選自Kdnuggets
作者:Lars Hulstaert
參與:晏奇、李澤南
本文面向稍有經驗的機器學習開發者,來自微軟的 Lars Hulstaert 在文中爲我們介紹了訓練神經網絡的幾種目標函數。
介紹
本文的寫作動機有以下三個方面:
首先,目前有很多文章都在介紹優化方法,比如如何對隨機梯度下降進行優化,或是提出一個該方法的變種,很少有人會解釋構建神經網絡目標函數的方法。會去回答這樣的問題:爲什麼將均方差(MSE)和交叉熵損失分別作爲迴歸和分類任務的目標函數?爲什麼增加一個正則項是有意義的?所以,寫作這篇博文的意義在於,通過對目標函數的考察,人們可以理解神經網絡工作的原理,同時也就可以理解它們爲何在其他領域卻無法發揮作用。
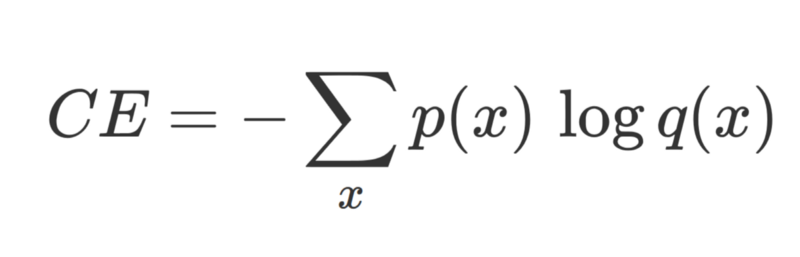
在分類任務中,(監督學習中)正確的標註 p(ground truth)與網絡輸出 q 之間的交叉熵損失。
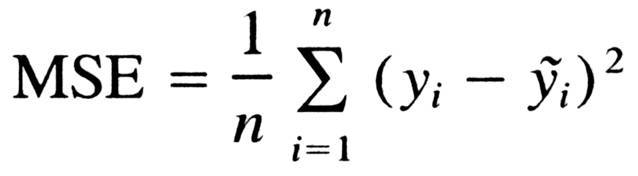
在迴歸任務中,(監督學習中)正確的標註 y 與網絡輸出 y_tilde 之間的均方差。
其次,神經網絡作出錯誤概率預測是出了名的,並且,面對對抗性樣本(adversarial example,即一種特殊的輸入數據,它們由研究人員專門設計,用來讓神經網絡作出錯誤預測)它們也毫無辦法。總之,神經網絡經常過度自信,甚至當它們判斷錯誤時也這樣。這個問題在真實環境中可不容忽視,以自動駕駛爲例,一輛自動駕駛汽車要保證在 145km/h 的行駛速度下還能做出正確的決定。所以,如果我們要大規模應用深度學習,我們不僅要認識其優點,還要知道其缺點。
一直以來,我都想明白爲何神經網絡可以從概率的角度來加以解釋,以及它們爲什麼適合作爲廣義的機器學習模型框架。人們喜歡把網絡的輸出作爲概率來討論。那麼,神經網絡的概率解釋與其目標函數之間是否存在聯繫呢?
