選自 tryolabs
作者通過本文概述了 2017 年深度學習技術在 NLP 領域帶來的進步,以及未來的發展趨勢,並與大家分享了這一年中作者最喜歡的研究。2017 年是 NLP 領域的重要一年,深度學習獲得廣泛應用,並且這一趨勢還會持續下去。
近年來,深度學習(DL)架構和算法在圖像識別、語音處理等領域實現了很大的進展。而深度學習在自然語言處理方面的表現最初並沒有那麼起眼,不過現在我們可以看到深度學習對 NLP 的貢獻,在很多常見的 NLP 任務中取得了頂尖的結果,如命名實體識別(NER)、詞性標註(POS tagging)或情感分析,在這些任務中神經網絡模型優於傳統方法。而機器翻譯的進步或許是最顯著的。
本文,我將概述 2017 年深度學習技術在 NLP 領域帶來的進步。可能會有遺漏,畢竟涵蓋所有論文、框架和工具難度太大。我想和大家分享這一年我最喜歡的一些研究。我認爲 2017 年是 NLP 領域的重要一年。深度學習在 NLP 中的應用變得廣泛,在很多分支取得了傲人的成績,所有這些都說明這個趨勢不會停止。
從訓練 word2vec 到使用預訓練模型
可以說,詞嵌入是用於自然語言處理(NLP)的最廣爲人知的深度學習(DL)技術。它遵循由 Harris(1954)提出的分佈式假設,根據該假設,具有相似含義的詞通常出現在相似語境中。如想詳細瞭解詞嵌入,推薦閱讀 Gabriel Mordecki 的文章:《Word embeddings: how to transform text into numbers》(https://monkeylearn.com/blog/word-embeddings-transform-text-numbers/)。
詞的分佈式向量示例(圖像來源:https://arxiv.org/abs/1708.02709)。
word2vec(Mikolov et al., 2013)和 GloVe(Pennington et al., 2014)是該領域的先驅性算法,儘管它們無法被稱爲 DL(word2vec 中的神經網絡是淺層的,GloVe 實現了一種計數方法),但藉助它們進行訓練的模型通常用作深度學習 NLP 方法的輸入數據。它的效果很好,因此越來越多的人開始使用詞嵌入。
最初,對於一個需要詞嵌入的 NLP 問題,我們傾向於利用與領域相關的大型語料庫訓練自己的模型。當然,這不是推進詞嵌入廣泛使用的最佳方式,因此人們開始慢慢轉向預訓練模型。通過在維基百科、推特、谷歌新聞、網頁抓取內容等上面進行訓練,這些模型可以輕鬆地把詞嵌入整合到 DL 算法中。
今年證實,預訓練詞嵌入模型仍然是 NLP 中的核心問題。比如來自 Facebook 人工智能實驗室(FAIR)的 fastText 發佈了 294 種語言的預訓練向量,對社區做出了重大貢獻。除了大量的語言,fastText 這一舉措的有用之處在於其使用字符 n 元作爲特徵。這使得 fastText 避免了 OOV(out of vocabulary)問題,因爲即使非常罕見的詞(比如特定領域的術語)也很可能與常見詞共享字符 n 元。在這個意義上,fastText 要比 word2vec 和 GloVe 表現更好,並且它在小數據集上的表現也要優於二者。
然而,儘管我們看到一些進展,這一領域中仍有很多事情要做。比如,NLP 框架 spaCy 通過整合詞嵌入和 DL 模型以本地方式完成諸如命名實體識別(NER)和依存句法分析(Dependency Parsing)等任務,允許用戶更新模型或使用他們自己的模型。
我認爲這就是趨勢。未來將會有針對特定領域(比如生物、文學、經濟等)、易於在 NLP 框架中使用的預訓練模型。就我們的使用情況來說,錦上添花的事情就是以儘可能簡單的方式調整它們。與此同時,現在開始出現適應詞嵌入的方法。
使用通用嵌入適應特定用例
也許使用預訓練詞嵌入的主要缺點是訓練數據和真實數據之間存在詞分佈式差距。假設你有一個生物學論文、食譜或者經濟學研究論文的語料庫。由於你很可能沒有一個足夠大的語料庫訓練好的嵌入,所以通用詞嵌入可能幫助你提升結果。但是如果你能使通用嵌入適應你的特定用例呢?
