雷鋒網(公衆號:雷鋒網)按:本文作者陳村,劍橋大學自然語言處理(NLP)組, 現爲機器學習語義分析工程師。
Google Translate作爲久負盛名的機器翻譯產品,推出10年以來,支持103種語言,一直作爲業界的標杆。
而在前不久,Google官方對翻譯進行一次脫胎換骨的升級——將全產品線的翻譯算法換成了基於神經網絡的機器翻譯系統(Nueural Machine Translation,NMT)。從Google官方發表的博文[1]和技術報告[2]中,我們有機會一窺究竟,這個全新的系統到底有什麼神奇的地方?筆者借這篇文章,幫大家梳理一下機器翻譯的發展歷程,以及Google這次新系統的一些亮點。
| 機器翻譯的發展史
機器翻譯,即把某一種源語言(比如英文)翻譯到最恰當的目標語言(比如中文)。
還在幾年前,機器翻譯界的主流方法都是Phrased-Based Machine Translation (PBMT),Google翻譯使用的也是基於這個框架的算法。所謂Phrased-based,即翻譯的最小單位由任意連續的詞(Word)組合成爲的詞組(Phrase),比如下圖中的「北風呼嘯」。
PBMT是怎麼把一句英文翻譯成中文的呢?
首先,算法會把句子打散成一個個由詞語組成的詞組(中文需要進行額外的分詞),如圖中(1)所示;
然後,預先訓練好的統計模型會對於每個詞組,找到另一種語言中最佳對應的詞組,如圖中(2)所示;
最後,需要將這樣「硬生生」翻譯過來的目標語言詞組,通過重新排序,讓它看起來儘量通順以及符合目標語言的語法,如圖中(3)所示。
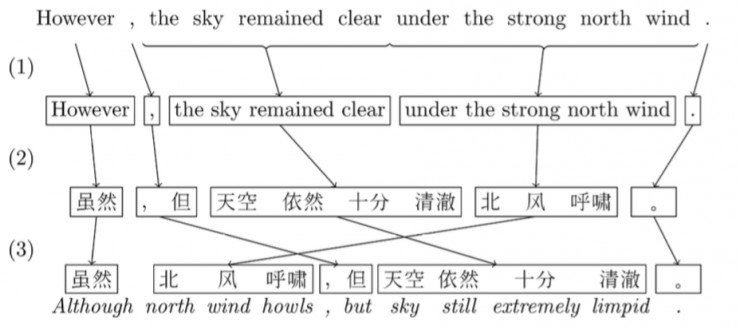
圖片出處:Lopez, A. (2008). Statistical machine translation. ACM Computing Surveys, 40(3), 1–49.
傳統的PBMT的方法,一直被稱爲NLP(Natural Language Processing,自然語言處理)領域的終極任務之一。因爲整個翻譯過程中,需要依次調用其他各種更底層的NLP算法,比如中文分詞、詞性標註、句法結構等等,最終才能生成正確的翻譯。這樣像流水線一樣的翻譯方法,一環套一環,中間任意一個環節有了錯誤,這樣的錯誤會一直傳播下去(error propagation),導致最終的結果出錯。
因此,即使單個系統準確率可以高達95%,但是整個翻譯流程走下來,最終累積的錯誤可能就不可接受了。
深度學習這幾年火了之後,機器翻譯一直是深度學習在NLP領域裏成果最爲卓越的方向之一。深度神經網絡提倡的是end-to-end learning,即跳過中間各種子NLP步驟,用深層的網絡結構去直接學習擬合源語言到目標語言的概率。
2014年,Cho et. al [3]和Sutskever et al. [4] 提出了Encoder-Decoder架構的神經網絡機器翻譯系統。如下圖所示:
首先把源語言一個詞一個詞地輸入Encoder,Encoder利用訓練好的神經網絡參數,把整個輸入序列的信息存在一個隱層向量h中;h這個隱層,可以理解爲包含了所有對輸入源語言的描述;然後再由Decoder,利用訓練好的神經網絡參數,從隱層h中讀取參數,再一個詞一個詞地輸出目標語言。
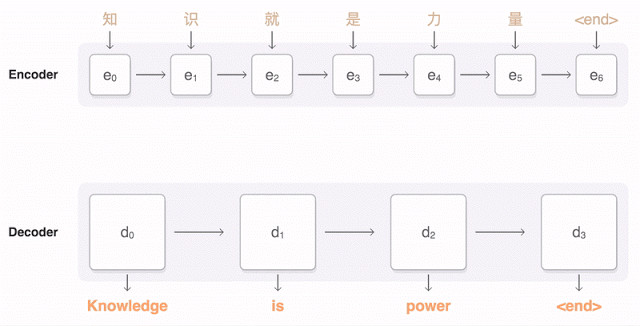
NMT這樣的過程直接學習源語言到目標語言,省去了訓練一大堆複雜NLP子系統的依賴,依靠大量的訓練數據(平行語聊庫,比如同一本書的中文和英文版本),直接讓深度神經網絡去學習擬合。熟悉深度學習的朋友可能會意識到,這樣的方法一個極大的優勢就是省去了很多人工特徵選擇和調參的步驟。聽說前兩年,有個做神經網絡圖像處理的教授,在不太瞭解NLP的基礎上,硬生生地搭建了一套可以匹敵傳統PBMT的機器翻譯系統,後者可是十幾年來多少奮戰在第一線的NLP同志一磚一瓦壘起來的啊。而且,相比於傳統PBMT一個詞組一個詞組的獨立翻譯,NMT這樣end-to-end翻譯出來的語言更加自然流暢。
2015年,Yoshua Bengio團隊進一步,加入了Attention的概念。稍微區別於上面描述的Encoder-Decoder方法,基於Attention的Decoder邏輯在從隱層h中讀取信息輸出的時候,會根據現在正在翻譯的是哪個詞,自動調整對隱層的讀入權重。即翻譯每個詞的時候,會更加有側重點,這樣也模擬了傳統翻譯中詞組對詞組的對應翻譯的過程。Attention模塊其實也就是一個小型神經網絡,嵌入在Encoder-decoder之間的,跟着整個神經網絡訓練的時候一起優化訓練出來的。
Bengio團隊的這個工作也奠定了後序很多NMT商業系統的基礎,也包括Google這次發佈的GNMT。
| Google GNMT
Google這次在算法上、尤其是工程上對學術界的NMT方法提出了多項改進,才促成了這次Google NMT系統的上線。
學術上的NMT雖然取得了豐碩的成果,但在實際的產品中NMT的效果卻比不上PBMT。究其原因Google在技術報告[2]中總結了三點:
1、訓練和預測的速度太慢。
要獲得更好的模擬效果,就要用更深層的神經網絡來擬合參數(下面會提到,GNMT用了8層的Stack LSTM來做Encoder)。這麼複雜的神經網絡在預測的時候就要耗費大量的資源,遠遠慢於PBMT的系統。並且在訓練的時候擬合這麼大規模的預料,可能要很久很久才能訓練一次,這樣不利於快速迭代改進調整模型參數。
2、NMT在處理不常見的詞語的時候比較薄弱。
比如一些數字、或者專有名詞。在傳統PBMT系統中,可以簡單地把這些詞原封不動的copy到翻譯句子中;但是在NMT中,這樣的操作就無法有效的進行。
3、有時候NMT無法對輸入源句子的所有部分進行翻譯,這樣會造成很奇怪的結果。
Google NMT的主要神經網絡架構圖如下:
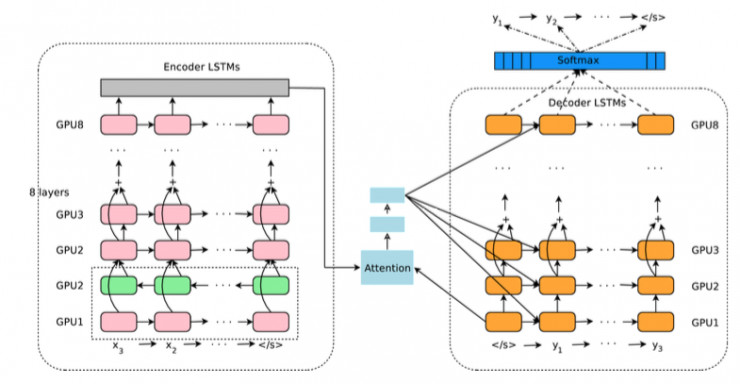
仔細看,其實還是帶Attenion的Encoder-Decoder邏輯。Encoder是由8層LSTM組成,最下面兩層是一個雙向LSTM,可以從前到後以及從後往前理解一遍輸入的源語言輸入。中間的藍色模塊就是Attention模塊,負責對Encoder的邏輯進行加權平均輸出到Decoder層。Decoder模塊也是一個8層的LSTM,最終連接到Softmax層,一個詞一個詞輸出最終的目標語言詞語的概率分佈。
算法上,論文中還提到了一些創新點。包括引入Wordpiece來對單詞進行更細粒度的建模,來解決上面提到的不常見詞語的問題;以及在Decoding結束之後,搜索最佳輸出序列的時候,引入coverage penalty的概念,來鼓勵Decoder輸出更加完整的翻譯句子,以解決有時候NMT有時候無法完整的翻譯整句的情況。
工程上,報告裏面着重談到了幾個性能優化的重點:
引入Risidual Connection
8層的LSTM堆疊起來,大大增加了神經網絡的表達能力,在海量的數據下可以獲得更好的模型效果。不過這樣的堆疊會直接導致模型太龐大不可訓練,在梯度反向傳播的時候,很容易出現梯度彌散或梯度爆炸的問題。過去的研究證明[5],Residual Connection的方式,直接去學習殘差可能會帶來更好的效果,避免了深度網絡中反向傳播中出現的梯度反向傳播可能會發生的問題。在上面的Google NMT架構圖中,從倒數第三層開始都會引入Residual Connection。
大量的並行優化
與此同時,在工程上Google也進行了非常多的優化,來減少訓練和實時翻譯時候的延遲問題。比如訓練數據的時候,數據會分成n等份,交給不同的GPU去異步訓練,然後再彙總到統一的參數服務器;同時,Encoder和Decoder的不同層的LSTM會在不同的GPU上運行,因爲更上一層的LSTM不必等到下一層的神經網絡完全計算完畢再開始工作;即使對於最後的Softmax輸出層,如果最後輸出詞的維度太大,也會劃分到不同的GPU上並行處理。可謂不放過絲毫並行的機會。
底層基礎計算平臺的支持。Google NMT採用了自家的Tensorflow深度學習框架,並運行在Google專門爲深度學習打造的TPU(Tensor Processing Unit)上,當年的AlphaGo也是由TPU提供支持。在對於模型參數的計算上,也大量應用了Quantized計算的技術:
由於神經網絡參數涉及大量的耗時的浮點數運算,通過Quantization的方法,將模型參數由浮點數類型轉換到一個更低精度(比如8bit),雖然會有一些精度的損失,但是可以大大減少計算量以及最終訓練模型的體積。
從軟件框架到定製硬件,相互配合,追求最極致的性能。在這篇報告裏,有着長長的作者列表,最後赫然列着Google工程架構大神Jeffrey Dean的名字,他是當年一手創造了Map Reduce、Big Table等產品的Google奠基者之一。
| 寫在後面
Google這次的論文,基本框架仍然是帶Attention模塊的Encoder-Decoder。而且國內廠商,比如百度和搜狗,也發佈了類似的神經網絡機器翻譯系統。百度早在去年,就發佈「工業界第一款NMT系統」。不過,Google畢竟是機器翻譯界的標杆,這次披露的論文也揭示了很多他們爲了大規模商業化做出的努力,因此在業界引起了不小的震動。
注:[1]A Neural Network for Machine Translation, at Production Scale
[2] Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., et al. (2016, September 26). Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
[3] Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014).
[4] Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS 2014).
[5] He, K., Zhang, X., Ren, S., & Sun, J. (1512). Deep residual learning for image recognition. arXiv preprint (2015).
