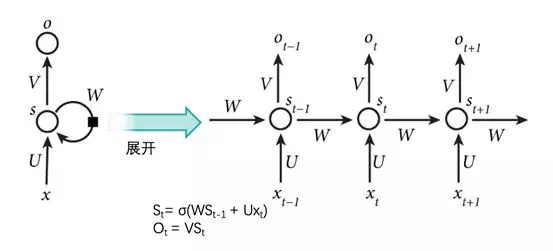
在RNN中,x1 , x2, x3, xt 是在時序上不一樣的輸入,而 V, U, W 三個矩陣則是共享。同時 RNN 網絡中保存了自己的狀態 S。 S 隨着輸入而改變,不同的輸入/不同時刻的輸入或多或少影響 RNN 網絡的狀態 S。而 RNN 網絡的狀態 S 則決定最後的輸出。
在直覺上,我們理解 RNN 網絡是一個可模擬任何函數的一個神經網絡( action ),加上同時有一份自己的歷史存儲( memory ),action+memory 兩者讓 RNN 成爲了一個圖靈機器。
長短期記憶網絡( LSTM )
RNN 的問題是非線性操作 σ 的存在且每一步間通過連乘操作傳遞,會導致長序列歷史信息不能很好的傳遞到最後,而有了 LSTM 網絡。
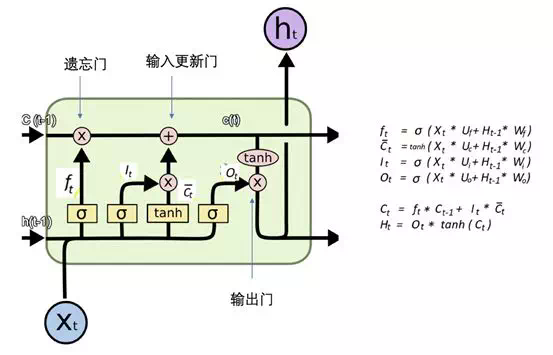
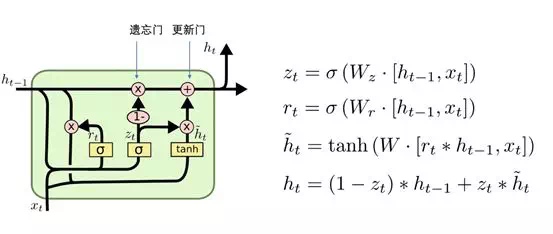
在 lstmcell 中, 包含了通常意義上的遺忘門(點乘,決定什麼要從狀態中去除),輸入更新門(按位相加,決定什麼要添加到狀態中去),輸出門(點乘,決定狀態的輸出是什麼?)雖然看起來很複雜,本質上是矩陣的運算。
爲了簡化運算,後面有 lstm 的變種 GRU, 如下圖:
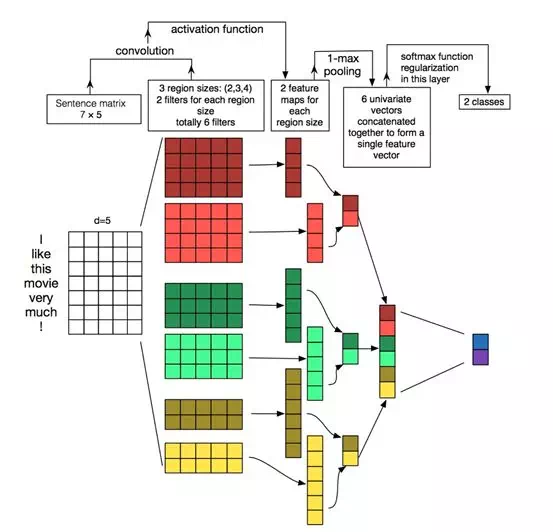
文本卷積網絡 (TextCNN)
CNN 在計算機識別領域中應用廣泛,其捕捉局部特徵的能力非常強,爲分析和利用圖像數據的研究者提供了極大的幫助。TextCNN 是2014年 Kim 在 EMNLP 上提出將 CNN 應用於 NLP 的文本分類任務中。
從直觀上理解,TextCNN 通過一維卷積來獲取句子中 n-gram 的特徵表示。TextCNN 對文本淺層特徵的抽取能力很強,在短文本領域如搜索、對話領域專注於意圖分類時效果很好,應用廣泛,且速度快,一般是首選;對長文本領域,TextCNN 主要靠 filter 窗口抽取特徵,在長距離建模方面能力受限,且對語序不敏感。
卷積核( filter )→ n-gram 特徵
文本卷積與圖像卷積的不同之處在於只在文本序列的一個方向做卷積。對句子單詞每個可能的窗口做卷積操作得到特徵圖( feature map )。
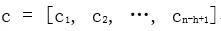
其中,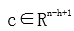 。對 feature map 做最大池化( max-pooling )操作,取中最大值max{c} 作爲 filter 提取出的 feature。通過選擇每個 feature map 的最大值,可捕獲其最重要的特徵。
。對 feature map 做最大池化( max-pooling )操作,取中最大值max{c} 作爲 filter 提取出的 feature。通過選擇每個 feature map 的最大值,可捕獲其最重要的特徵。
