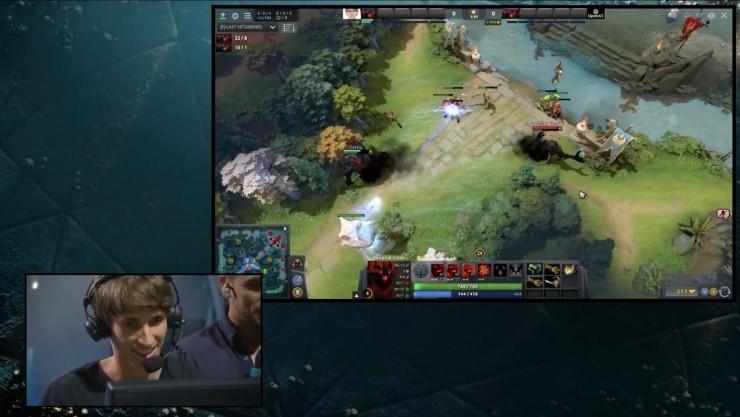
在8月12日,埃隆·馬斯克旗下旨在研究通用人工智能解決方案的公司OpenAI,所訓練的一款人工智能算法在著名的電子競技遊戲Dota2國際邀請賽The International中,參與了1V1比賽環節,並壓倒性的擊敗了頂級電子競技選手Dendi。
在alphago擊敗了柯潔以後,Deepmind多次公開表達了希望準備要去嘗試挑戰星際爭霸等電子競技項目,目前Deepmind確實也聯合暴雪公司在開展這項嘗試。因爲相比圍棋這種完全信息靜態博弈遊戲(即雙方都能獲得局面的所有信息,下棋異步),電子競技遊戲具備非完全信息屬性(雙方只掌握視野裏的部分信息),而且競技過程是實時動態進行的。其規則和特徵複雜度遠超圍棋,因此對人工智能的局面評估、決策能力要求顯著更高。另外,相比圍棋這種高度抽象的遊戲(只有落子一個動作),電子競技遊戲性質上更類似人類現實世界對抗/戰爭的簡化模擬,涉及了大量資源調配、部隊構成選擇、擴張策略、攻防對抗等複雜但具有現實意義的博弈,如能在電子競技對抗中取得劃時代的里程碑,則代表了人工智能邁向通用化又進了一大步。
這就是爲何Deepmind、OpenAI等頂尖人工智能公司都不約而同希望挑戰電子競技的根本原因,但大家沒想到的是,人工智能這麼快就在電子競技界取得了成功。
由於目前OpenAI尚未公佈其Dota2人工智能的設計細節,接下來我們通過分析和推測,力圖揭祕其背後的奧祕所在。
背景知識:Dota 2遊戲規則
Dota 2是一款類似於大衆熟知的王者榮耀式的5V5競技遊戲,每邊分別由5位玩家選擇一名英雄角色,目標以爲守護己方遠古遺蹟並摧毀敵方遠古遺蹟,通過提升等級、賺取金錢、購買裝備和擊殺對方英雄等諸多競技手段。
這次OpenAI選擇了挑戰較爲簡單的1V1挑戰,即OpenAI僅控制1名英雄,和頂級電子競技選手Dendi操縱的1名英雄進行對抗。
比賽中,採取dota 2「一塔兩殺」的規則,即雙方玩家只允許出現在中路,任意一方摧毀對方中路首個防禦塔,或者擊殺對方英雄兩次則取得勝利。遊戲中,每隔30秒雙方會獲得一波電腦控制的較弱部隊進入前線互相攻擊,玩家殺死這些小兵可以獲得金幣,金幣用於購買裝備物品以強化英雄能力,同時消滅對方部隊可獲取到經驗,經驗獲取到一定程度則可提升英雄等級,使得英雄能力更強,並獲得技能點升級新的技能。同時雙方各自還有一個初期威力強大的防禦塔在身後,因此雙方一般的對抗策略是儘量控制兵線在靠近己方防禦塔的地方,同時努力殺死對方小兵(正補)並防止對手這樣做(反補),獲取經驗和金幣後升級技能,並試圖通過攻擊和技能擊殺對方或摧毀對方防禦塔。
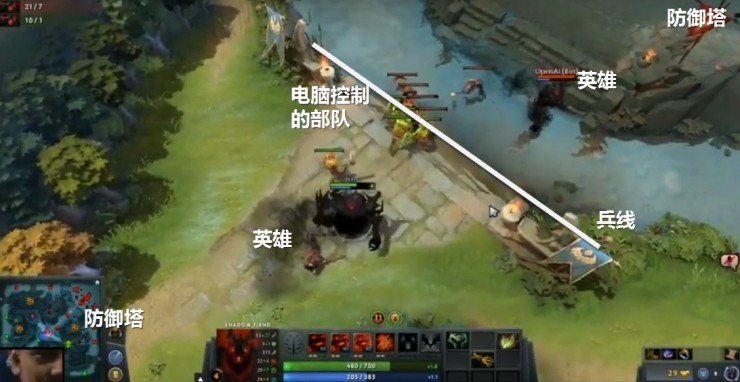
OpenAI的決策空間