在 NLP 中此類適應通常被稱爲跨域或域適應技術,並且非常接近遷移學習。Yang et al. 今年提出了一個非常有趣的工作,在給定源域嵌入的情況下,他們展示了一個正則化的 skip-gram 模型來學習目標域的詞嵌入。
其核心思想簡單卻有效。想象一下如果我們知道源域中詞 w 的詞嵌入爲 w_sws。爲了計算 w_twt(目標域)的嵌入,研究者將兩個域之間的特定遷移量添加到 w_sws。基本上,如果詞頻繁出現在兩個域中,這意味着其語義並不依賴於域。這種情況下,遷移量很大,在兩個域中產生的嵌入可能相似。但是如果特定域的詞在一個域中出現的頻率比另一個域頻繁得多,則遷移量小。
該詞嵌入研究主題還未被廣泛探索,我認爲在不久的將來它將獲得更多關注。
情感分析不可思議的「副作用」
青黴素、X 光甚至郵件都是意料之外的發現。今年,Radford et al. 發現訓練模型中的單個神經元具有高度可預測的情感值,並探索了字節級的循環語言模型屬性,旨在預測亞馬遜評論文本中的下一個字符。是的,這一單個「情感神經元」能夠相當精確地區分消極和積極的評論。
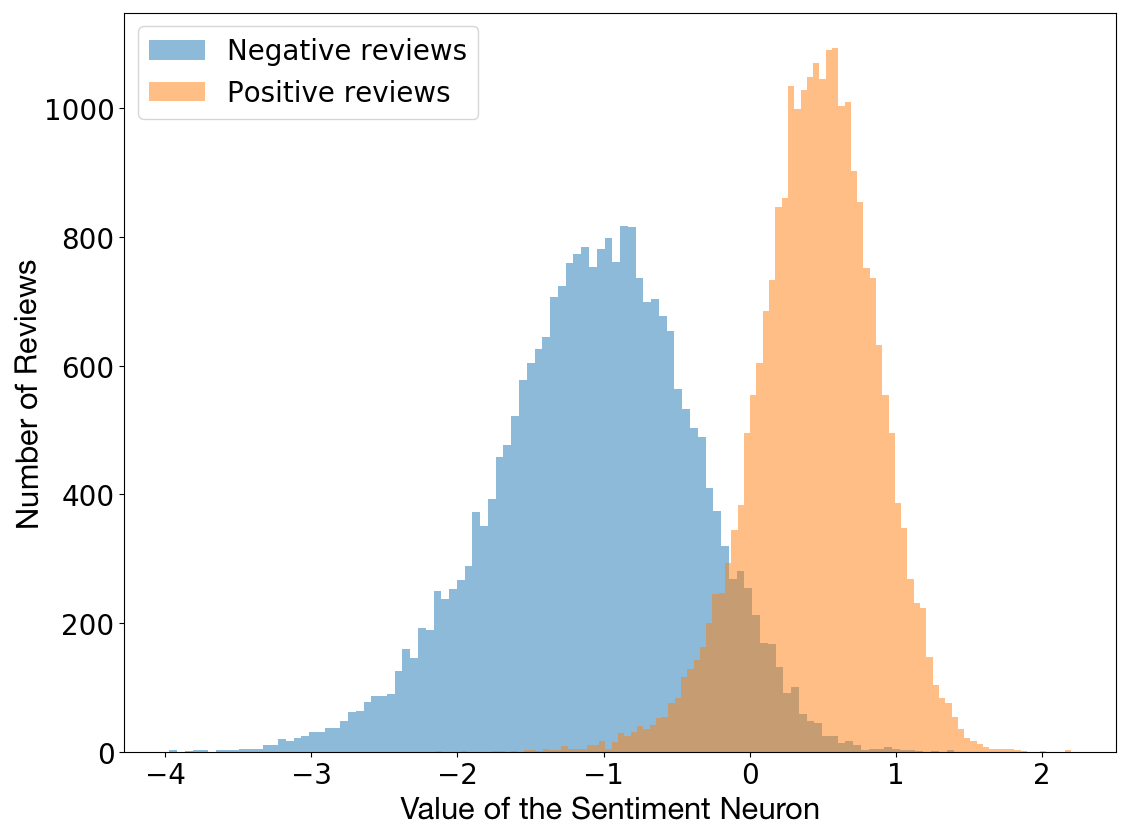
評論極性 vs 神經元值(圖像來源:https://blog.openai.com/unsupervised-sentiment-neuron/)。
注意到這個行爲之後,Radford 等人決定在 Stanford Sentiment Treebank 上測試該模型,測試結果顯示其精確度高達 91.8%,而之前的最優結果是 90.2%。這意味着通過顯著減少實例的使用,他們以無監督方式訓練的模型至少在一個特定但經過廣泛研究的數據集上取得了當前最佳的情感分析結果。
運轉中的情感神經元
由於模型在字符級別上起作用,因此神經元爲文本中的每個字符改變狀態,其工作方式看起來相當驚人。

情感神經元的行爲(圖像來源:https://blog.openai.com/unsupervised-sentiment-neuron/)。
比如,在詞 best 之後,神經元值呈現爲強積極;但是詞 horrendous 出現時,神經元值的狀態完全相反。
生成極性(polarity)有偏文本
當然,已訓練模型仍然是有效的生成模型,因此它能用於生成類似 Amazon 評論的文本。但我發現你可以簡單地重寫情感神經元的值,從而選擇生成文本的情感級性(積極或消極)。

生成文本示例(圖像來源:https://blog.openai.com/unsupervised-sentiment-neuron/)。
Radford 等人選擇的神經網絡模型是 Krause 等人在 2016 年提出的 multiplicative LSTM,選擇原因是他們觀察到在給定超參數設置情況下,multiplicative LSTM 的收斂速度比一般的 LSTM 快。該模型有 4096 個單元,且在 8200 萬亞馬遜評論語料庫中進行訓練。
推特上的情感分析
無論是獲取客戶對企業品牌的評價、分析營銷活動的影響還是民意調查,Twitter 上的情感分析都是非常強大的工具。
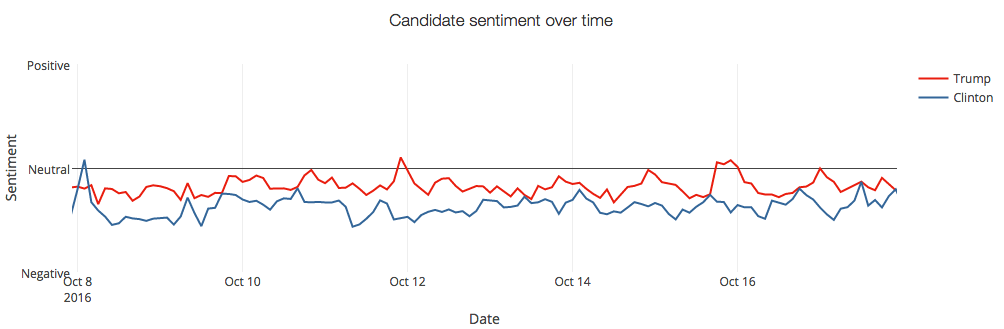
