雷鋒網AI科技評論按:在剛剛閉幕的ICLR2017上,紐約大學神經學、數學、心理學教授Eero Simoncelli作爲特邀嘉賓分享了他在機器表徵、人類感知方面的研究成果。以下爲現場視頻及雷鋒網全文聽譯。


附原視頻:
(Eero走上臺準備開始演講)
首先謝謝,謝謝剛纔對我的介紹,感謝大會主席Yann和Yoshua,以及評委會主席Hugo、Tara、Oriol邀請我參加,很榮幸可以參加這次會議。
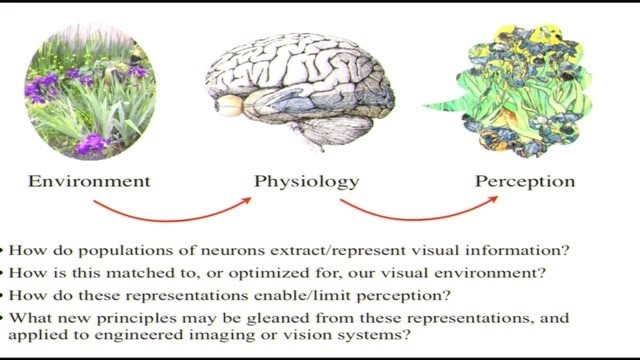
我們小組的工作主要是在理解視覺和其它各種感官表徵上,研究這些表徵是如何建立起來的、如何組織信息、維持和展現關於環境的信息。我不僅好奇神經細胞是如何做到的、是如何把神經學表徵與視覺環境對應起來的,我還好奇這些表徵會如何形成或者限制我們的理解。最後,當我們瞭解了這些表徵的規律以後,如何利用這些規律設計優秀的系統,給其它圖像處理和計算機視覺之類的應用帶來方便。我下面要做的是,帶大家回顧一下(視覺表徵)這方面研究的發展歷程。其實,深度卷積網絡也同時在快速發展,取得了不少成果,過程中我也會給大家講一下過程中兩者間有哪些同步的和不同的地方。
人是如何「看到」的
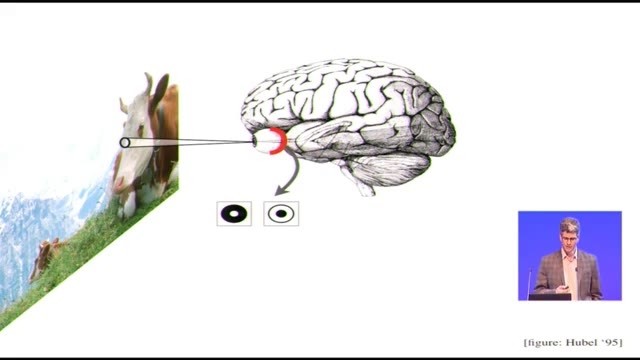
OK。我幻燈片第一頁是一張牛的照片,這張照片是我很多年前在瑞士拍的。看見圖的過程是這樣的:
光線進入你的眼睛,照到你的視網膜上,視網膜上有細胞,它們可以觀察到圖片上的很小的區域;
對這些區域進行處理的時候會用到一個視網膜內的網絡迴路,從大概5百萬個視錐細胞開始,它們能把光照轉換成電信號;
這些信號接下來會經過迴路轉換成爲大約一百萬箇中樞神經細胞的輸出;
這些神經細胞的軸突形成了視覺細胞的線纜,然後從你眼睛的後側走出來。當然了,每隻眼睛後面都會有一根這樣的線纜。所以,可以這樣講,有大概5百萬個感官單元可以形成像素,像素化的測量會轉換到一百萬條纖維組成的線纜中,然後到達你的大腦。
經過這個過程,信息會被被轉換、總結,會與其它感官輸入的信息進行綜合,與你的內在狀態的信息進行綜合,「內在狀態」是指像記憶、意象、動作以及其它類似這種大腦產生的東西。通過這一切就形成了「你看到了」的感覺,以這個例子來講就是你看到了這頭牛。
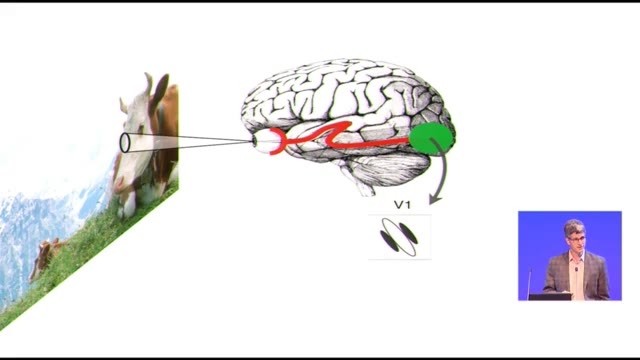
那麼,信息其實會被傳到大腦的後側去,線路看起來挺奇怪的,線纜會大老遠地把視覺信息傳到後面去。人的主要視覺皮層就在這裏,哺乳動物最大的皮層區域之一,當然也是靈長目裏最大的之一。這裏的神經細胞我們幾十年前就認識了,感謝上世紀五六十年代Hugo和Wessel的開創性工作,這裏的細胞有方向選擇性。這些神經細胞,我們描述它們時候的常用詞叫「感受野」,這是一種對神經細胞處理的內容的線性近似,它是一個加權函數,看起來差不多像圖示(雷鋒網注:上方圖中V1)的這樣,大家中如果有做視覺方面的可以看作是Gabor函數。這種加權函數就給細胞賦予了局部的方向選擇性。
所以方向性是這些細胞的決定性特性,這是所有人對這些V1初級皮層細胞的看法。實際上用簡單的動畫來表達V1細胞做的事情的話,就是測量環境中局部的微小方向,小條、小塊,它要測出其中佔支配地位的方向是什麼。它會把這個結果告訴大腦的其它部分。
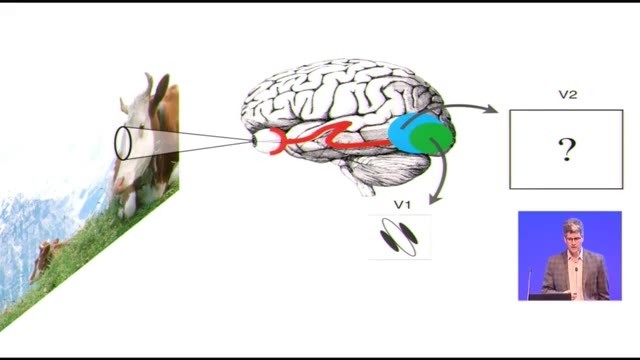
然後會發生什麼呢?V1會有很多輸出到V2,V2也是很大的一塊區域,人和猴子的V2區域可能還要比V1大一點。就像圖裏這樣,它差不多在V1的邊上,包着V1。然而事實是這樣的,即便人們幾十年前知道V2神經細胞的存在了,Hugo和Wessel就記錄過V2細胞,人們還是花了很長時間才弄明白V2到底是做什麼的。既然V2細胞接收V1細胞的輸出,所以很自然地可以想象V2會對V1細胞的局部方向做一些合併。
對V2細胞功能的猜想