寫作這篇文章的靈感來源於作者和其朋友 Brian Trippe 在劍橋大學計算與生物學習實驗室工作期間對貝葉斯神經網絡的研究,作者高度推薦讀者朋友閱讀其朋友 Brian 關於神經網絡中變分推理的論文《Complex Uncertainty in Machine Learning: Bayesian Modeling for Conditional Density Estimation and Synaptic Plasticity》。
監督學習
在監督學習問題中,我們一般會有一個數據集 D,x 是其中的樣本,y 是樣本標籤,我們用(x, y)的方式來表示樣本,我們要做的,是對 P(y | x, θ) 這個條件概率分佈進行建模。
舉個例子,在圖像分類任務中,x 表示一個圖像,y 表示與之對應的圖像標籤。P(y | x, θ) 表示:在圖像 x 和一個由參數θ定義的模型下,出現標籤 y 的概率。
按照這種方法建立的模型被稱爲判別式模型(discriminative model)。在判別式或條件模型中,定義條件概率分佈函數 P(y|x, θ) 的參數θ是從訓練集中推出的。
基於觀察數據 x(輸入數據或特徵值),模型輸出一個概率分佈,之後會用這個分佈來預測標籤 y(類別或真值)。不同的機器學習模型要求預測不同的參數。對於線性模型(如:邏輯迴歸,由一系列值等於特徵數量的權重來定義)與非線性模型(如:神經網絡,由其每一層的一系列權重所定義)而言,這兩類模型都可以近似等於條件概率分佈。
對於典型的分類問題而言,(一系列可被學習的)參數θ用作定義一個 x 到範疇分佈(它們基於不同的標籤)的映射。一個判別式模型會將概率 N(N 等於類的數量)作爲輸出。每個 x 都屬於一個單獨的類,但是模型的不確定性是由在類上輸出的一個分佈來反映的。一般來說,概率最大的類會在做出決定的時候被選擇。

在圖像分類中,網絡會基於圖像類別輸出一個範疇分佈。上圖描述了一張測試圖像中的前五個類(以概率大小爲標準篩選)。
我們注意到,判別式迴歸模型(discriminative regression model)經常只會輸出一個預測值,而不是一個基於所有真值的分佈。這與判別式分類模型(discriminative classification model)不同,後者會輸出一個基於可能的類的分佈。那麼這是否意味着判別式模型因迴歸任務而瓦解了呢?模型的輸出難道不應該告訴我們哪些迴歸值(regression value)會比其它值更有可能嗎?
說判別式迴歸模型只有一個輸出其實會讓人誤解,實際上,一個迴歸模型的輸出與一個著名的概率分佈有關:高斯分佈。事實證明,判別式迴歸模型的輸出代表了一個高斯分佈的均值(一個高斯分佈完全由一個均值與標準差決定)。有了這個信息,你就可以在輸入*x*的情況下決定每個真值的相似度了。
通常,只有這個分佈的均值纔會建模,高斯分佈的標準差要麼沒有建模,要麼就是在所有 x 上保持一個常值(constant)。因此,在判別式迴歸模型中,θ規定了從 x 到高斯分佈(y 從中取樣得來)均值的一個映射。基本上每當要做出決定時,我們都會選擇均值,因爲模型能夠通過提高標準差來表達哪個 x 是不確定的。
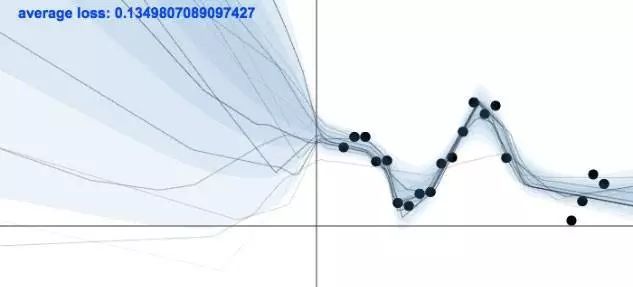