特朗普和希拉里在 Twitter 上的情感分析(圖像來源:https://monkeylearn.com/blog/donald-trump-vs-hillary-clinton-sentiment-analysis-twitter-mentions/)。
SemEval 2017
Twitter 中的情感分析不僅已經引起了 NLP 研究者的關注,同時還引起了政治和社會科學的關注。這就是爲什麼自 2013 年以來,SemEval 比賽設置了推特情感分析任務。
今年共有 48 支隊伍參加了該任務,表明人們對推特情感分析的關注程度。爲了說明 SemEval 比賽中推特情感分析的內容,下面我們看一下該競賽今年的子任務:
子任務 A:給定一篇推文,判斷該推文表達情感是積極、消極還是中性。
子任務 B:給定一篇推文和一個主題,區分推文傳遞到該主題的情感是積極還是消極。
子任務 C:給定一篇推文與一個主題,區分推文傳遞到該主題的情感是強積極、弱積極、中性、弱消極還是強消極。
子任務 D:給定關於相同主題的一組推文,評估這組推文在積極和消極之間的分佈。
子任務 E:給定關於相同主題的一組推文,評估這組推文在強積極、弱積極、中性、弱消極和強消極之間的分佈。
其中子任務 A 是最常見的情感分析任務,有 38 支團隊參與了該任務,但其它幾個任務更具挑戰性。組織方表明深度學習方法的使用十分突出且得到持續的提升,今年有 20 支隊伍採用了 CNN 和 LSTM 等深度學習模型。此外,雖然 SVM 模型仍然非常流行,但很多參賽者將它們與神經網絡方法結合起來,或使用詞嵌入特徵。
BB_twtr 系統
我發現今年令人印象深刻的是一個純 DL 系統 BB_twtr 系統(Cliche, 2017),該系統在英語任務的 5 個子任務中名列第一。該系統的作者將 10 個 CNN 與 10 個雙向 LSTM(biLSTM)結合起來,並使用不同的超參數和預訓練策略進行訓練。
爲了訓練這樣的模型,作者使用人工標註的推文(子任務 A 就有 49693 篇樣本),構建包含 1 億篇推文的無標註數據集,作者通過表情符號將推文簡單地標註爲積極情感或消極情感,從中抽取出一個隔離的數據集。爲了將預訓練的詞嵌入作爲 CNN 和雙向 LSTM 的輸入,作者在未標記的數據集上使用 word2vec、GloVe 和 fastText(全部使用默認設置)等方法構建詞嵌入。然後他使用前面隔離數據集提煉詞嵌入以添加積極和消極信息,最後再使用人工標註的數據集對他們再次進行提煉。
之前使用 SemEval 數據集的經驗表明使用 GloVe 會降低性能,並且對所有的標準數據集並沒有唯一的最優模型。因此作者用軟投票策略將所有模型結合起來,由此產生的模型比 2014 和 2016 年的歷史最好成績都要好。
即使這種組合不是以一種有機的方式進行,但這種簡單的軟投票策略已經證明了模型的高效性,因此這項工作表明瞭將結合 DL 模型的潛力,以及端到端的方法在推特情感分析任務中的性能優於監督方法。
令人興奮的抽象摘要系統
自動摘要和機器翻譯一樣是 NLP 任務。自動摘要系統有兩個主要的方法:抽取式——從源文本中抽取最重要的部分來創建摘要;生成式——通過生成文本來創建摘要。從歷史角度來看,抽取式自動摘要方法最常用,因爲它的簡潔性優於生成式自動摘要方法。