每個 filter 卷積核產生一個 feature ,一個 TextCNN 網絡包括很多不同窗口大小的卷積核,如常用的 filter size ∈{3,4,5} 每個 filter 的 featuremaps=100。
增強序列推理模型(ESIM)
ESIM (Enhanced Sequential Inference Model) 爲短文本匹配任務中常用且有力的模型。它對於 LSTM 的加強主要在於:將輸入的兩個 LSTM 層( Encoding Layer) 通過序列推理交互模型輸出成新的表徵。
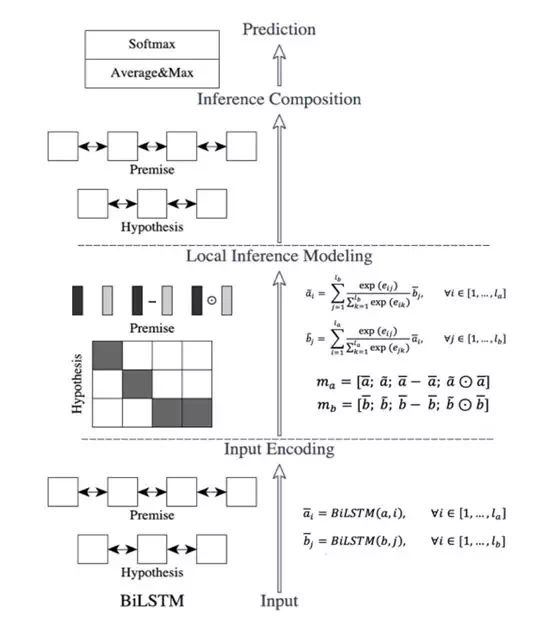
圖片來源:paper《Enhanced LSTM for Natural LanguageInference》
如圖所示,ESIM 爲圖的左邊部分。整體網絡結構其實比較明確,整條通路大致包括三個步驟。
步驟一:編碼層。該步驟每個 token 將預訓練的編碼通過 Bi-LSTM 層,從而獲取了「新的編碼」,其目的是通過 LSTM 學習每個 token 的上下文信息。
步驟二:局部推理層。步驟二本質是一個句間注意力( intra-sentence attention )的計算過程。通過將兩句在步驟一中獲取的結果做 intra-sentence attention 操作,我們在這裏可以獲取到一個新的向量表徵。接下來對向量的前後變化進行了計算,該做法的目的是進一步抽取局部推理信息在 attention 操作的前後變化,並捕捉其中的一些推理關係,如前後關係等。
步驟三:組合推理&預測層。再次將抽取後的結果通過 Bi-LSTM,並使用Avarage&Maxpooling 進行池化(其具體操作就是分別進行 average 和 max pooling 並進行 concat),最後加上全連接層進行 Softmax 預測其概率。
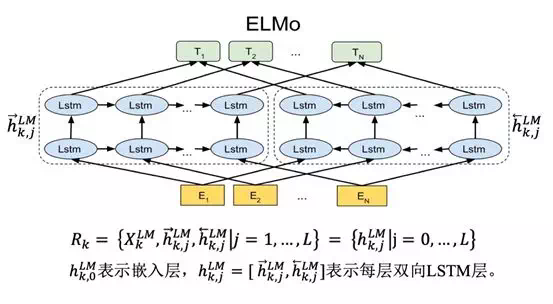
ELMo
直觀上來講,ELMo(Embedding from Language Model) 解決了一詞多義的問題,例如詢問「蘋果」的詞向量是什麼,ELMo 會考慮是什麼語境下的「蘋果」,我們應該去詢問「蘋果股價」裏的「蘋果」詞向量是什麼。ELMo 通過提供詞級別、攜帶上下文信息的動態表示,能有效的捕捉語境信息。ELMo 的提出對後面的的 GPT 和 BRET有一個很好的引導和啓發的作用。一個好的詞向量,應滿足兩個特點:
能夠反映出語義和語法的複雜特徵。
能夠準確對不同上下文產生合適語義。
傳統的 word2vec 對每個 word 只有一個固定的 embedding 表達,不能產生攜帶上下文信息的 embedding,對多義詞無法結合語境判斷。ELMo 中的每個單詞都要先結合語境通過多層 LSTM 網絡纔得到最後的表達,LSTM 是爲捕獲上下文信息而生,因而 ELMo 能結合更多的上下文語境,在一詞多意上的效果比 word2vec 要好。
ELMo 預訓練時的網絡結構圖與傳統語言模型有點類似,直觀理解爲將中間的非線性層換成了 LSTM,利用 LSTM 網絡更好的提取每個單詞在當前語境中的上下文信息,同時增加了前向和後向上下文信息。.
預訓練
給定包含 N 個詞的序列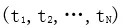 ,前向語言模型通過前 k-1個詞
