機器之心整理
參與:黃小天、蔣思源
前天,香港科技大學計算機系教授 Sung Kim 在 Google Drive 分享了一個 3 天速成的 TensorFlow 極簡入門教程;接着,他在 GitHub 上又分享了一個 3 至 4 日的速成教程,教大家如何使用 PyTorch 進行機器學習/深度學習。Sung Kim 共享了該教程的代碼和 PPT 資源,機器之心對其做了扼要介紹。資源鏈接請見文中。
代碼:https://github.com/hunkim/PyTorchZeroToAll
PPT:http://bit.ly/PyTorchZeroAll
百度雲盤:https://pan.baidu.com/s/1cpoyXw
PyTorch 開源於今年一月份,它是使用 GPU 和 CPU 優化的深度學習張量庫,也是一個 Python 工具包,爲目前最流行的深度學習框架之一;它具有兩個高階功能:
帶有強大的 GPU 加速的張量計算(類似 NumPy)
構建在基於 tape 的 autograd 系統之上的深度神經網絡
因此必要之時你可以再利用 Python 工具包比如 NumPy、SciPy 和 Cython 擴展 PyTorch。PyTorch 目前處於早期的 beta 版,還有待進一步完善與更新。通常來講,PyTorch 作爲庫主要包含以下組件:
1. Torch:類似於 NumPy 的張量庫,帶有強大的 GPU 支持
2. torch.autograd:一個基於 tape 的自動微分庫,支持 torch 中的所有的微分張量運算
3. torch.nn:一個專爲最大靈活性而設計、與 autograd 深度整合的神經網絡庫
4. torch.multiprocessing:Python 多運算,但在運算中帶有驚人的 torch 張量內存共享。這對數據加載和 Hogwild 訓練很有幫助。
5. torch.utils:數據加載器、訓練器以及其他便利的實用功能
6. torch.legacy(.nn/.optim):出於後向兼容性原因而從 torch 移植而來的舊代碼
人們使用 PyTorch 一般出於兩個目的:
代替 NumPy 從而可以使用強大的 GPU
PyTorch 作爲深度學習研究平臺提供了最大的靈活性與速度
PyTorch 是由若干個資深工程師和研究者共同發起的社區項目,目前主要的維護人員有 Adam Paszke、Sam Gross、Soumith Chintala 和 Gregory Chanan。
PyTorch 課程目錄
概覽
線性模型
梯度下降
反向傳播
PyTorch 線性迴歸
Logistic 迴歸
寬&深
數據加載器
Softmax 分類器
CNN
RNN
下面是整個課程的概述:
線性模型
如下爲線性模型的基本思想,我們希望能構建一個線性方程擬合現存的數據點。該線性了方程函數將根據數據點與其距離自動調整權重,權重調整的方法即使用優化算法最小化真實數據與預測數據的距離。
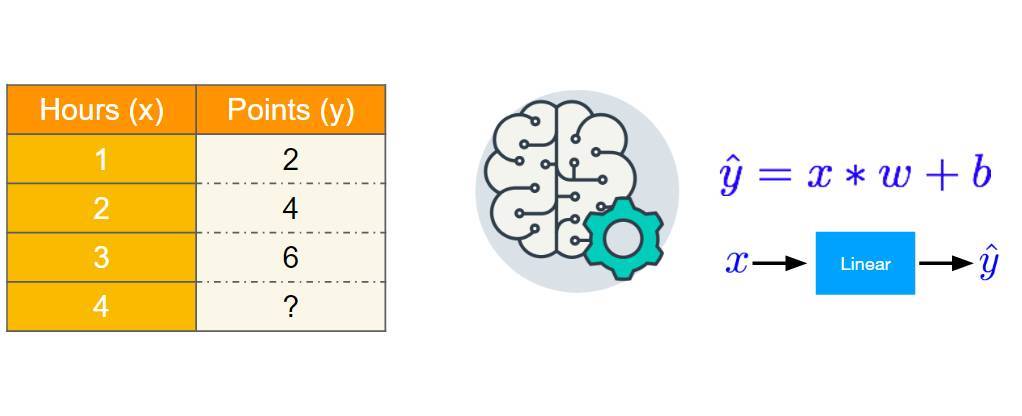
以下爲該線性模型的實現代碼,我們先定義特徵 x 與標註 y,然後將預測值與真實值差的平方作爲損失函數。隨後初始化模型權重並開始前向傳播。
importnumpy asnp
importmatplotlib.pyplot asplt
x_data =[1.0,2.0,3.0]
y_data =[2.0,4.0,6.0]
# our model forward pass
defforward(x):
returnx *w
# Loss function
defloss(x,y):
y_pred =forward(x)
return(y_pred -y)*(y_pred -y)
w_list =[]
mse_list =[]
forw innp.arange(0.0,4.1,0.1):
print("w=",w)
l_sum =0
forx_val,y_val inzip(x_data,y_data):
y_pred_val =forward(x_val)
l =loss(x_val,y_val)
l_sum +=l
print("t",x_val,y_val,y_pred_val,l)
print("NSE=",l_sum /3)
w_list.append(w)
mse_list.append(l_sum /3)
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
梯度下降