近年來,基於 RNN 的模型在文本生成領域獲得了驚人成績。它們在短輸入和輸出文本上效果非常好,但對長文本的處理不太好,不連貫且會重複。Paulus et al. 在論文中提出一種新的神經網絡模型來克服該侷限。結果很好,如下圖所示。

自動摘要生成模型圖示(圖片來源:https://einstein.ai/research/your-tldr-by-an-ai-a-deep-reinforced-model-for-abstractive-summarization)。
Paulus et al. 使用 biLSTM 編碼器讀取輸入,使用 LSTM 解碼器生成輸出。他們的主要貢獻是一種新的注意力內策略(intra-attention strategy),分別關注輸入和持續生成的輸出;和一種新的訓練方法,將標準監督式詞預測和強化學習結合起來。
注意力內策略
目標是避免重複輸出。研究者在解碼時使用時間注意力(temporal attention),以查看輸入文本之前的 segments,從而確定接下來要生成的單詞。這強制模型在生成過程中使用輸入的不同部分。他們還讓模型評估解碼器中之前的隱藏狀態。然後結合這兩個功能選擇輸出摘要中最適合的單詞。
強化學習
創建摘要的時候,兩個人會使用不同的單詞和句子順序,兩個摘要可能都是有效的。因此,好的摘要的詞序未必要匹配訓練數據集中的順序。基於此,論文作者沒有使用標準的 teacher forcing 算法,該算法可使每個解碼步(即每個生成單詞)的損失最小化;而是使用強化學習策略,這被證明是一個很棒的選擇。
幾乎端到端模型的結果
該模型在 CNN/Daily Mail dataset 上進行測試,獲得了當前最佳結果。此外,人類評估員參與的特定實驗證明人類的閱讀能力和質量也有提升。在基礎的預處理後能夠取得這樣的結果非常驚人,預處理包括:輸入文本標記化、小寫,數字用 0 代替,移除數據集中的某些實體。
邁向完全無監督機器翻譯的第一步
雙語詞典構建,即使用源語言和目標語言的單語語料庫獲取兩種語言詞向量之間的映射關係,是一個古老的 NLP 任務。自動構建雙語詞典在信息檢索、統計機器翻譯等 NLP 任務中起到一定作用。但是,這種方法主要依賴於初始的雙語詞典,而這種詞典通常不容易獲取或構建。
隨着詞嵌入的成功,跨語言詞嵌入出現,其目標是對齊嵌入空間而不是詞典。不幸的是,這種方法仍然依賴於雙語詞典或平行語料庫。Conneau et al.(2018)在論文中呈現了一種很有前景的方法,該方法不依賴於任何特定資源,且在多個語言對的詞翻譯、句子翻譯檢索和跨語言詞彙相似度任務上優於頂尖的監督方法。
該方法將在單語數據上分別訓練的兩種語言的詞嵌入集作爲輸入,然後學習二者之間的映射,以使共享空間中的翻譯結果較爲接近。他們使用的是用 fastText 在 Wikipedia 文檔上訓練的無監督詞向量。下圖展示了其關鍵想法:
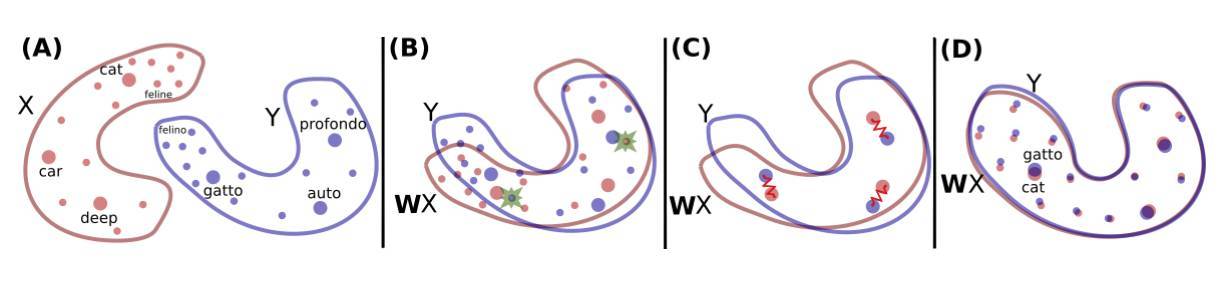
構建兩個詞嵌入空間之間的映射(圖像來源:https://arxiv.org/pdf/1710.04087.pdf)。紅色的 X 分佈是英語單詞的詞嵌入,藍色的 Y 分佈是意大利單詞的詞嵌入。
首先,他們使用對抗學習學習旋轉矩陣 W,W 執行第一次原始對齊(raw alignment)。他們基本上按照 Goodfellow et al.(2014)的 proposition 訓練生成對抗網絡(GAN)。如想對 GAN 的工作原理有直觀瞭解,推薦閱讀 https://tryolabs.com/blog/2016/12/06/major-advancements-deep-learning-2016/。
爲了使用對抗學習來建模問題,他們使判別器具備決定作用,從 WX 和 Y 中隨機採樣一些元素(見上圖第二列),兩種語言分屬於 WX 和 Y。然後,他們訓練 W 阻止判別器做出準確預測。在我看來,這種做法非常聰明、優雅,直接結果也很不錯。
之後,他們用兩步重新定義映射。一步用來避免罕見詞引入映射計算中的噪聲,另一步主要使用學得的映射和距離測量(distance measure)來構建實際的翻譯結果。
這種方法在一些案例中的結果非常好,比如在英語-意大利語詞翻譯中,在 P@10 中,該方法在 1500 個源單詞上的準確率比最優平均準確率高將近 17%。
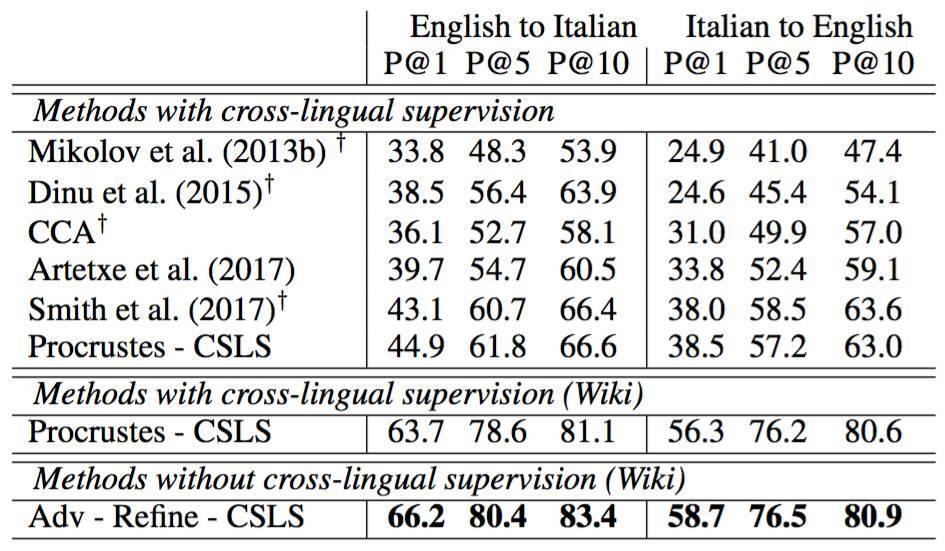
英語-意大利語詞翻譯平均準確率(圖像來源:https://arxiv.org/pdf/1710.04087.pdf)。
Conneau 等人稱他們的方法是通向無監督機器翻譯的第一步。如果真的是這樣,那就太棒了。這種新方法能走多遠,讓我們拭目以待。
專用框架和工具
現有大量通用 DL 框架和工具,其中一些得到廣泛應用,如 TensorFlow、Keras 和 PyTorch。但是,專門用於 NLP 的開源 DL 框架和工具出現了。2017 年對我們來說是重要一年,因爲很多有用的開源框架對社區開放。其中有三個尤其引起了我的注意,你或許也會覺得有趣。
AllenNLP
AllenNLP 框架是基於 PyTorch 構建的平臺,可以在語義 NLP 任務中輕鬆使用 DL 方法。其目標是允許研究者設計和評估新模型。該框架包括語義角色標註、文字蘊涵和共指消解等常見語義 NLP 任務的模型參考實現。
ParlAI
ParlAI 框架是一個用於對話研究的開源軟件平臺。它使用 Python 實現,目標是提供用於共享、訓練和測試對話模型的統一框架。ParlAI 提供與亞馬遜土耳其機器人輕鬆集成的機制,它還提供該領域常用數據集,支持多個模型,包括記憶網絡、seq2seq 和注意力 LSTM 等神經網絡模型。
OpenNMT
OpenNMT 工具包是專用於序列到序列模型的通用框架,可用於執行機器翻譯、摘要、圖像到文本和語音識別等任務。
結語
不可否認,用於解決 NLP 問題的 DL 技術持續發展。一個重要指標就是近年深度學習論文在重要的 NLP 會議如 ACL、EMNLP、EACL、NAACL 上的比例。
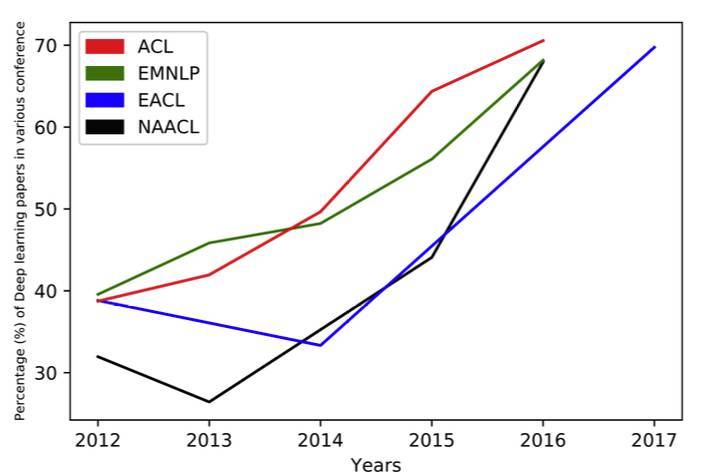
深度學習論文在 NLP 會議論文中的比例(圖像來源:https://arxiv.org/abs/1708.02709)。
但是,有關端到端學習的研究纔剛剛開始。我們仍然通過處理一些經典的 NLP 任務來準備數據集,如清洗、標記化(tokenization)或部分實體統一化(如 URL、數字、電子郵箱地址等)。我們還使用通用嵌入,缺點是它們無法捕捉特定領域術語的重要性,且對多詞表達的處理效果不好,這是我在過去項目中多次發現的重要問題。
2017 年是深度學習應用到 NLP 的偉大一年。我希望 2018 年能夠出現更多端到端學習方面的研究以及專門的開源框架變的更加完善。
擴展閱讀
NLP 研究中的深度學習方法:Recent Trends in Deep Learning Based Natural Language Processing,Young et al.(2017):https://arxiv.org/pdf/1708.02709.pdf
From Characters to Understanding Natural Language (C2NLU): Robust End-to-End Deep Learning for NLP,Blunsom et al.(2017):http://drops.dagstuhl.de/opus/volltexte/2017/7248/pdf/dagrep_v007_i001_p129_s17042.pdf
模型對比:Comparative Study of CNN and RNN for Natural Language Processing,Yin et al.(2017):https://arxiv.org/pdf/1702.01923.pdf
GAN 工作原理:The major advancements in Deep Learning in 2016,Pablo Soto:https://tryolabs.com/blog/2016/12/06/major-advancements-deep-learning-2016/
詞嵌入詳解:Word embeddings: how to transform text into numbers,Gabriel Mordecki:https://monkeylearn.com/blog/word-embeddings-transform-text-numbers/
Word embeddings in 2017: Trends and future directions,Sebastian Ruder:http://ruder.io/word-embeddings-2017/
參考文獻
From Characters to Understanding Natural Language (C2NLU): Robust End-to-End Deep Learning for NLP Phil Blunsom, Kyunghyun Cho, Chris Dyer and Hinrich Schütze (2017)
BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs Mathieu Cliche (2017)
Word Translation without Parallel Data Alexis Conneau, Guillaume Lample, Marc』Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (2018)
Generative adversarial nets Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville and Yoshua Bengio (2014)
Distributional structure Zellig Harris (1954)
OpenNMT: Open-source toolkit for neural machine translation Guillaume Klein, Yoon Kim, Yuntian Deng, Jean Senellart and Alexander M Rush. (2017)
Multiplicative lstm for sequence modelling Ben Krause, Liang Lu, Iain Murray and Steve Renals (2016)
Parlai: A dialog research software platform Alexander H Miller, Will Feng, Adam Fisch, Jiasen Lu, Dhruv Batra, Antoine Bordes, Devi Parikh and Jason Weston (2017)
Linguistic Regularities in Continuous Space Word Representations Tomas Mikolov, Scott Wen-tau Yih and Geoffrey Zweig (2013)
Glove: Global vectors for word representation Jeffrey Pennington, Richard Socher and Christopher D. Manning (2014)
Learning to Generate Reviews and Discovering Sentiment Alec Radford, Rafal Jozefowicz and Ilya Sutskever (2017)
A Simple Regularization-based Algorithm for Learning Cross-Domain Word Embeddings Wei Yang, Wei Lu, Vincent Zheng (2017)
Comparative study of CNN and RNN for Natural Language ProcessingWenpeng Yin, Katharina Kann, Mo Yu and Hinrich Schütze (2017)
Recent Trends in Deep Learning Based Natural Language Processing Tom Younga, Devamanyu Hazarikab, Soujanya Poriac and Erik Cambriad (2017)
原文鏈接:https://tryolabs.com/blog/2017/12/12/deep-learning-for-nlp-advancements-and-trends-in-2017/