,前向語言模型通過前 k-1個詞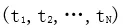 預測第 k 個詞
預測第 k 個詞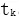 。在第 k 個位置,每個 LSTM 層輸出上下文依賴的向量表達
。在第 k 個位置,每個 LSTM 層輸出上下文依賴的向量表達 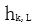 , j=1,2,…,L。頂層 LSTM 層的輸出
, j=1,2,…,L。頂層 LSTM 層的輸出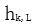 利用交叉熵損失預測下一個位置
利用交叉熵損失預測下一個位置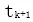 。
。
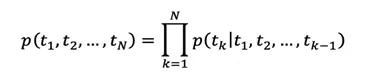
後向語言模型對序列做反序,利用下文的信息去預測上文的詞。與前向類似,給定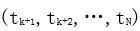 經過 L 層的後向深層 LSTM 網絡預測得到第 j 層的隱層輸出
經過 L 層的後向深層 LSTM 網絡預測得到第 j 層的隱層輸出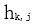 。
。
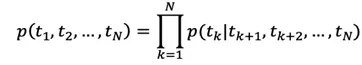
雙向語言模型拼接前向語言模型和後向語言模型,構建前向和後向聯合最大對數似然。
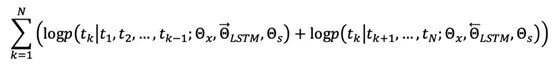
其中,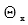 爲序列詞向量層參數,
爲序列詞向量層參數,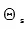 爲交叉熵層參數,在訓練過程中這兩部分參數共享。
爲交叉熵層參數,在訓練過程中這兩部分參數共享。
嵌入式語言模型組合利用多層 LSTM 層的內部信息,對中心詞,一個 L 層的雙向語言模型計算得到 2L+1 個表達集合。
Fine-tune
在下游任務中,ELMo 將多層的輸出整合成一個向量,將所有 LSTM 層的輸出加上normalized 的 softmax 學習到的權重 s=Softmax(w),使用方法如下所示:
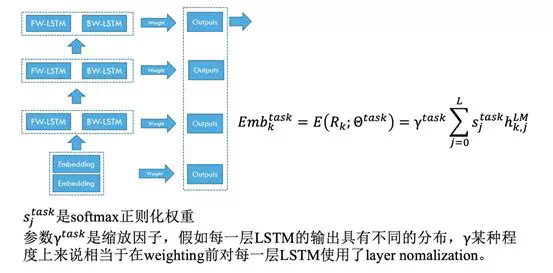
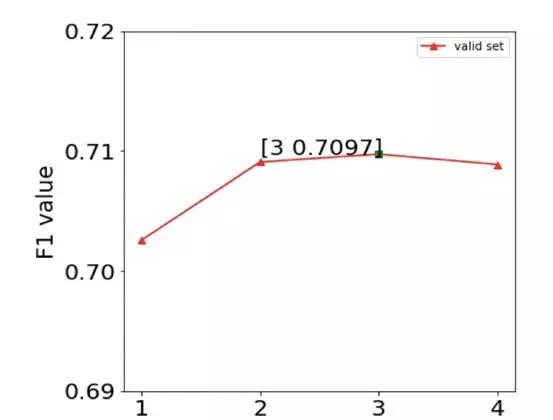
直觀上來講,biLMs 的較高層次的 LSTM 向量抓住的是詞彙的語義信息, biLMs 的較低層次的 LSTM 向量抓住的是詞彙的語法信息。這種深度模型所帶來的分層效果使得將一套詞向量應用於不同任務有了可能性,因爲每個任務所需要的信息量是不同的。另外 LSTM 的層數不宜過多,多層 LSTM 網絡不是很容易 train 好,存在過擬合問題。如下圖是一個多層 LSTM 用在文本分類問題的實驗結果,隨着 LSTM 層數增多,模型效果先增加後下降。