上述是dota 2 1v1競技的簡單介紹,以供不瞭解dota 2的讀者有個初步印象,接下來我們來分析一下在dota 2 1v1競技中的決策空間及決策連續性這兩個問題,這是與alphago完全不一樣的存在,也是人工智能+電子競技有趣的地方。
決策空間
相比圍棋只有一個落子動作(選擇一個空位下子),dota 2 1v1中的決策空間相對非常複雜,玩家每分每秒需要在以下的動作中做出決策:
移動:移動英雄到一個特定的位置;
攻擊:控制英雄攻擊一個特定的目標(包括對方英雄);
正補:當對方小兵瀕死時,做出最後一擊殺死小兵以獲得金錢;
反補:同理當我方小兵瀕死時,做出最後一擊殺死小兵防止對方獲得金錢,並減少對方獲得的經驗值;
施法:使用英雄主動技能攻擊一個特定的目標;
取消攻擊/施法:英雄攻擊/施法前有一個短暫的硬直動作,在攻擊/施法動作真正做出前取消,從而達到誘騙對方的目的;
兵線控制:每隔30秒雙方會獲得一波電腦控制的小兵,通過攻擊對方英雄激活對方小兵仇恨從而引起小兵跑來攻擊自己英雄,或者用自己英雄的身體阻攔己方小兵前進,從而達到控制兵線靠近己方防禦塔,獲得競技優勢;
購買物品:用獲得的金錢在超過100種不同價格的物品中購買需要的裝備或消耗品;
使用物品:使用血瓶等消耗品補充自身;
當然,上述只是列舉出了比較重要的戰術動作,在實際競技過程中還有大量的如取消攻擊後搖、放風箏、控符、技能組合等高級動作。
決策連續性
圍棋是一個典型的異步競技遊戲,選手在做出每一個決策前具有充分的決策時間,是典型的馬爾科夫過程,但dota 2是一款實時競技遊戲,選手需要動態做出實時決策,這點是dota 2和圍棋的另外一個不同。
那麼OpenAI是怎麼解決連續決策問題的?目前OpenAI尚未公佈他們dota人工智能的細節。在這個問題上,OpenAI很有可能是通過考慮人類選手的決策效率,將決策過程離散化。Dota 2頂級選手的APM(action per minute,每分鐘做出的動作)可達到200以上,衆所周知人來大腦的反應速度是有極限的,一般頂級電競選手在反應速度上都有異於常人的天賦,如果按比賽中觀測到的APM來算,人類的極限可能在1秒鐘做出4到5個動作決策,因此OpenAI如果每隔0.2秒做出一個動作決策的話,就能有超越人類的表現。
因此我這部分的猜測是,OpenAI很可能選擇了200ms以內的某個值,在決策效率(更快的反應速度)和決策深度中取得了平衡,將dota 2 1v1比賽轉變爲類似圍棋的馬爾科夫決策過程。
OpenAI算法猜測:先驗知識+增強學習
目前OpenAI對他們dota人工智能算法的細節披露相當有限,只是初步表示了他們並未使用任何模仿學習(Imitation Learning)或者類似於alphago的樹搜索技術,純粹使用了self-play即俗稱 「左右互搏」的增強學習(reinforcement learning)方式訓練。模仿學習是一種有監督的機器學習方法,如alphago最初的落子器就是通過圍棋對戰平臺KGS獲得的人類選手圍棋對弈棋局訓練出來的。而OpenAI並沒有使用這種方法,可能主要原因還是較難獲得dota 2 1v1的大量對局數據,由於dota 2中有100多個英雄角色可選擇,每個英雄的屬性和技能均不一樣,意味着要對每個英雄做優化訓練,如OpenAI在本次The International賽事中,只會使用一名英雄角色Shadow Field(影魔),從人類對局中獲得海量(如10萬局以上)高水平Shadow Field的1v1對局錄像數據其實並不容易。
使用增強學習去令機器學會玩一款遊戲,我們不禁馬上聯想起谷歌DeepMind使用RL學習來玩打磚塊的經典案例。DeepMind模型僅使用像素作爲輸入,沒有任何先驗知識來輔助AI進行學習,算法Agent通過和環境S的交互,一開始選擇隨機動作A(向左還是向右移動滑板,動多少),並得到遊戲分數的變化作爲獎勵,然後Agent繼續如此玩下去,遊戲結束後Agent得到最後遊戲總分R,按照這種方式不斷讓Agent玩N局遊戲,可以得到了一系列訓練樣本(S,A,R),通過訓練一個神經網絡去預測在狀態S下,做動作A可能最後得到R,這樣接下來Agent不再隨機做出決策A,而是根據這個函數去玩,經過不斷的迭代,Agent將逐漸掌握玩打磚塊的訣竅,全程不需要人工制定任何的腳本規則。
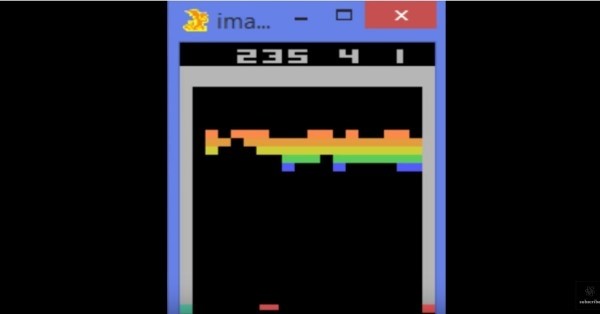
但是,在dota 2之中,或許很難採取類似學習打磚塊那樣從隨機行動開始的「大智若愚」方式去做增強學習,因爲對於打磚塊而言,每次動作A對於得分R的影響都是明確可量化的,但在dota 2中,這將會是一個非常長的鏈條。如以基本動作「補刀」爲例:
補刀即對方小兵瀕死時,控制英雄做出最後一擊殺死小兵獲得金錢,不是己方英雄親自殺死小兵不會獲得金錢。如果從隨機行動開始,即AI胡亂攻擊隨機的目標,Agent要聯繫起補刀行爲和最終勝利之間的關聯是很困難的:補刀行爲——小兵死亡——獲得額外金錢——用金錢購買正確的物品——正確的物品增強英雄能力——提升獲勝概率,完全不借助外界先驗知識,僅通過模擬兩個Agent「左右互搏」,從隨機動作開始去做增強學習,其收斂速度會異常的慢,很可能哪怕模擬幾百萬局都不見得能學會「補刀」這個基本動作,但補刀僅僅是dota這個遊戲入門的開始。
然而,根據OpenAI宣稱,他們僅僅用了兩週就完成了算法的訓練,或許這裏基本可以肯定,OpenAI使用了外界先驗知識。
實際上,Dota 2遊戲的開發商VALVE有一個dota 2機器人腳本框架,這個腳本框架下的機器人會熟練做出各種dota的基本動作,如補刀、釋放技能、攔兵、追殺、按照腳本購買物品等,部分如補刀等依靠反應速度的動作可以展現得非常難纏。只不過機器人動作的執行非常機械,主要由於預設腳本的設定難以應對信息萬變的實際競技,使得機器人總體水平根本無法接近一般玩家,更別說跟職業頂級玩家相比了。