當沒有訓練數據的時候,一個模型是需要保持不確定的,相反,當有訓練數據的時候,模型需要變得確定。上圖展示了這樣的一個模型,圖片來自 Yarin Gal 的博文。
在迴歸問題裏,其他的概率模型(比如高斯過程)在對不確定性進行建模的過程中效果好得多。因爲當要同時對均值與標準差建模的時候,判別式迴歸模型會有過於自信的傾向。
高斯過程(Gaussian process)可以通過對標準差精確建模來量化不確定性。其僅有的一個缺點在於,高斯過程不能很好地擴大到大型數據集。在下圖中你可以看到,GP 模型在具有大量數據的區域周圍置信區間很小。在數據點很少的區域,置信區間又變得很大。
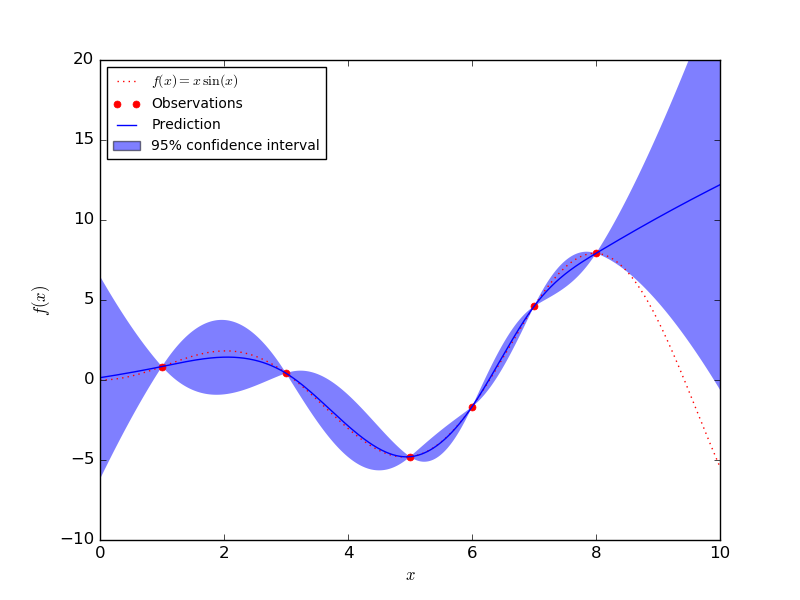
GP 模型在數據點上是確定的,但是在其他地方是不確定的(圖片來自 Sklearn)。
通過在訓練集上訓練,判別式模型可以學習數據(代表了一個類或是真值)中的特徵。如果一個模型能夠將高概率賦給正確地的樣本類,或是一個接近測試集中真值(true value)的均值(mean),那麼我們說這個模型表現的不錯。
鏈接神經網絡
當用神經網絡來進行分類或迴歸任務時,上述提到的參數分佈(範疇分佈與高斯分佈)的建模就通過神經網絡來完成。
這一點在當我們要決定神經網絡參數θ的最大似然估計(MLE)的時候比較清楚。MLE 相當於找到訓練數據集似然度(或等效對數似然度)最大時的參數θ。更具體的來說,下圖的表述得到了最大化:
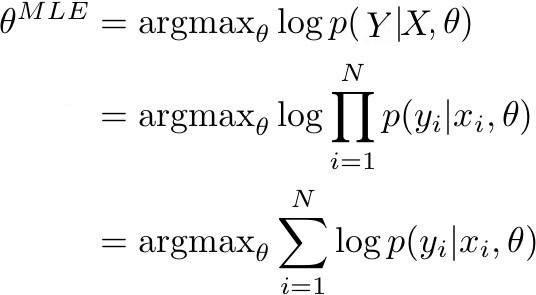
當 p(Y | X, θ) 由模型確定時,它表示了訓練數據中真實標籤的概率。如果 p(Y | X, θ) 接近於 1,這意味着模型能夠確定訓練集中正確的標籤/均值。在給定由 N 個觀察對組成的訓練數據(X,Y)的條件下,訓練數據的似然度可被改寫成對數概率的總和。
在分類與迴歸的情況下,p(y|x, θ) 作爲一個(x, y)的後驗概率,可以被改寫成範疇分佈和高斯分佈。在優化神經網絡的情況下,目標則是去改變參數,具體方式是:對於一系列輸入 X,概率分佈 Y 的正確的參數可以在輸出(迴歸值或類)中得到。一般這可以通過梯度下降和其變體來實現。因此,爲了得到一個 MLE 估計,我們的目標是優化關於真實輸出的模型輸出:
最大化一個範疇分佈的對數值相當於最小化真實分佈與其近似分佈的交叉熵。
最大化高斯分佈的對數值相當於最小化真實均值與其近似均值的均方差。
因此,前述圖片中的表達就可以被改寫,分別變成交叉熵損失和均方差,以及分類和迴歸的神經網絡的目標函數。
相較於更加傳統的概率模型,神經網絡從輸入數據到概率或是均數習得的非線性函數難以被解釋。雖然這是神經網絡的一個顯著的缺點,但是其可以模擬大量複雜函數的能力也帶來了極高的好處。根據這部分衍生討論的內容,我們可以明顯看到,神經網絡的目標函數(在確定參數的 MLE 似然度過程中形成)可以以概率的方式來解釋。
神經網絡一個有趣的解釋與它和那些一般的線性模型(線性迴歸、邏輯迴歸)的關係有關。相比於選擇特徵的線性組合(就像在 GLM 做的一樣),神經網絡會產生一個高度非線性的特徵組合。
最大後驗概率(MAP)
但是如果神經網絡可以被解釋成概率模型,那爲什麼它們給出的概率預測質量很差,而且還不能處理那些對抗性樣本呢?爲什麼它們需要這麼多數據?