Transformer
曾經有人說,想要提升 LSTM 效果只要加一個 attention 就可以。但是現在attention is all you need。Transformer 解決了 NLP 領域深層網絡的訓練問題。
Attention 此前就被用於衆多 NLP 的任務,用於定位關鍵 token 或者特徵,比如在文本分類的最後加一層 Attention 來提高性能。Transformer 起源自注意力機制(Attention),完全拋棄了傳統的 RNN,整個網絡結構完全是由 Attention 機制組成。Transformer 可以通過堆疊 Transformer Layer 進行搭建,作者的實驗是通過搭建編碼器和解碼器各6層,總共12層的 Encoder-Decoder,並在機器翻譯中取得了 BLEU 值的新高。
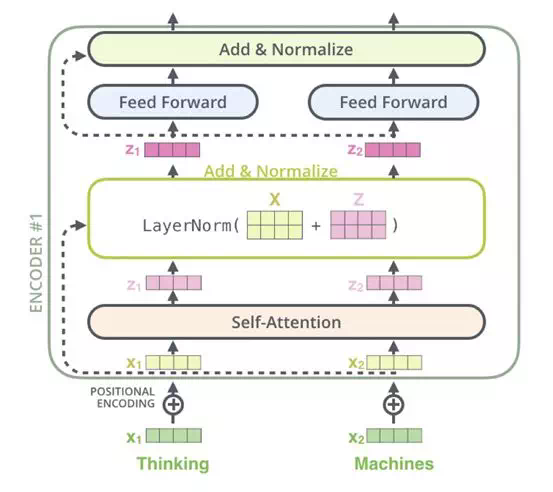
整個流程的可視化如圖:以N=2示例,實際Transformer的N=6。
Encoder 階段:輸入「Thinking Machines」,對應詞向量,疊加位置向量 Positional Encoding,對每個位置做 Self-Attention 得到;Add&Norm 分兩步,residual connection即,layer Normalization 得到新的,對每個位置分別做 feed forward 全連接和 Add&Norm,得到一個 Encoder Layer 的輸出,重複堆疊2次,最後將 Encoder Layer 輸出到 Decoder 的 Encoder-Decoder Layer 層。
Decoder 階段:先是對 Decoder 的輸入做 Masked Self-Attention Layer,然後將Encoder 階段的輸出與 Decoder 第一級的輸出做 Encoder-Decoder Attention,最後接 FFN 全連接,堆疊2個 Decoder,最後接全連接+Softmax 輸出當前位置概率最大的的詞。
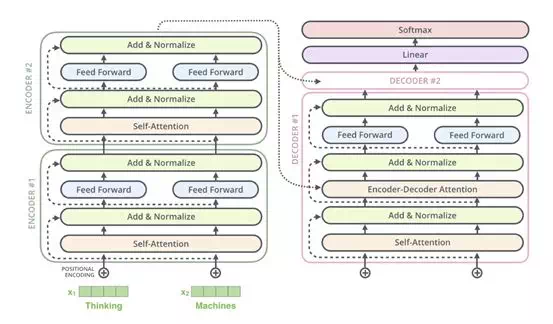
Transformer 的結構上比較好理解,主要是裏邊的細節比較多,如 Mult-HeadAttention, Feed Forward, Layer Norm, Positional Encoding等。
Transformer的優點:
並行計算,提高訓練速度。這是相比 LSTM 很大的突破,LSTM 在訓練的時候 ,當前步的計算要依賴於上一步的隱狀態,這是一個連續過程,每次計算都需要等之前的計算完成才能展開,限制模型並行能力。而 Transformer 不用LSTM結構,Attention 機制的每一步計算只是依賴上一層的輸出,並不依賴上一詞的信息,因而詞與詞之間是可以並行的,從而訓練時可以並行計算, 提高訓練速度。
一步到位的全局聯繫捕捉。順序計算的過程中信息會丟失,儘管 LSTM 等門機制的結構一定程度上緩解了長期依賴的問題,但是對於特別長期的依賴現象,LSTM 依舊無能爲力。Transformer 使用了 Attention 機制,從而將序列中的任意兩個位置之間的距離是縮小爲1,這對解決 NLP 中棘手的長期依賴問題是非常有效的。
總結對比CNN、RNN和Self-Attention:
CNN:只能看到局部領域,適合圖像,因爲在圖像上抽象更高層信息僅僅需要下一層特徵的局部區域,文本的話強在抽取局部特徵,因而更適合短文本。
RNN:理論上能看到所有歷史,適合文本,但是存在梯度消失問題。
Self-Attention:相比 RNN 不存在梯度消失問題。對比 CNN 更加適合長文本,因爲能夠看到更遠距離的信息,CNN 疊高多層之後可以看到很遠的地方,但是 CNN本來需要很多層才能完成的抽象,Self-Attention 在很底層就可以做到,這無疑是非常巨大的優勢。
BERT
BERT (Bidirectional Encoder Representations from Transformers) 本質來講是NLP 領域最底層的語言模型,通過海量語料預訓練,得到序列當前最全面的局部和全局特徵表示。
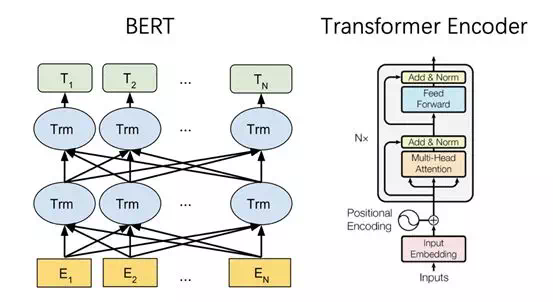
\BERT 網絡結構如下所示,BERT 與 Transformer 的 Encoder 網絡結構完全相同。假設 Embedding 向量的維度是,輸入序列包含 n 個token,則 BERT 模型一個layer 的輸入是一個的矩陣,而它的輸出也同樣是一個的矩陣,所以這樣 N 層 BERT layer 就可以很方便的首尾串聯起來。BERT 的 large model 使用了 N=24 層這樣的Transformer block。
目標函數
★ 1. Masked Language Model, MLM
MLM 是爲了訓練深度雙向語言表示向量,BERT 用了一個非常直接的方式,遮住句子裏某些單詞,讓編碼器預測這個單詞是什麼。具體操作流程如下圖示例:先按一個較小概率 mask 掉一些字,再對這些字利用語言模型由上下文做預測。

BERT 具體訓練方法爲:隨機遮住15%的單詞作爲訓練樣本。
其中80%用 masked token 來代替。
10%用隨機的一個詞來替換。
10%保持這個詞不變。
直觀上來說,只有15%的詞被遮蓋的原因是性能開銷,雙向編碼器比單向編碼器訓練要慢;選80% mask,20%具體單詞的原因是在 pretrain 的時候做了 mask,在特定任務微調如分類任務的時候,並不對輸入序列做 mask,會產生 gap,任務不一致;10%用隨機的一個詞來替換,10%保持這個詞不變的原因是讓編碼器不知道哪些詞需要預測的,哪些詞是錯誤的,因此被迫需要學習每一個 token 的表示向量,做了一個折中。

★ 2. Next Sentence Prediction
預訓練一個二分類的模型,來學習句子之間的關係。預測下一個句子的方法對學習句子之間關係很有幫助。
訓練方法:正樣本和負樣本比例是1:1,50%的句子是正樣本,即給定句子A和B,B是A的實際語境下一句;負樣本:在語料庫中隨機選擇的句子作爲B。通過兩個特定的 token[CLS]和[SEP]來串接兩個句子,該任務在[CLS]位置輸出預測。

輸入表示
Input:每個輸入序列的第一個 token [CLS]專門用來分類,直接利用此位置的最後輸出作爲分類任務的輸入 embedding。
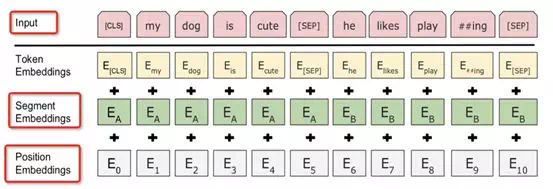
從直觀上來說,在預訓練時,[CLS]不參與 mask,因而該位置面向整個序列的所有position 做 attention,[CLS]位置的輸出足夠表達整個句子的信息,類似於一個global feature;而單詞 token 對應的 embedding 更關注該 token 的語義語法及上下文信息表達,類似於一個 local feature。
Position Embeddings: transformer 的 PositionEncoding 是通過 sin,cos 直接構造出來的,PositionEmbeddings 是通過模型學習到的 embedding 向量,最高支持512維。
Segment Embeddings:在預訓練的句對預測任務及問答、相似匹配等任務中,需要對前後句子做區分,將句對輸入同一序列,以特殊標記 [SEP] 分割,同時對第一個句子的每個 token 添加 Sentence A Embedding, 第二個句子添加 Sentence BEmbedding,實驗中讓EA =1, EB =0。
Fine-tune
針對不同任務,BERT 採用不同部分的輸出做預測,分類任務利用[CLS]位置的embedding,NER 任務利用每個 token 的輸出 embedding。
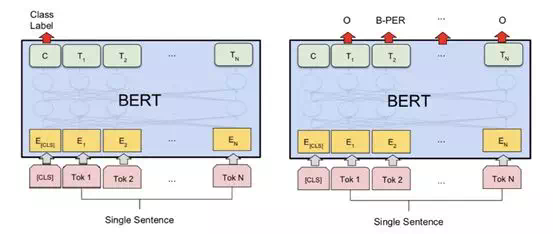
BERT的主要貢獻有以下幾個方面:
預訓練的有效性:這方面來說 BERT 改變了遊戲規則,是因爲相比設計複雜巧妙的網絡結構,在海量無監督數據上預訓練得到的BERT語言表示+少量訓練數據微調的簡單網絡模型的實驗結果取得了很大的優勢。
網絡深度:基於 DNN 語言模型 (NNLM,CBOW等) 獲取詞向量的表示已經在 NLP領域獲得很大成功,而 BERT 預訓練網絡基於 Transformer 的 Encoder,可以做的很深。
雙向語言模型:在 BERT 之前,ELMo 和 GPT 的主要侷限在於標準語言模型是單向的,GPT 使用 Transformer 的 Decoder 結構,只考慮了上文的信息。ELMo 從左往右的語言模型和從右往左的語言模型其實是獨立開來訓練的,共享 embedding,將兩個方向的 LSTM 拼接並不能真正表示上下文,其本質仍是單向的,且多層 LSTM難訓練。
目標函數:對比語言模型任務只做預測下一個位置的單詞,想要訓練包含更多信息的語言模型,就需要讓語言模型完成更復雜的任務,BERT 主要完成完形填空和句對預測的任務,即兩個 loss:一個是 Masked Language Model,另一個是 Next Sentence Prediction。
總結
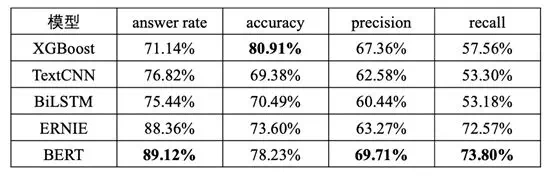
我們在做 NLU 意圖分類任務中實踐了以上主流模型,包括 Xgboost、TextCNN、LSTM、BERT 及 ERNIE 等,下邊是在前期模型調研階段,在選型測試數據上的對比實驗,BERT 模型表現出極大的優勢。
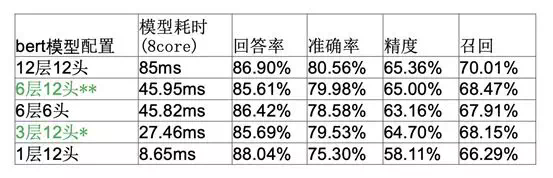
同時在我們部署上線的過程中,對 BERT 時耗做了測試,在壓測實驗數據上的測試結果供參考。針對我們的問答query:
(1 ) BERT layer 的層數與時耗基本成線性關係,多頭數目增加對時耗增加不明顯;
(2) 針對短文本 query 的意圖理解,更多依賴淺層語法語義特徵,因而 BERT 層數對模型準召影響較小;
(3) attention 多頭決定了可以從多少個角度理解 query,在我們的實驗裏降低多頭數比降低層數對準召的影響略大,而時耗無明顯降低。
圖像領域,Alexnet 打開了深度學習的大門,Resnet是圖像領域深度學習的殿堂標誌。
隨着Transformer, Bert 興起,網絡也在往12層,24層發展,得到了 SOTA. Bert 證明了在nlp領域,深層網絡的效果要優於淺層網絡。
自然語言領域,Transformer 打開了深層網絡的大門,BERT 也成爲了自然語言處理領域的殿堂標誌。
關於我們
我們是螞蟻金服財富對話算法團隊,致力於用最新的算法,做最好的模型,造就更智能的對話系統,摘取AI皇冠上的明珠,歡迎討論、轉發。團隊最近正在大力招聘NLP、推薦、用戶畫像方面的算法專家(P6-P9),歡迎聯繫:
shiming.xsm@antfin.com。
參考:
Kim Y. Convolutional neural networks for sentence classification[J]. arXivpreprint arXiv:1408.5882, 2014.
Hochreiter S, Schmidhuber J. LSTM can solve hard long time lagproblems[C]//Advances in neural information processing systems. 1997: 473-479.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all youneed[C]//Advances in neural information processing systems. 2017: 5998-6008.
Chen Q, Zhu X, Ling Z, et al. Enhanced lstm for natural languageinference[J]. arXiv preprint arXiv:1609.06038, 2016.
Peters M E, Neumann M, Iyyer M, et al. Deep contextualized wordrepresentations[J]. arXiv preprint arXiv:1802.05365, 2018.
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectionaltransformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018.