這就讓我們回想起以前Hugo和Wessel那個時代所想的理論,你會覺得這些計算機視覺範式的關鍵點都是找到圖像中一組一組的邊緣,然後把這些邊緣補全連接起來,就找到了界線和輪廓,接着就用它們分離對象,確定哪些是前景哪些是背景,最後就可以做對象識別。

想到這種範式是非常自然的,你可能會覺得這些V2細胞就在執行這個流程的第一步,沿着界線(雷鋒網注找:圖中紅色虛線)找到一段一段的邊緣並且把他們拼接起來。
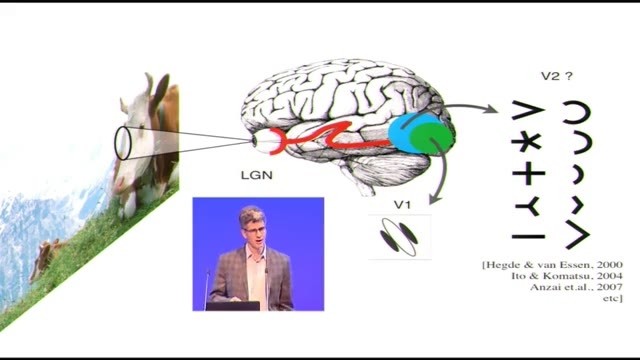
但是讓人們嘗試記錄V2細胞的輸出,嘗試測量V2細胞對角度、曲線、或者各種局部方向的組合的選擇性的時候,比如這張圖是Newston測試中用到的刺激圖案,這種實驗只取得了非常有限的成果。在這個例子裏, V2細胞中只有很少的一部分似乎對這種刺激做出了明顯的反應,而對很多的V2細胞而言,這些不同的局部方向組合都不能引起任何反應,即便有反應的細胞也只是微弱的反應。
所以大概到了2012年,我們還缺少對V2功能性中的任何協同作用的發現,尤其是其中運用V1的輸出來讓V2的輸出產生區別的那些功能。我覺得這事挺神奇的,有數不清的神經組織參與着視覺的形成,顯然這是很重要的一件事情,可是花了這麼多資源以後,如果V2只是在模仿V1所做的事情,進化成這樣也挺奇怪的。剛纔忘了說大多數的V2細胞確實是對方向有選擇性的,部分地、鬆散地具有方向選擇性。
那麼這個問題變得很神祕了,這些細胞、這些組織到底是用來做什麼的?我覺得,我得到自己的答案是通過重新審視這個假設,計算機視覺、實際上所有的視覺研究在一開始都是這樣想的,那就是認爲世界是由有邊界的物體組成的,我們會認爲沿着這些邊界來把不同的東西分開是最基本的一步。
這是一個紋理的世界

可是當你自己看這個場景的時候,畫面中的大部分內容其實是並不是邊界,而是許多成塊的、近似的、幾乎均勻分佈的組織。(雷鋒網(公衆號:雷鋒網)注:演講花絮,見動圖)爲什麼大家在笑?我升到上面去了,然後現在大家都在看我的後腦勺?

回到正題,當你看着這張圖片的時候,有種東西佔據了圖片裏的大部分面積,我們把它叫做「紋理」,視覺紋理。圖裏能看到這些草形成的斑塊,每一處的斑塊看起來很像,但是每一處又不會完全一樣,其中的不同的葉子有不同的長度、角度等等。其中有很多的方向,可能屏幕不是很清晰所以看得不是很明顯,但是如果你能仔細觀察的話,你的V1細胞可以對其中每棵草的方向做出不錯的響應。但是每一塊斑塊都是完全不同的草葉混在一起組成的。
如果你往上看一點,可以看到這塊岩石的正面,它看起不太一樣,方向特性有一些不一樣,但是你也可以測量它的局部方向,那裏顯示着的就是某種特定的組合。牛身上的毛也一樣,等等。所以實際上,我們的視覺世界裏充滿了紋理,可以說是被紋理統治的。我覺得有可能很多V2細胞就是用來處理紋理的。這只是個猜測,等一下我會給大家講解我做過的研究,看看能否證實這個猜測。
接下來我就不說更多生理學的東西了,我來說一說感知。前面這些都是一些介紹性的思考過程。因爲我知道,在我們的學術社區中,很多對分層級聯,或者說卷積算子的發展起到了推動作用的因素,其實是因爲人們粗略地覺得視覺系統就是這樣工作的。

所以,紋理無處不在,這裏是更多的例子,隨處都能看到。爲了能夠描述紋理,我們需要給紋理設計一個計算理論,這樣我們才能夠從感知和生理的角度去測試它,而且也才能夠建立用在機器學習系統中的算法和表徵。

那麼什麼是「紋理」呢,不嚴謹地說,紋理就一種同類的、具有重複性的圖像,各個部分都會出現同一類的東西、同樣的結構。Lettvin說過的這段話我覺得很好,把這個概念描述得很貼切、很直觀,是1976年的,
「我們可以這樣講,如果可見的物體不一樣,而且它們之間離得很遠,這就是形態;如果它們相似而且是聚在一起的,這就是紋理。一個人是一種形態,而人羣具有‘人’這樣的紋理;」這種說法真時髦,「一片葉子是一種形態,而樹冠具有葉子的紋理,等等。」
這個意思就是說,你把很多東西放在一起就成了紋理;如果你只有單獨一個東西,那就不是紋理。等一下我再給你們展示幾個例子來把這個問題講通。
所以,從算法角度建模和描述紋理的想法從上世紀60年代就有了,這些東西都是那個時候發生的,真是一個不錯的年代呢,對音樂來說也是。在這段時間,Julesz基本上自己提出了一個猜想,他覺得從人類感知和計算建模的角度,正確的思路應當是紋理可以用一組有限的統計特徵來表達。
他對此的解釋是,如果人的大腦會通過某種方式來測量和計算這些有限的特徵,那麼正確的聯繫和理解這個猜想的方式就是做預測,表達出來是這樣:「兩種具有同樣統計特徵的紋理」,他當時想的是n階的像素特徵,「如果特徵一樣,看起來就會一樣」。就是說,如果能夠發現人類大腦採用的表徵是什麼,那如果有任意兩張圖片的這些表徵是相同的,在人類大腦看來就會是一樣的。他指出的這種測試的方法論、這種紋理模型裏面蘊含了非常有力的東西,稍等馬上會講到。

Julesz列出了一個明確的目標,要用一種統計學模型來捕捉感知。另外還有一組非常重要的對測量過程的描述是:
首先不管表徵如何,測量方法都應當是靜態的,具有平移不變性——統計特徵就是從這裏來的,他要指的是整個圖像中內容的均值;
它還應當是通用的,同一組統計特徵對所有的紋理都可以起作用,每一種不同的紋理都會有不同的統計特徵,但如果你發現兩張圖片有相同的統計特徵,那它們應該要看起來一樣;
最後一點也既重要,又有一點巧妙,這個假設只在這個情況下才有意義,就是你需要儘量少的維度。
要在能夠達到目標的維度數目裏選擇最少的那一個,尤其是如果你研究的圖像尺寸不大,那就非常好理解。如果你的矩陣中有太多的統計特徵的話,最終你會給本來滿足統計特徵的圖像加上越來越多的限制,最後在這個組裏就不會剩下什麼了。這種情況下如果你從一張初始的圖像開始,然後你找到了另外一張統計特徵一樣的圖像,但這張圖像只是原來那張圖像平移後的一個副本,這種假設就不是很讓人喜歡了。所以表徵,或者統計特徵的維度儘可能少,就是很重要的一件事情。這是一種會讓紋理圖像的信息被減少、壓縮的,但仍能代表紋理特徵的總結性測量。
還有一件事情值得指出的是,儘管人們已經認爲生成性模型是解決視覺中和其它許多領域問題的非常重要的方法,但Julesz的表述只是一種分析性的表述,只有當你去測量這些統計特徵的時候才能發揮作用,這些屬性才能夠體現。這就給我們如何實際做測量留下了一些難題。

所以實際上Julesz在1962年那時,想了一些辦法來做這個測試,他當時用的是二進制顏色的圖像,只有黑色和白色,用到的圖像也是他手工繪製的。跟大家一樣,他對這些圖像做分析,試試看他的理論是不是對的。不過你不能只憑實驗就說一個理論是對的,從科學的角度來講這是不能夠證明理論的正確性的,具體到這裏,你沒辦法把所有的圖片都拿過來進行嘗試。所以你要反過來,找反例,找理論失敗的情況。
那麼他就開始找,他假設統計特徵的維度是2階,看看能否找到一組2階統計特徵相同、但是人類看起來不同的圖像,這樣就能說明模型是不成功的,然後就排除這個可能,繼續嘗試3階的。當他達到3階的時候,屏幕靠左下方顯示的這兩張就是他手工建立的圖片,它們具有相同的3階統計特徵。算法是,兩個兩個地取其中的像素,算出圖像中所有成對像素的積的平均數;然後三個三個地取像素,算出圖像中所有三個三個像素的積的平均數。這兩張圖片在這兩件事情上都是相等的,但是你能看出來兩張圖還是有一些不同的,就像是用不同的材料畫的。實際上人類確實也很擅長髮現這些材質上的區別,所以他就認爲自己的理論是不成立的,就放棄了。
用現代方法做特徵表徵

許多年以後,一個非常有天賦的博士生Javier Portilla加入了我的實驗室,我們開始討論有沒有更好的表徵紋理的方法。我們重新翻看了Julesz的想法,然後用簡化的現代方法、當然也是借鑑生理學的方法去執行。其中的關鍵點是,我們並沒有計算像素的統計特徵,而是思考大腦是如何進行測量的,其實Julesz當時也可以這麼做,我其實剛纔就說Hugo和Wessel在五六十年代就發現了V1細胞能代表內容的局部方向性,不過如果他真的做的話,他就需要一個複雜得多的算法,也就沒辦法做出這些例子了。
當時間到了90年代末的時候,我們已經有條件做這件事了,所以我和Javier對V1建立了一個非常簡單的模型,我只簡單講一下吧,對V1來說有兩種基本類型的細胞,簡單型和複雜型。簡單型細胞看起來像是線性濾波器後面跟了一個整流器,大家聽起來是不是覺得很耳熟;複雜型細胞長這樣,看起來像是簡單型細胞的混合,可以是平方或者半平方然後再混合正負號組合到一起。不過最終都要把這些結果池化,這裏也聽起來很熟悉,如果你們中也有人想對圖像使用深度網絡和卷積網絡的話。
我們用這兩種單元,但是跟典型的深度網絡結構不一樣,我們要做的是測量這些單元的輸出的局部統計特徵,當然了,先用這些單元對圖像進行卷積。我們用的濾波器也不是屏幕上顯示的這樣,我們會用到各種方向、各種大小的濾波器,實際上我們用的是一種叫做「可控金字塔」的多級表徵,它基本上可以把所有不同的大小和方向整理成一個完整的集合。所以我們做了所有這些卷積,我們有所有相應的輸出圖像,也可以稱作激活圖像。我們對它們做平方和半平方,我們對平方過的進行池化,然後我們對這些東西計算統計特徵。這裏我說到的統計特徵,我們基本上只用了相關性,要麼就是相關性,要麼是從相關性算出的。

我們對空間位置間、方向間、路徑間、大小間的相關性做了計算。我們把它們做成一個集合,最後得到的測量值數目有大概700個,精確數目應該是710,當我們把所有的測量都算到裏面的時候。這樣我們就有了一個可以處理任意圖片、最好是紋理圖片的模型,這個模型就會把圖片轉換成這個710個測量值。這些是統計特徵的測量,如果我們還要驗證Julesz的想法的話,就要想辦法生成具有相同統計特徵的圖片。
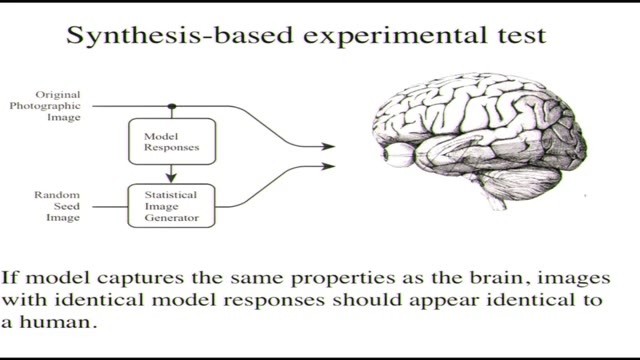
要做的事情和Julesz當時做的一樣,只不過我們現在可以用電腦來生成這些圖片。大概流程是,我們從一張初始照片開始,通過模型計算輸出,然後我們會用隨機的種子生成一張新圖片,讓生成的圖片擁有一樣的統計特徵。最後我們會把兩張圖片拿給人類看,看看是否會認爲是相同的,或者相似的,或者在某些觀看條件下是相同的,實際上這也是比較經常發生的情況。那麼這就是一種巡迴式的測試,而且只有當照片生成器能夠產生的變化足夠多的時候,這才能稱得上是一個好的測試,你需要對值的空間進行完善的探索,本質上需要探索模型的零空間,要探索模型捨棄了哪些東西,換個說法就是探索在模型看來相同的那些東西。
具體到做的方法上,你需要在這些模型施加的統計特徵限制下,做出一張具有最高凝聚力密度的圖像。另一件值得一提的事情是,能通過測試不代表就真的是一個好模型,原因剛纔我也說過,我們需要找到一個能夠儘量多地拋棄信息的模型,參數的數量就可以作爲信息多少的粗略參考。我們現在的模型只有710個輸出,而我們處理的圖像有從幾百到幾百萬像素都有,那這就是一個顯著的減少,我們丟棄了很多的信息。所以在我們看來,這個測試就挺好的了。
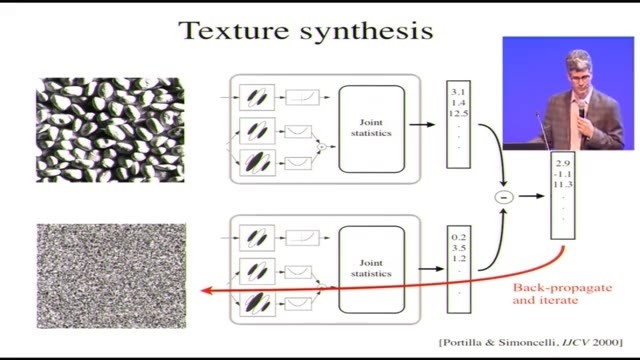
好的,下一步,我們是這麼做的,就像剛剛說的,我們從這樣一張圖片開始,計算出模型的輸出;然後下面這裏用白噪聲作爲種子(雷鋒網注:左側下方圖像爲原始白噪聲),計算模型輸出,它們不一樣,那就算出它們的差值,然後做反向傳播。要反向傳播的是響應的差值,在圖像空間做梯度下降,直到輸出變得一致。具體做法基本就是這樣。
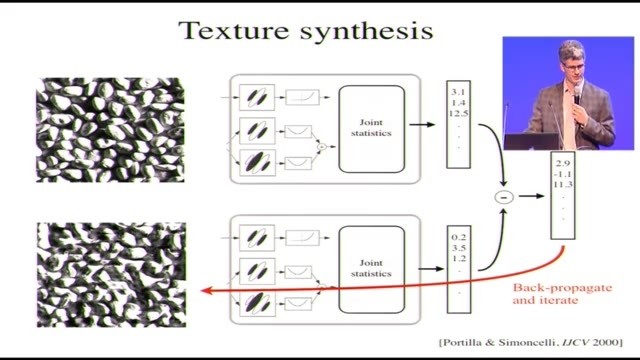
所以在這些做完以後,你得到了一張跟原來的紋理還挺像的圖片,某些情況下幾乎沒法跟本來的紋理分辨。(雷鋒網注:左側下方圖像爲最終生成的圖像)具體在這個例子裏,還是能看出來不完全一樣,不過如果你只是很快地看了一眼,不是用中央凹看,不是直視,而是目光盯着畫面右邊的地方的話,肯定是沒辦法區分的。嗯,中央凹的事情待會兒我們還會說到。
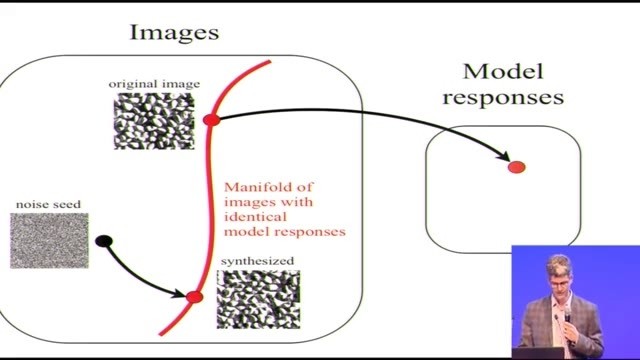
做個摘要的話,事情是這樣的,
我們從一張圖片開始,它是所有圖像組成的空間中的一個點
我們把它映射到模型輸出空間裏,這個由我們的模型表徵的空間要小一些
圖像空間裏會有一些多樣性,因爲這個模型不是線性的,所以在有多樣性的圖像空間裏,有很多圖像都會有一樣的模型響應。這種多樣性基本就是由於兩個空間的維數不同造成的,從一百萬維的空間到710維的空間,有,呃,九十九萬九千三百維的信息都丟失了
然後我們拿來這個噪音的種子,我們做的事情本質上是對它做投射,非線性投射,做一種梯度下降,直到我們來到了多樣性的界線上
這樣我們就得到了生成的圖片
這樣就用簡圖的方式說明了在高維空間到底發生了什麼,我們又要如何理解。
計算機也可以生成非常逼真的紋理了

這是另一組例子。效果很不錯,我直到今天都覺得很驚訝,這麼簡單的模型就能生成這樣有趣的視覺結構,這還僅僅是一個2階的模型而已,只有簡單的、差不多生物性的非線性,也沒有對特點、部分、物體等等做清晰具體的表徵。即便這樣,我們也能夠表徵出來這些有意思的內容。起碼當這些結果在99年和2000年的時候做出來的,我是很震驚的;今天可能就不怎麼震驚了,因爲我們用深度卷積網絡一直做的就是這樣的事情。也在發展壯大吧,差不多每天都有人能發現一種有趣的生成圖像或者變換圖像的方法。

它們也能夠給Julesz的擔心給一個正面的答覆,就是說當你把Julesz的反例圖像作爲輸入給到裏面的時候,它們也會輸出基本無法分辨的圖像。所以這樣也就通過了Julesz設計的測試。

不過我們也發現這個,有點讓人撓頭,如果你用深度卷積網絡做類似的生成,你會得到這樣的「騙人圖像」,它們是Clune和他的團隊在這篇2015年發表的論文裏描述的。他做的事情跟我一樣,從白噪音開始,用梯度下降的方法把它轉換到一個圖像識別器的分類裏面去。輸出的是這樣的圖像,它們看起來像噪音,跟它們本來應該屬於的那個分類看起來一點都不像。

另一個相關的結果,像這樣,通過調整一副圖像來達到一個目標分類。從原圖開始,比如這個校車,你想把它轉換到火雞的分類裏面,然後你得到的結果看起來還是像校車。就好像沒有對圖像做任何修改,起碼不是我們人類能看出來的修改。

但是如果你用我們的模型做的話,你會得到這樣的結果。比如這幾個例子,你從一張人臉的照片開始,你想把它轉換到一個目標中,不過我們的目標不是語言或者類別的名字,而是一些紋理樣本。我們從這個紋理上提取統計特徵,把原圖作爲一個起點,然後把它推到能夠滿足統計特徵的多樣性邊界上去,就會得到這樣的看起來像橄欖的圖,但是原來的主要圖像結構還是得到了保留,這是因爲這個模型具有同質性、平移不變性,它不關心總體結構,也不會對總體結構做任何限制,所以一部分結構就在投射過程後殘留了下來。
聲音也有紋理嗎?
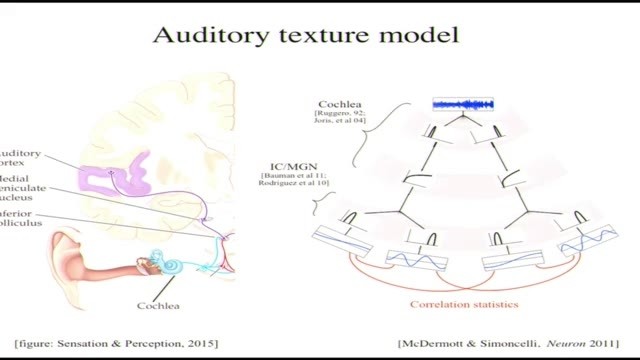
時間好像不太夠了,但我又不太想把最後一點東西跳過去。那我就講得快一點吧。不說那麼細了,我們團隊的另一個非常優秀的博士後Josh McDermott和我基本上想辦法做了一個類似的模型,它可以生成聲音的材質。
總體上可以這樣講,基本可以分成三個環節,就像圖裏這樣,第一環節是濾波,模仿的是耳蝸,其中有30個頻率點;然後經過一個非線性環節,再經過另一組濾波器,其中有20個是調製濾波器;最後我們還是測量統計特徵。
之前好像沒有說,不過這些統計特徵同樣也是可以用卷積架構計算的,用卷積和乘方,因爲它們是二次的,具有相關性,做卷積和平方是本質上等效的,它們測量的是變化而不是相關性。如果測量了足夠多的卷積和平方,就和測量相關性是等效的了。所以可以把這個模型看作是一個三階模型,耳蝸部分第一階,調製部分第二階,第三階計算統計特徵也就是和卷積、平方再平均差不多的東西。
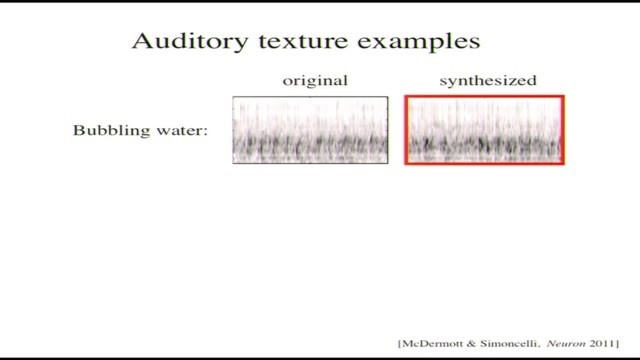
跟剛纔的流程一樣,用類似的方法,給一段樣本計算統計特徵然後生成符合特徵的另一段樣本,結果挺不錯的。我這兒有幾個例子,看看你們能不能聽得到,如果不行那就很快跳過去。
能聽到了嗎?(一段水聲)ok,屏幕上的是頻譜圖,橫軸時間縱軸頻率,這是一段冒泡的水的實際錄音,會不會太大了,有人聽這個會害怕嗎?(另一段水聲)現在是生成的聲音,聽起來應該是沒辦法分辨的。頻譜圖看起來也很像,不過並不是完全一樣,畢竟不是直接複製的。其中的參數數目不多,不過我忘了具體數目有多少了,反正挺少的。跟前面類似,輸入的信息量很大,我們也是扔掉了很多,把樣本擠壓到了一組總結特徵中,然後從總結特徵裏生成新的。
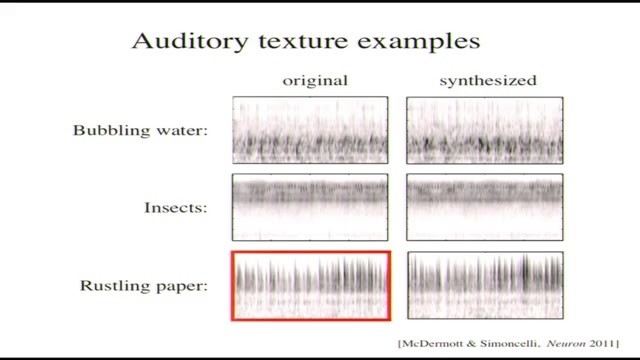
(此起彼伏的蟲子聲音)這是另一段完全不同的聲音了,是池塘裏昆蟲的聲音。(另一段此起彼伏的蟲子聲音)同一個模型,同一組統計特徵,當然了,特徵具體的值是完全不一樣的,所以生成的聲音纔會不一樣。聽起來挺不錯的,而且這個也幾乎沒辦法分辨。
(紙的聲音)另一段不同的聲音,翻動的紙,看頻譜圖以及聽起來都跟另外兩組聲音完全不同。(另一段紙的聲音)這個效果也很好,其實聲音很尖銳,不連續,能聽出來紙頁翻到最後擦到其它的紙然後突然停下來的聲音。
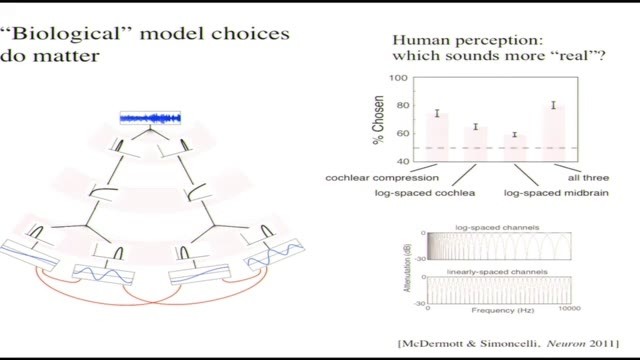
Josh和我很感興趣,我們做了很多感知方面的研究來驗證這種方法的可行性,而這種方法對不同的材質有廣泛的適用性。我們還想知道,當我們人爲地(對計算過程)進行了選擇來讓它看起來更符合生物學的時候,這些人爲因素會對最終的結果產生影響嗎,還是說我隨便用一組什麼樣的濾波器和非線性都能得到一樣的結果。
所以我們回過頭來覈對了一遍,發現,比如當你去掉耳蝸那裏進行壓縮的非線性環節,把它變成一個整流器,然後你讓人們來對比聽聽看的時候,一種是通過整流器的版本生成的,另一種是通過更符合生物學的非線性壓縮版本生成的,人們辨別更真實聲音的能力還挺不錯,他們選出來的是模仿耳蝸壓縮的那一個。更換濾波器組合的情況也差不多,如果從對數空間頻點換到線性空間頻點,還是能聽出來區別的,人類很擅長髮現其中的區別,而且人們基本上都更喜歡對數空間的聲音,從生物學的角度這也更合理。
接下來要欺騙你的眼睛
我們對這種結果挺滿意的。我們還做了另外一組實驗,不過沒時間了我就跳過不講了。因爲我想以這個做結尾。

回到圖像的部分。我們想知道,除了整體的相同紋理之外,我們還能做什麼。顯然這個世界遠不只是由整體的相同紋理組成的,紋理都是一小塊一小塊的,就像一開始那張牛的照片一樣。所以如果你拿一張這樣的照片,用我們的算法進行處理,還是能拿到結果的,畢竟這個方法可以處理任何圖片,統計特徵是對整張照片計算的,不過生成的圖片就會是這樣,費曼就像剛從攪拌機裏拿出來一樣。不過你還是能看出來小塊的紋理,這些皮膚的褶皺,看起來有點不自然。
所以我們想知道,從生理學、生物學的角度考慮,人類大腦裏到底發生了什麼,人的大腦是如何進行表徵的,是次要功能嗎,只有一部分的大腦對紋理進行表徵,其它大部分都表徵的是輪廓、界線、邊緣、物體嗎?還是說又是另外的樣子?
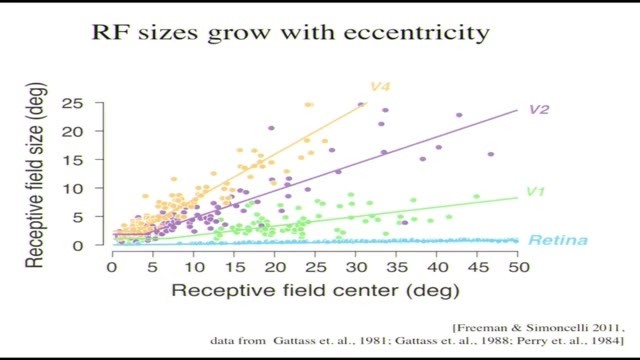
所以我們接下來做的事情用到了這些事實,從生理學角度講,感受野大小隨着偏心度的提高而變大。感受野不僅僅從V1到V2再到V4一直變大,而且還隨着到目光焦點中心的距離變大而變大,離中央凹越遠越大。這種變大差不多是線性的,這張圖是研究猴子得到的,人類的也非常接近。
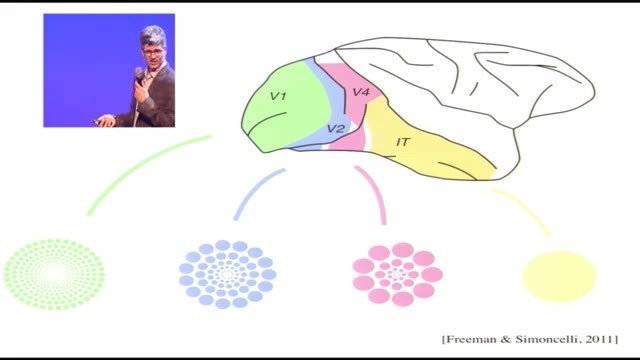
畫一張簡圖來說明的話,雖然因爲顏色的關係大家在臺下可能看不清,可以把V1細胞的感受野想象成這種輻射狀的圖案,越往外圈就越變大。V2細胞的差不多,不過不管在哪個位置,V2的感受野都比V1的更大。V4也一樣。等最後到了IT,感受野就很大了,可以覆蓋到眼睛視野的很大一個區域。說句題外話,這不是卷積,因爲卷積需要始終使用一樣的算子;而在這裏,算子越往外側越大了。所以當我們知道了有這樣的架構以後,我們能做一些什麼,能不能給物體識別這樣的任務帶來幫助呢?
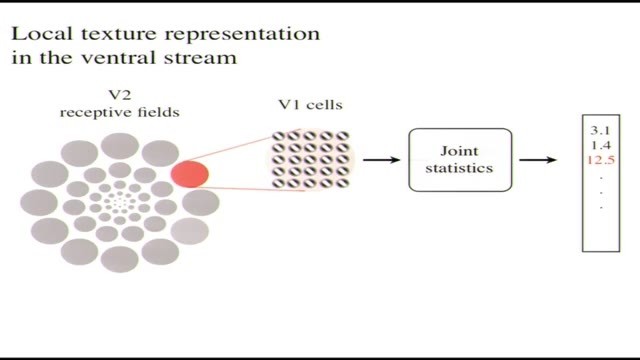
我們是這樣做的。我們用了剛纔說到那樣的局部紋理表徵架構,我們並沒有對整張圖片均勻地提取統計特徵,而是分成許多小區域,具有平滑交疊的區域,然後做加權相加而不是直接全部相加再取平均。這樣它聽起來就跟生理學很接近,跟V2做的事情很接近。實際上當你這麼做的時候,你可以生成人類沒辦法區分開來的圖片,對任意圖片都可以。

我直接放一個演示吧,現在沒時間一項項講解我們的結果了。這張照片是在華盛頓廣場拍的。我要讓大家看一個幻象,爲了能夠看到它,你在看的時候需要緊盯着畫面中央這個紅色的點不動。我會在這張照片和一張生成的圖像之間來回切換,生成的圖像中計算局部統計特徵所用的區域大小就跟人的V2細胞感受野差不多大。我們的想法是,如果人類的大腦就是這樣做表徵的,那你就沒辦法分辨這些圖像。

現在開始了,來回翻動。眼光盯着紅色的點不要移開。如果沒什麼意外的話,那跟我們做實驗時候的參與者一樣,你們應該也沒辦法區分開這兩幅圖像。

但是實際上,如果你現在把注意力放在邊上那個紅色圈裏的話,兩張圖像的區別其實挺大的,其中一張有很多的扭曲,就像前面費曼那張一樣。但是如果你盯着紅色圈的話,你就看不到這些扭曲了。說實話這些扭曲還是挺明顯的,看起來很詭異,但是如果當你不盯着它們看的時候你就發現不了它們。
那我們做這件事是爲了幹嘛?我們把一些東西丟進了零空間裏面,直觀線性地描述的話,就是我們把一些東西丟進了你視覺系統的零空間裏面,然後你發現不了。你的視覺系統把這些信息扔掉了,它發現不了這裏有嚴重的扭曲。我覺得可以利用這一點來解決很多實際問題,不過現在沒時間給大家講了,我要給演講做結尾了。
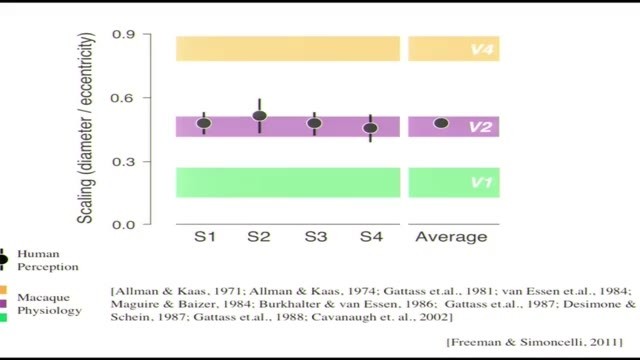
後來的故事是,我們繼續把這些發現跟生理學做了定性定量的對比,我們做了一些實驗,實驗中我們記錄了V2細胞的響應,給它們展示紋理,然後嘗試理解它們表徵的結果是什麼。

這對你生活中的所有事情都會產生影響,就像閱讀,比方說你看書的時候,人的目光不是均勻地從頁面上掃過去的,而是一跳一跳的。每次跳的距離,我們根據這個模型算了一下,差不多剛好就是能讓單詞看得清的那個距離。假如你目光盯着這裏左邊這個紅點,這是我們生成的舉例圖像,你能看清的單詞基本上也就是「myself」和它上下的幾個字母。當你的目光跳轉到下一個位置以後,你就能讀出下一個單詞了。這兩個紅色點之間相對於周圍的文本的距離,就是差不多是你閱讀的時候目光跳轉的典型距離。
這就讓我們覺得可以給閱讀建模,限制閱讀速度的最重要因素之一就是目光跳轉距離。所以我們可以想辦法增加這個跳轉距離,比如通過設計新的閱讀形式,用不同的字體、不同的空檔、不同的字符等等,這樣就不會起到這麼大的混雜或者扭曲效果了。換句話說就是我們想避免把文本信息丟到零空間裏面去,我們想讓它們留在實際的表徵空間裏。建立這樣的模型就給了我們嘗試這樣做並進行研究的機會。

OK,我講差不多了。
這種時候我們可以問自己這樣一個問題,我們可以就這樣研究下去嗎,把線性濾波、整流器、一些局部統計特徵以及池化堆在一起,越堆越多就可以解釋人類視覺了嗎?我以前覺得大概不行吧,不過現在隨着深度卷積網絡的研究越來越成功,我猜答案也許是肯定的。Lettvin在1976年的時候說了一段的令人印象深刻的話:「經過部分重新定義的紋理,也許是就構建出形態的原始素材」。他的觀點裏大概覺得你可以在紋理表徵的基礎上進行形態的表徵,而不是把形態作爲一個單獨的實體。

總結
那麼,總結一下。
我前面嘗試從生物學角度給大家解釋了這種階梯式模型的建立,我試着讓大家相信帶有生物學屬性的淺層階梯式模型的力量比我們預想的,起碼比我預想的強大多了。
生成式方法是表徵研究非常有力的測試方法,可以用來驗證不變性,或者探究零空間如果你感興趣的話;它還可以用來驗證度量屬性,比如距離和曲率——這是去年ICLR2016的時候展示的內容,Olivia Hanoff和我一起做了一張精美的海報,展示了我們可以生成測地線,兩張圖像中的路線和圖像空間在響應空間中沿最短路徑的距離(pads and image space between 2 images that followed the shortest path in the response space)。
我們現在也在繼續充實這些模型,來讓它們能夠測量感知質量。爲了達到這個目的,你還需要在其中加入新的非線性部分來關注局部增益控制,局部增益控制是指你通過生物學感知系統看到的東西,我們覺得這對研究大腦的運行有非常非常重要的作用。這件事是大多數深度網絡研究中沒有做的,我們覺得它的重要性也會得到體現。我們用了很多種不同的方法來研究它,其中一種大家會在下一場演講中聽我講到,會講到用帶有局部增益控制的表徵進行壓縮。
最後一點,就是我們非常想要理解如何用非監督學習的方法學會這些表徵,下一場演講我也會在生物學表徵的語境下開始對這個方面做一些強調。

最後我想感謝一下我實驗室裏參與項目的成員,都非常的優秀,Javier Portilla建立了最早的紋理模型,Jeremy Freeman建立了基於局部紋理塊的大型全局紋理模型,Corez Ziemba積極參與了很多心理物理學和生理學方面的研究,Josh McDermott建立了聲學模型。
謝謝!
AI科技評論招聘季全新啓動!
很多讀者在思考,「我和AI科技評論的距離在哪裏?」答案就是:一封求職信。
AI科技評論自創立以來,圍繞學界和業界鰲頭,一直爲讀者提供專業的AI學界、業界、開發者內容報道。我們與學術界一流專家保持密切聯繫,獲得第一手學術進展;我們深入巨頭公司AI實驗室,洞悉最新產業變化;我們覆蓋A類國際學術會議,發現和推動學術界和產業界的不斷融合。
而你只要加入我們,就可以一起來記錄這個風起雲涌的人工智能時代!
*英語好,看論文毫無壓力
*理工科或新聞相關專業優先,好鑽研
*對人工智能有一定的興趣或瞭解
* 態度好,學習能力強
簡歷投遞:
北京:lizongren@leiphone.com
深圳:guoyixin@leiphone.com