梯度下降在最優化中又稱之爲最速下降算法,以下爲該算法的基本概念。我們可以看到,若我們希望最小化的損失函數爲凸函數,那麼損失函數對各個權重的偏導數將指向該特徵的極小值。如下當初始權重處於損失函數遞增部分時,那麼一階梯度即損失函數在該點的斜率,且遞增函數的斜率爲正,那麼當前權重減去一個正數將變小,因此權重將沿遞增的反方向移動。同理可得當權重處於遞減函數的情況。
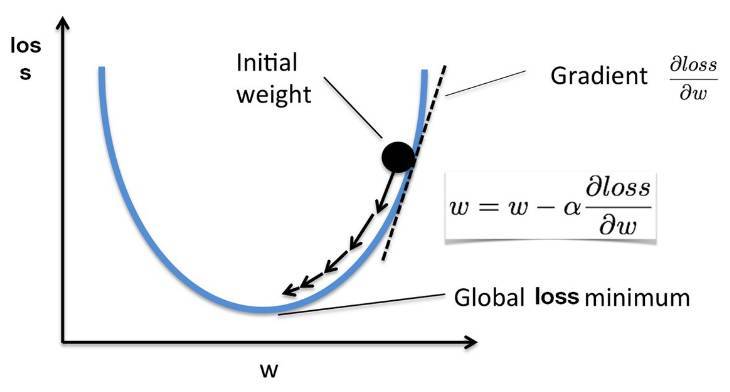
如下我們手動實現了簡單的梯度下降算法。前面還是先定義模型、損失函數,因爲我們已知損失函數的結構,那麼就可以手動對其求導以確定梯度函數的結構。得出了權重梯度的表達式後可以將其代入權重更新的循環語句以定義訓練。
x_data =[1.0,2.0,3.0]
y_data =[2.0,4.0,6.0]
w =1.0# any random value
# our model forward pass
defforward(x):
returnx *w
# Loss function
defloss(x,y):
y_pred =forward(x)
return(y_pred -y)*(y_pred -y)
# compute gradient
defgradient(x,y):# d_loss/d_w
return2*x *(x *w -y)
# Before training
print("predict (before training)",4,forward(4))
# Training loop
forepoch inrange(10):
forx_val,y_val inzip(x_data,y_data):
grad =gradient(x_val,y_val)
w =w -0.01*grad
print("tgrad: ",x_val,y_val,grad)
l =loss(x_val,y_val)
print("progress:",epoch,l)
# After training
print("predict (after training)",4,forward(4))
反向傳播
下圖展示了反向傳播算法的鏈式求導法則與過程。對於反向傳播來說,給定權重下,我們先要計算前向傳播的結果,然後計算該結果與真實值的距離或誤差。隨後將該誤差沿誤差產生的路徑反向傳播以更新權重,在這個過程中誤差會根據求導的鏈式法則進行分配。
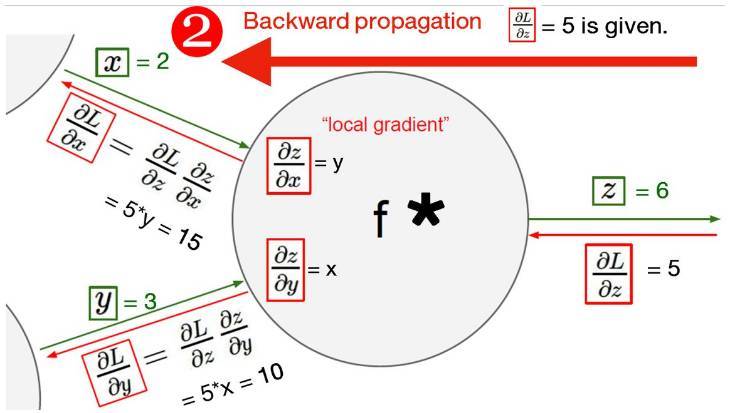
以下代碼實現了反向傳播算法,我們可以看到在 PyTorch 中反向傳播的語句爲「loss(x_val, y_val).backward()」,即將損失函數沿反向傳播。
importtorch
fromtorch importnn
fromtorch.autograd importVariable
x_data =[1.0,2.0,3.0]
y_data =[2.0,4.0,6.0]
w =Variable(torch.Tensor([1.0]),requires_grad=True)# Any random value
# our model forward pass
defforward(x):
returnx *w
# Loss function
defloss(x,y):
y_pred =forward(x)
return(y_pred -y)*(y_pred -y)
# Before training
print("predict (before training)",4,forward(4).data[0])
# Training loop
forepoch inrange(10):
forx_val,y_val inzip(x_data,y_data):
l =loss(x_val,y_val)
l.backward()
print("tgrad: ",x_val,y_val,w.grad.data[0])
w.data =w.data -0.01*w.grad.data
# Manually zero the gradients after updating weights
w.grad.data.zero_()
print("progress:",epoch,l.data[0])
# After training
print("predict (after training)",4,forward(4).data[0])
PyTorch 線性迴歸
定義數據:
importtorch
fromtorch.autograd importVariable
x_data =Variable(torch.Tensor([[1.0],[2.0],[3.0]]))
y_data =Variable(torch.Tensor([[2.0],[4.0],[6.0]]))
定義模型,在 PyTorch 中,我們可以使用高級 API 來定義相關的模型或層級。如下定義了「torch.nn.Linear(1, 1)」,即一個輸入變量和一個輸出變量。
classModel(torch.nn.Module):
def__init__(self):
"""
In the constructor we instantiate two nn.Linear module
"""
super(Model,self).__init__()
self.linear =torch.nn.Linear(1,1)# One in and one out
defforward(self,x):
"""
In the forward function we accept a Variable of input data and we must return
a Variable of output data. We can use Modules defined in the constructor as
well as arbitrary operators on Variables.
"""
y_pred =self.linear(x)
returny_pred
構建損失函數和優化器,構建損失函數也可以直接使用「torch.nn.MSELoss(size_average=False)」調用均方根誤差函數。優化器可以使用「torch.optim.SGD()」提到用隨機梯度下降,其中我們需要提供優化的目標和學習率等參數。
# Construct our loss function and an Optimizer. The call to model.parameters()
# in the SGD constructor will contain the learnable parameters of the two
# nn.Linear modules which are members of the model.
criterion =torch.nn.MSELoss(size_average=False)
optimizer =torch.optim.SGD(model.parameters(),lr=0.01)
訓練模型,執行前向傳播計算損失函數,並優化參數:
# Training loop
forepoch inrange(500):
# Forward pass: Compute predicted y by passing x to the model
y_pred =model(x_data)
# Compute and print loss
loss =criterion(y_pred,y_data)
print(epoch,loss.data[0])
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
loss.backward()
optimizer.step()
Logistic 迴歸
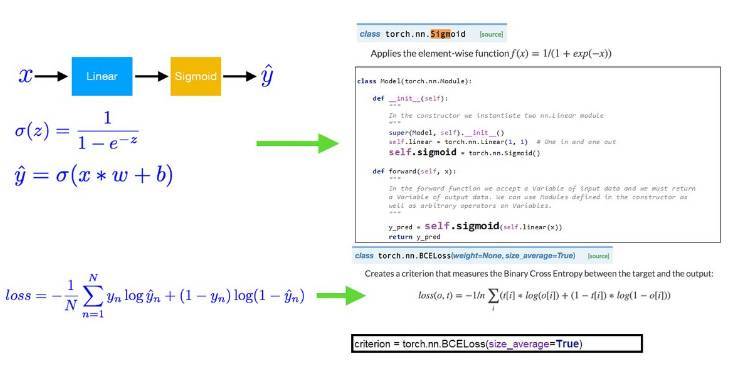
以下展示了 Logistic 迴歸的基本要素和對應代碼。Logistic 迴歸的構建由以下三種函數組成:Sigmoid 函數、目標函數以及損失函數。下圖分別給出了三種函數的對應代碼。其中 Sigmoid 函數將線性模型演變爲 Logistic 迴歸模型,而損失函數負責創建標準以測量目標與輸出之間的二值交叉熵。
Softmax 分類
以下展示了 Softmax 分類的基本概念,其中最重要的是在最後一層使用了 Softmax 函數。我們可以使用 Softmax 函數將輸出值轉化爲和爲 1 的類別概率。
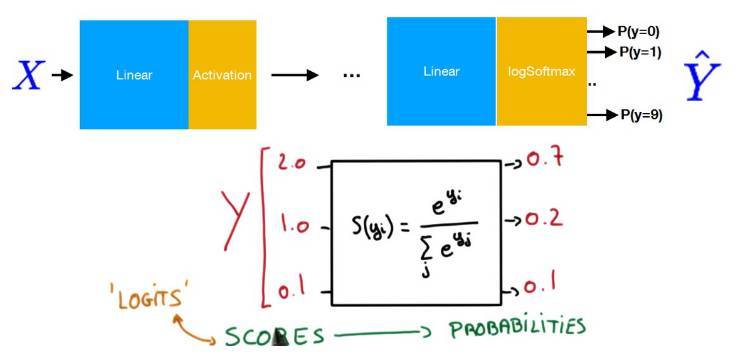
加載數據集與導入數據加載器:
# MNIST Dataset
train_dataset =datasets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset =datasets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader =torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader =torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
定義模型的架構,並選擇優化器。如下我們可以瞭解該 Softmax 分類模型在前面使用了五個全連接層,並在最後一層使用了 Softmax 函數。例如先使用「l1 = nn.Linear(784, 520)」定義全連接的輸入結點數與輸出結點數,784 爲 MNIST 的像素點數,再使用「F.relu(self.l1(x))」定義該全連接的激活函數爲 ReLU。
classNet(nn.Module):
def__init__(self):
super(Net,self).__init__()
self.l1 =nn.Linear(784,520)
self.l2 =nn.Linear(520,320)
self.l3 =nn.Linear(320,240)
self.l4 =nn.Linear(240,120)
self.l5 =nn.Linear(120,10)
defforward(self,x):
x =x.view(-1,784)# Flatten the data (n, 1, 28, 28)-> (n, 784)
x =F.relu(self.l1(x))
x =F.relu(self.l2(x))
x =F.relu(self.l3(x))
x =F.relu(self.l4(x))
x =F.relu(self.l5(x))
returnF.log_softmax(x)
model =Net()
optimizer =optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
CNN
下圖展示了一個簡單的卷積神經網絡,它由輸入層、卷積層 1、池化層 1、卷積層 2、池化層 2、全連接層組成。其中卷積層 1、2 是二維的,其輸入通道爲 1,輸出通道爲 10,卷積核大小爲 5。其中池化層採用的是最大池化運算。
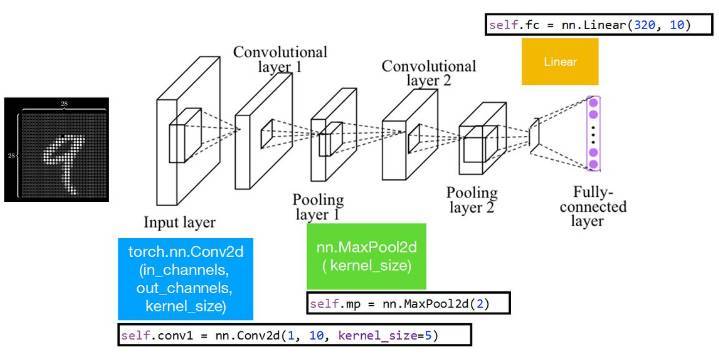
以下是上圖簡單卷積神經網絡的加載數據:
# MNIST Dataset
train_dataset =datasets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset =datasets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader =torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader =torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
以下代碼定義了上圖卷積神經網絡的架構,並定義了優化器。我們同樣可以使用高級 API 添加捲積層,例如「nn.Conv2d(1, 10, kernel_size=5)」可以添加捲積核爲 5 的卷積層。此外,在卷積層與全連接層之間,我們需要壓平張量,這裏使用的是「x.view(in_size, -1)」。
classNet(nn.Module):
def__init__(self):
super(Net,self).__init__()
self.conv1 =nn.Conv2d(1,10,kernel_size=5)
self.conv2 =nn.Conv2d(10,20,kernel_size=5)
self.mp =nn.MaxPool2d(2)
self.fc =nn.Linear(320,10)
defforward(self,x):
in_size =x.size(0)
x =F.relu(self.mp(self.conv1(x)))
x =F.relu(self.mp(self.conv2(x)))
x =x.view(in_size,-1)# flatten the tensor
x =self.fc(x)
returnF.log_softmax(x)
model =Net()
optimizer =optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
本文爲機器之心整理,轉載請聯繫本公衆號獲得授權。
責任編輯: