卡內基梅隆大學計算機科學學院最近一篇正在評議階段的 ICLR 2018 論文在 arXiv 上公開,該論文證明使用分佈式詞嵌入的 Softmax 實際上沒有足夠的能力來建模自然語言,他們爲此也提出了自己的解決方法。本論文的並列第一作者是 Zhilin Yang 和 Zihang Dai。楊植麟(Zhilin Yang)本科就讀於清華大學計算機系,現就讀於CMU。曾在清華 4 年保持全年級第一,同時也是清華大學 2014 年本科生特獎獲得者。此外,領導蘋果公司的人工智能技術研究的 CMU 教授 Ruslan Salakhutdinov 也是該論文的作者之一。本文由浙江大學博士生楊海宏推薦,他的研究方向爲知識圖譜問答。
在因式分解(factorization)的基礎上,基於循環神經網絡(RNN)的語言模型在多項基準上都達到了當前最佳的水平。儘管 RNN 作爲通用近似器有出色的表達能力,但點積和 Softmax 的組合是否有能力建模條件概率(會隨語境的變化而發生巨大的變化),這個問題還沒有得到清楚的解答。
在這項工作中,我們從矩陣分解的角度研究了前面提到的基於 Softmax 的循環語言模型的表達能力。我們表明使用標準公式學習基於 Softmax 的循環語言模型等價於求解矩陣分解問題。更重要的是,因爲自然語言高度依賴於語境,所以被分解的矩陣可能是高秩的(high-rank)。這進一步表明帶有分佈式(輸出)詞嵌入的基於標準 Softmax 的語言模型沒有足夠的能力建模自然語言。我們稱之爲 Softmax 瓶頸(Softmax bottleneck)。
我們提出了一種解決 Softmax 瓶頸的簡單且有效的方法。具體而言,我們將離散隱變量(discrete latent variable)引入了循環語言模型,並且將 next-token 概率分佈形式化爲了 Mixture of Softmaxes(MoS)。Mixture of Softmaxes 比 Softmax 和以前的研究考慮的其它替代方法有更好的表達能力。此外,我們表明 MoS 可以學習有更大的歸一化奇異值(normalized singular values)的矩陣,因此比 Softmax 和基於真實世界數據集的其它基準有高得多的秩。
我們有兩大貢獻。首先,我們通過將語言建模形式化爲矩陣分解問題而確定了 Softmax 瓶頸的存在。第二,我們提出了一種簡單且有效的方法,可以在當前最佳的結果上實現顯著的提升。

論文地址:https://arxiv.org/pdf/1711.03953.pdf
摘要:我們將語言建模形式化了矩陣分解問題,並且表明基於 Softmax 的模型(包括大多數神經語言模型)的表達能力受限於 Softmax 瓶頸。鑑於自然語言高度依賴於語境,這就進一步表明使用分佈式詞嵌入的 Softmax 實際上沒有足夠的能力來建模自然語言。我們提出了一種解決這一問題的簡單且有效的方法,並且在 Penn Treebank 和 WikiText-2 上分別將當前最佳的困惑度水平改善到了 47.69 和 40.68。
在 PTB 和 WT2 上的語言建模結果分別在表 1 和表 2 中給出。在參數數量差不多的情況下,MoS 的表現超越了所有使用了或沒使用動態評估(dynamic evaluation)的基準,並且在當前最佳的基礎上實現了顯著的提升(困惑度改善了高達 3.6)。
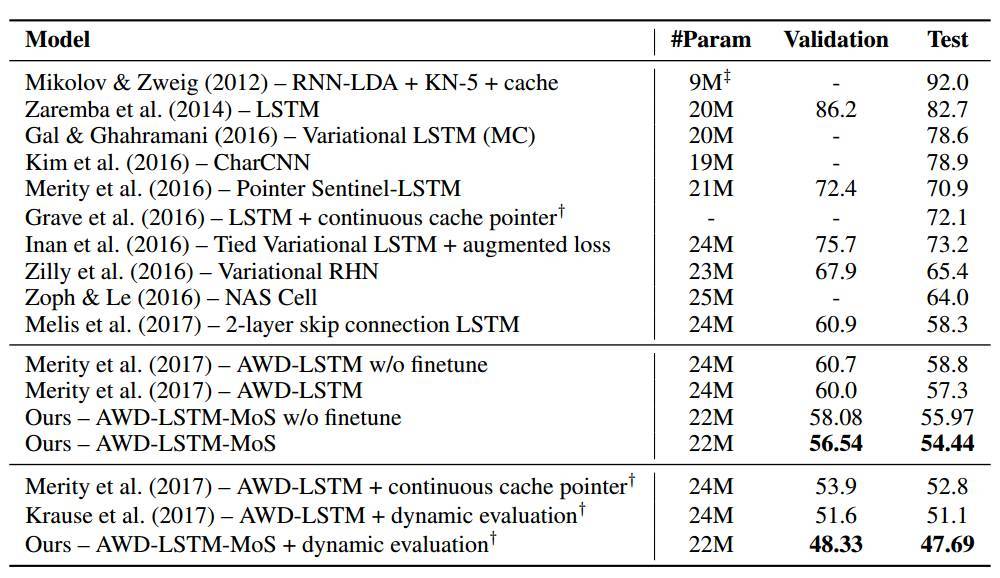
表 1:在 Penn Treebank 的驗證集和測試集上的單個模型困惑度。基準結果是從 Merity et al. (2017) 和 Krause et al. (2017) 獲得的。† 表示使用了動態評估。
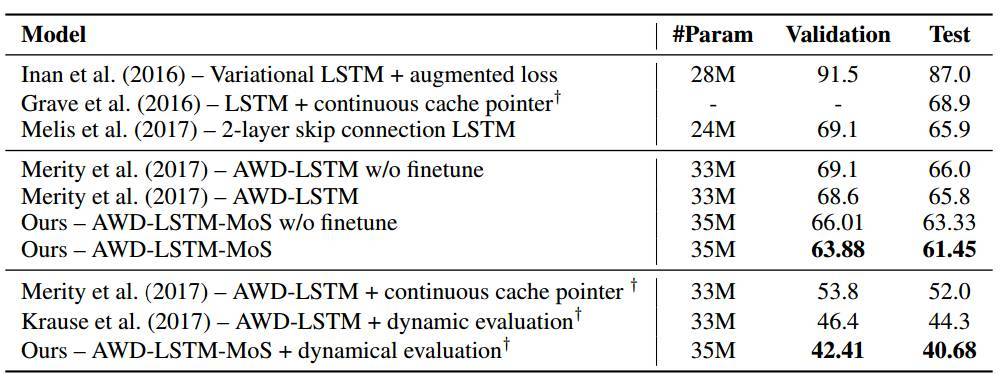
表 2:在 WikiText-2 上的單個模型困惑度。基準結果是從 Merity et al. (2017) 和 Krause et al. (2017) 獲得的。† 表示使用了動態評估。
爲了進一步驗證上面所給出的改善確實源自 MoS 結構,而不是因爲增加了額外的隱藏層或找到了一組特定的超參數,我們在 PTB 和 WT2 上執行了 ablation study(是指移除模型和算法的某些功能或結構,看它們對該模型和算法的結果有何影響)。

表 3:在 Switchboard 上的評估分數。
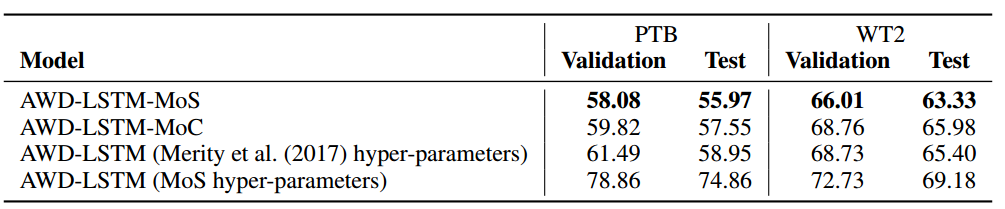
表 4:在 Penn Treebank 和 WikiText-2 上的 ablation study,沒有使用微調或動態評估。
我們繪製了歸一化的奇異值的累積百分比,即歸一化的奇異值低於某個閾值的百分比。
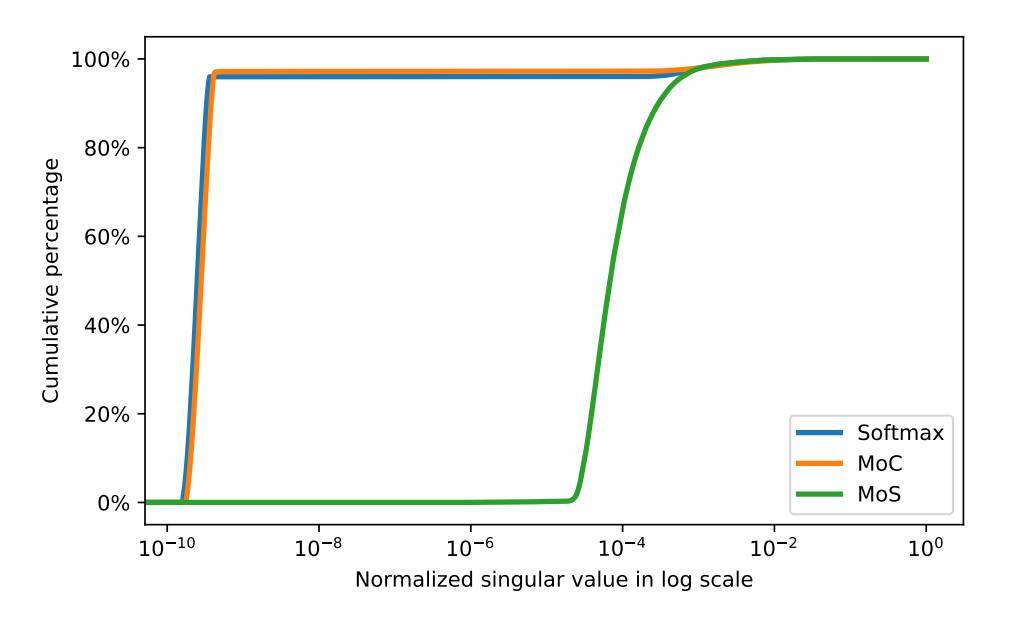
圖 1:給定 [0,1] 中的一個值,歸一化奇異值的累積百分比。