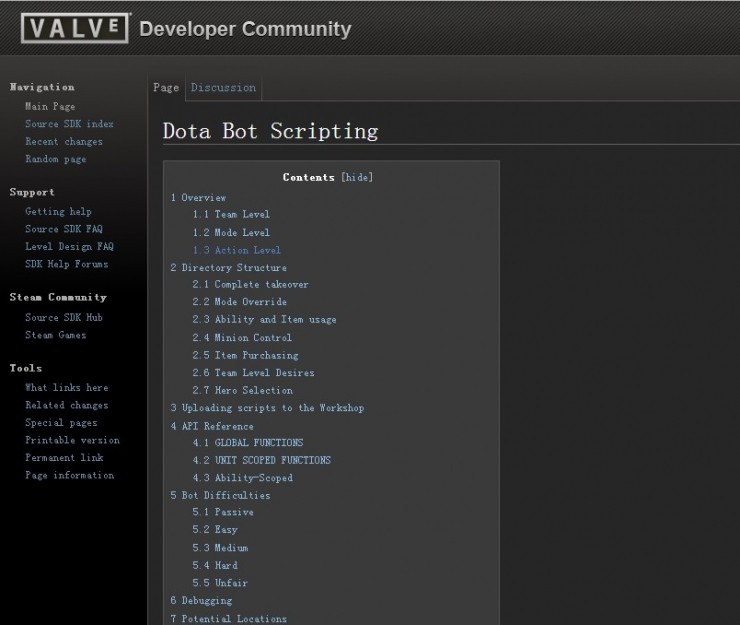
腳本機器人的優勢是戰術動作的執行,如上述增強學習很難馬上學會的「補刀」動作腳本機器人天生就會,屬於先驗知識,而且可以憑藉無反應時間和對目標血量和攻擊力的精確計算做得非常完美,缺點在於行動決策弱智。這樣如果祭出「組合拳」,使用腳本機器人執行基本戰術動作,通過增強學習訓練的神經網絡負責進行決策,就像《射鵰英雄傳》中,武功高強但雙目失明的梅超風騎在郭靖身上,長短互補一舉擊敗衆多高手那樣,豈不完美?
我想OpenAI很可能也確實是這樣做的,首先優化腳本機器人,將原子化的戰術動作A的腳本做得盡善盡美,充分發揮機器的微操優勢;同時通過增強學習訓練一個神經網絡,計算目前局勢S下(包括場面小兵和雙方英雄的狀態和站位、技能CD和魔法值情況等),執行那個戰術動作A得到的預期最終reward最高,即A=P(Si),並且在較短的離散空間內,比如200ms不斷進行決策並通過腳本執行動作A,最終使得OpenAI在大局觀和微操上都取得盡善盡美。當然,由於OpenAI自身還沒公佈算法細節,上述方法只是一個最有可能的猜測,通過先驗知識+增強學習獲得一個單挑能力很強的Solo智能。
如果這個猜測正確的話,那麼OpenAI在dota 2中通過1v1方式擊敗頂級職業選手這事情,遠遠沒有alphago此前取得的成就來得困難。因爲OpenAI在本次比賽中的表現,充其量等於訓練了一個類似alphago落子器那樣的應用而已。
而真正的挑戰,在於Dota 2的5V5對抗中。
展望
目前,OpenAI通過增強學習,訓練出了一個單挑solo能力非常強悍的算法,但是不得不說這個算法離Dota 2的5V5對抗中取勝還有非常大的距離。
在Dota 2的5V5對抗中,每方的5名玩家需要在英雄類型的合理搭配上、進攻策略上(如是速攻還是拖後期)、資源分配上(遊戲中獲得的金幣根據局面購買何種物品)、局部戰術等諸多因素上均保持順暢溝通、並緊密配合才能取得對抗的勝利,每場比賽通常要大約進行30分鐘以上,其過程的隨機性非常強。
因此可見,OpenAI要在5v5中取得對人類的勝利,遠遠不是用1v1算法控制5個角色這麼簡單,5個在區域戰場上單挑無敵的勇夫,並不意味着最終的勝利,接下來OpenAI的任務,就是讓他們不要成爲彼此「豬一樣的隊友」,而團隊合作、對局面的宏觀決策纔是真正具有挑戰意義的地方,同時也是人工智能從alphago這種機械性很強的專用智能,逐漸邁向通用智能的嘗試。而OpenAI團隊目前已經表示,他們正在準備向dota 2 5v5中全面擊敗最強人類玩家戰隊的目標進發,並計劃在明年接受這個挑戰。
今天Dota 2 1v1的一小步,明年5v5的一大步,讓我們密切期待!
按:OpenAI的人工智能進軍DOTA2:影魔solo輕鬆擊敗頂級選手Dendi和Sumail!(附賽況視頻&現場採訪)