在選擇好的函數逼近器時,根據不同的搜索空間我傾向於選擇不同的模型(邏輯迴歸,神經網絡等等)。當面對一個極大的搜索空間,也即意味着你可以很靈活地模擬後驗概率時,依然是有代價的。比如,神經網絡被證明是一個通用的函數逼近器。也就是說只要有足夠的參數,它們就可以模擬任何函數。然而,爲了保證函數在整個數據空間上能夠得到很好的校準,一定需要極大的數據集才行。
通常,一個標準的神經網絡都會使用 MLE 來進行優化,知道這一點很重要。使用 MLE 進行優化可能會讓模型發生過擬合,所以模型需要大量數據來讓過擬合問題減弱。機器學習的目標不是去尋找一個對訓練數據解釋度最好的模型。我們更需要的是找到一個可以在訓練集外的數據上也有很好泛化能力的模型。
在這裏,最大後驗概率(MAP)方法是一個有效的可選方案,當概率模型遭遇過擬合問題時我們經常會使用它。所以 MAP 相當於神經網絡的語境下的什麼呢?對於目標函數它會有什麼影響呢?
與 MLE 類似,MAP 也可以在神經網絡的語境下被改寫成一個目標函數。就本質而言,使用了 MAP 你就是在最大化一系列參數θ(給定數據下,在θ上假設一個先驗概率分佈)的概率:
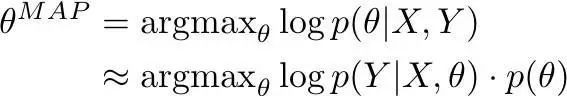
使用 MLE 時,我們只會考慮方程的第一個元素(模型在何種程度上解釋了訓練數據)。使用了 MAP,爲了降低過擬合,模型滿足先驗概率也很重要(θ在何種程度上滿足先驗概率)。
對θ使用均值爲 0 的高斯先驗概率與把 L2 正則化應用到目標函數上是一致的(確保了有很多小權重),然而在θ上使用一個拉普拉斯先驗概率與把 L1 正則化應用到目標函數上是一致的(確保很多權重的值爲 0)。
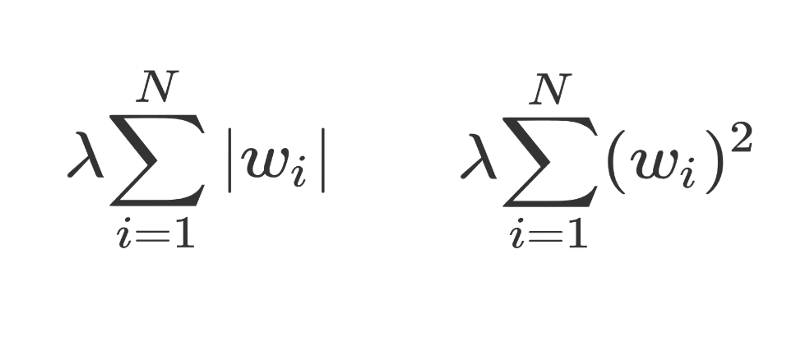
左邊是 L1 正則化,右邊是 L2 正則化。
一種完全貝葉斯方法
在 MLE 和 MAP 兩種情況中,都只使用了一個模型(它只有一組參數)。對於複雜的數據尤其如此,比如圖像,數據空間中特定的區域沒有被覆蓋這個問題不太可能出現。模型在這些地方的輸出由模型的隨機初始化與訓練過程決定,模型對處於數據空間覆蓋區域之外的點會給出很低的概率估計。
儘管 MAP 保證了模型在這些地方的過擬合程度不會太高,但是它還是會讓模型變得過於自信。在完全貝葉斯方法中,我們通過在多個模型上取平均值來解決這個問題,這樣可以得到更好的不確定性預測。我們的目標是模擬參數的一個分佈,而不是僅僅一組參數。如果所有的模型(不同參數設置)在覆蓋區域之外都給出了不同的預測,那麼這意味着這個區域有很大的不確定性。通過對這些模型取平均,最終我們會得到一個在那些區域不確定的模型,這正是我們想要的。
原文鏈接:https://www.kdnuggets.com/2017/11/understanding-objective-functions-neural-networks.html
本文爲機器之心編譯,轉載請聯繫本公衆號獲得授權。
責任編輯: