選自arXiv
自動 bug 歸類算法可以被形式化爲分類任務,其中主要挑戰在於 bug 描述通常包含噪聲。在這項研究中,作者提出了一種新型 bug 報告表徵算法 DBRNN-A,能無監督地學習長詞序列的句法和語義特徵,以及語境表徵。他們主要使用了未修復的 bug 報告,而過去的研究都沒有重視這一點。此外,作者還開源了整個數據集、具體的數據集劃分以及源代碼,使得該研究可復現。
在通常的過程中,終端用戶在系統上工作時遇到 bug(也稱爲問題或缺陷),並在 bug 追蹤系統中報告這一問題 [8]。圖 1 展示了谷歌 Chromium 項目中(bug ID: 638277)報告的一個 bug 示例截圖。bug 報告通常包含一個 bug 總結和一個涉及再現步驟的詳細描述。已修復狀態的 bug 同樣包含修復 bug 並被稱爲其所有者的開發者。bug 歸類的過程包含多個步驟,其中第一步主要是分配 bug 到其中一個更可能解決這一 bug 的開發者。因此,在該研究的其餘部分中,bug 歸類指的是爲開發者分配 bug 報告的任務 [1]。
在大規模系統中,隨着大量 bug 不斷出現,人工分析和歸類 bug 就變的異常費力。人工歸類 bug 通常根據 bug 報告的內容而進行,主要包含總結和描述。儘管額外的輸入源已在文獻中被探索,比如來自 github[3] 的開發者分析,並且利用了組件信息 [5],絕大部分研究努力已聚焦在利用 bug 報告內容進行歸類 [2] [14] [27] [28] [29] [32] [33]。通過 bug 報告內容,自動 bug 歸類可以轉化爲一個分類問題,並把 bug 標題和描述映射到其中一個開發者(分類標籤)。然而,bug 報告內容包含帶噪聲的文本信息,比如代碼片段和堆棧跟蹤細節,如圖 1 所示。處理這些非結構和噪音數據是分類器學習中的一個主要挑戰。

圖 1:谷歌 Chromium 項目中 bug 報告的一個截圖(bug ID: 638277)。

圖 2:來自谷歌 Chromium bug 庫中的 bug 報告,被用作標註模板以訓練分類器。
研究貢獻
從長文本(例如 bug 報告描述)中按單詞順序學習語義表徵是很有挑戰性的研究問題。因此,作者提出了一種深度學習技術,能以無監督的方式從 bug 報告內容中學習簡明的固定長度的表徵,即該表徵可以直接通過學習數據得到,而不需要手動特徵工程。作者嘗試解決的問題如下:
(1)使用深度學習進行自動 bug 歸類是否可行?
(2)和傳統的特徵工程方法對比,無監督特徵工程如何執行?
(3)每個類的訓練樣本數會影響分類器的性能嗎?
(4)僅使用 bug 總結或描述進行 bug 歸類的性能會不會受影響?
(5)在 bug 歸類中使用遷移學習是否可行?
最近,基於 RNN 的深度學習算法革新了詞序列表徵的概念,並在很多應用中(例如語言建模和機器翻譯)做出了很有潛在價值的突破。Lam 等人 [17] 使用 DNN 結合 rSVM 以學習源代碼和 bug 報告之間的普遍關係,並用於有效的 bug 定位。White 等人 [30] 提供了一個廣泛的視角,討論了深度學習如何應用於軟件庫中以解決一些挑戰性的問題。本項研究的主要貢獻可總結爲:
提出了一種使用 DBRNN-A(基於注意力和 LSTM 單元的深度雙向循環神經網絡)的新型的 bug 報告表徵方法。作者提出的深度學習算法可以在長文本中「記住」其中的語境。
一個開源 bug 庫中有 70% 的未歸類和未解決的 bug 報告,很多文獻都忽略了這一點 [14]。在本項研究中,作者提出了一種機制,能以無監督的方式利用所有未歸類的 bug 學習 bug 表徵。
作者在實驗中使用了來自三個開源 bug 庫的實驗數據,分別是來自 Google Chromium 的 383104 個 bug 報告、來自 Mozilla Core 的 314388 個 bug 報告,和來自 Mozilla Firefox 的 162307 個 bug 報告。由於在不同的訓練-測試劃分的數據集上的分類器性能是不可比較和不可復現的,因此作者開源了整個數據集、具體的數據集劃分以及源代碼,使得該研究可復現。
作者進一步研究了提出的 bug 訓練方法在交叉數據測試場景中的有效性。通過使用 Chromium 項目中的 bug 訓練模型,並將模型用在 Core 和 Firefox 項目(Mozilla bug 庫)中進行 bug 歸類,展示了該深度學習模型的遷移學習能力。
本文提出的方法
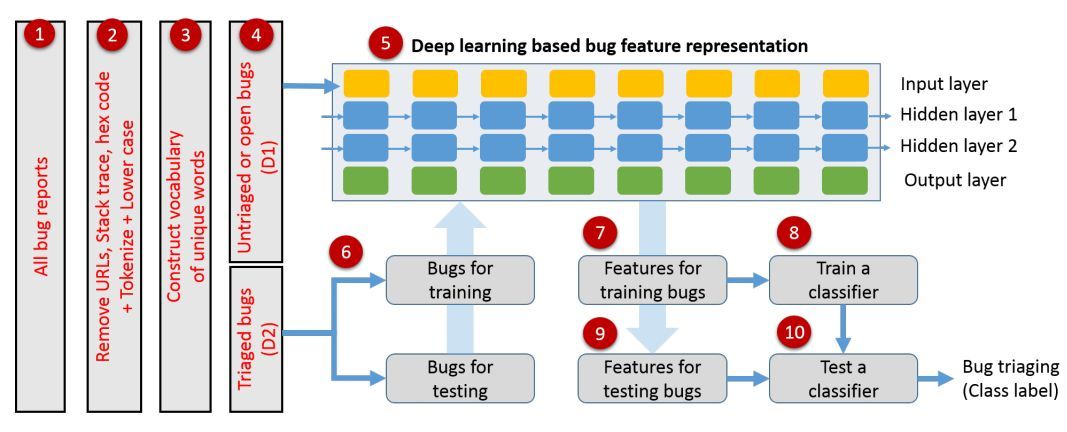
圖 4:本文提出的完整算法的重要步驟流程圖。
自動 bug 歸類算法可以被形式化爲一個分類任務,取 bug 標題和描述爲輸入,將其映射到開發者(分類標籤)之一。圖 4 展示了自動 bug 歸類算法的主要步驟,詳細解釋如下:
(1)一個 bug 語料庫的總結(標題)、描述、報告時間、狀態和所有者都是從一個開源 bug 追蹤系統中提取出來的。
(2)處理非結構化描述中的 URL、堆棧軌跡、十六進制代碼和代碼片段需要對深度學習模型進行特定的訓練,因此在本研究工作中,這些內容在預處理階段被刪除了。
(3)在語料庫中出現至少 k 次的獨特單詞被提取爲詞彙表。
(4)已歸類的 bug(D2)被用於訓練和測試分類器,而所有未歸類/開放的 bug(D1)被用於訓練深度學習模型。
(5)使用基於注意力機制的深度雙向循環神經網絡學習 bug 表徵,其中考慮了 bug 總結和描述,並將其組合爲詞 token 序列。
(6) 將歸類 bug(D2)分成訓練和測試數據,並進行 10 倍交叉驗證以消除訓練偏差,
(7) 使用已學習的 DB-RNN 算法提取訓練 bug 報告的特徵表徵,
(8) 訓練監督分類器以執行作爲 bug 歸類過程一部分的開發者分配,
(9) 接着使用已學習的深度學習算法提取測試 bug 的特徵表徵,
(10) 通過提取的特徵和已學習的分類器,可以在測試集中爲每一個潛在的開發者預測概率值並計算分類準確率。
該方法和傳統的自動歸類 bug 通道不同,(i) 步驟 4 中,考慮了未歸類的 bug(D1)(在傳統方法中完全被忽略),(ii) 基於深度學習的 bug 報告表徵取代了 BOW 表徵。步驟 4 和 5 的添加,使得可以自動從數據本身而不是通過手工工程學習 bug 報告表徵。
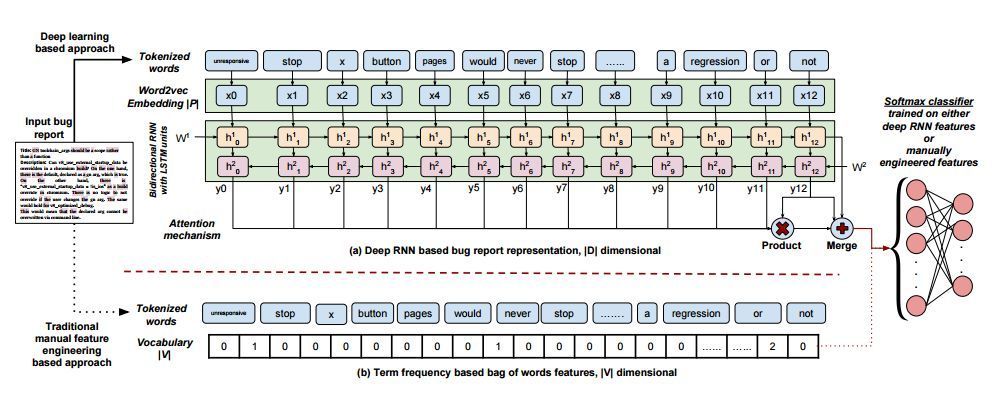
圖 5:具有 LSTM 單元的深度雙向循環神經網絡(RNN)的詳細解釋,用於圖 1 所示的示例性 bug 報告。可以看出,深度網絡有多個隱藏層,以學習一個複雜的來自輸入數據的層級表徵。作爲對比,還展示了針對相同示例語句的基於 tf 的 BOW 表徵。
論文:DeepTriage: Exploring the Effectiveness of Deep Learning for Bug Triaging

論文鏈接:http://bugtriage.mybluemix.net/
bug 歸類處理的主要任務是對給定的軟件 bug 報告,確定更有可能修復 bug 的開發者。大多數 bug 追蹤系統都會展示 bug 標題(總結)和細節描述。自動 bug 歸類算法可以被形式化爲一個分類任務,取 bug 標題和描述爲輸入,將其映射到開發者(分類標籤)之一。其中主要的挑戰在於 bug 描述通常包含非結構化的文本、代碼片段和堆棧軌跡,使輸入數據充滿噪聲。過去十年內出現了很多研究,使用基於 tf-idf 的詞袋特徵(bag-of-words feature,BOW)模型來表徵 bug 報告。然而,BOW 模型並沒有考慮描述性語句中的句法型和序列型的詞信息。
在這項研究中,我們提出了一種使用基於注意力的深度雙向循環神經網絡(deep bidirectional recurrent neural network,DBRNN-A)模型的新型 bug 報告表徵算法,它能以無監督的方式從長詞序列中學習句法的和語義的特徵。我們用基於 DBRNN-A 的魯棒的 bug 表徵取代 BOW 特徵,用於訓練分類模型。此外,使用注意力機制使得模型可以學習 bug 報告中長詞序列的語境表徵。爲了提供大量的數據用於訓練該特徵學習模型,我們在該項研究中主要使用了未修復的 bug 報告(包含一個開源 bug 追蹤系統的 70% 的 bug),而過去的研究都沒有重視這一點。
我們的另一項主要的貢獻是將代碼開源,並從三個開源 bug 追蹤系統(Google Chromium、Mozilla Core 和 Mozilla Firefox)創建了一個公開的 bug 報告的基準數據集,使這項研究可以被複現。我們在實驗中使用了來自 Google Chromium 的 383104 個 bug 報告、來自 Mozilla Core 的 314388 個 bug 報告,和來自 Mozilla Firefox 的 162307 個 bug 報告。我們實驗地比較將該模型與 BOW 模型、softmax 分類器、支持向量機、樸素貝葉斯和餘弦距離進行了比較,並觀察到 DBRNN-A 可以得到高 10 級的平均準確率。