
相關 Jupyter Notebook 地址:https://github.com/huggingface/100-times-faster-nlp
去年我們發佈 Python 包 coreference resolution package 後,我們收到了來自社區的精彩反饋,並且人們開始在很多應用中使用它,其中一些與我們原來的對話用例迥異。
我們發現,儘管對話信息的處理速度非常好,但對於長的新聞文章來說,處理速度可能會非常慢。
我決定詳細研究這一問題,最終成果即 NeuralCoref v3.0,它在相同準確率的情況下比老版本快 100 倍左右(每秒幾千字),同時兼顧 Python 庫的易用性和兼容性。
NeuralCoref v3.0 :https://github.com/huggingface/neuralcoref/
我想在這篇文章中分享一些關於這個項目的經驗,特別是:
如何用 Python 設計一個高速模塊;
如何利用 spaCy 的內部數據結構來有效地設計超高速 NLP 函數。
所以我在這裏有點作弊,因爲我們會談論 Python,但也談論一些 Cython 的神奇作用。但是,你知道嗎?Cython 是 Python 的超集,所以不要讓它嚇跑你!
你現在的 Python 程序已經是 Cython 程序。
有幾種情況下你可能需要加速,例如:
你正在使用 Python 開發一個 NLP 的生產模塊;
你正在使用 Python 計算分析大型 NLP 數據集;
你正在爲深度學習框架,如 PyTorch / TensorFlow,預處理大型訓練集,或者你的深度學習批處理加載器中的處理邏輯過於繁重,這會降低訓練速度。
再強調一遍:我同步發佈了一個 Jupyter Notebook,其中包含我在本文中討論的例子。試試看!
Jupyter Notebook:https://github.com/huggingface/100-times-faster-nlp
加速第一步:剖析

首先要知道的是,你的大多數代碼在純 Python 環境中可能運行的不錯,但是如果你多用點心,其中一些瓶頸函數可能讓你的代碼快上幾個數量級。
因此,你首先應該分析你的 Python 代碼並找出瓶頸部分的位置。使用如下的 cProfile 是一種選擇:
import cProfile import pstats import myslowmodule cProfile.run('myslowmodule.run()', 'restats') p = pstats.Stats('restats') p.sortstats('cumulative').printstats(30)如果你使用神經網絡,你可能會發現瓶頸部分是幾個循環,並且涉及 Numpy 數組操作。
那麼,我們如何加速這些循環代碼?
在 Python 中使用一些 Cython 加速循環
讓我們用一個簡單的例子來分析這個問題。假設我們有一大堆矩形,並將它們存儲進一個 Python 對象列表,例如 Rectangle 類的實例。我們的模塊的主要工作是迭代這個列表,以便計算有多少矩形的面積大於特定的閾值。
我們的 Python 模塊非常簡單,如下所示:
from random import randomclass Rectangle: def __init__(self, w, h): self.w = w self.h = h def area(self): return self.w * self.hdef check_rectangles(rectangles, threshold): n_out = 0 for rectangle in rectangles: if rectangle.area() > threshold: n_out += 1 return n_outdef main(): n_rectangles = 10000000 rectangles = list(Rectangle(random(), random()) for i in range(n_rectangles)) n_out = check_rectangles(rectangles, threshold=0.25) print(n_out)check_rectangles 函數是瓶頸部分!它對大量的 Python 對象進行循環,這可能會很慢,因爲 Python 解釋器在每次迭代時都會做大量工作(尋找類中的求面積方法、打包和解包參數、調用 Python API ...)。
Cython 將幫助我們加速循環。
Cython 語言是 Python 的超集,它包含兩種對象:
Python 對象是我們在常規 Python 中操作的對象,如數字、字符串、列表、類實例...
Cython C 對象是 C 或 C ++ 對象,比如 double、int、float、struct、vectors。這些可以由 Cython 在超快速的底層代碼中編譯。
快速循環只是 Cython 程序(只能訪問 Cython C 對象)中的一個循環。
設計這樣一個循環的直接方法是定義 C 結構,它將包含我們在計算過程中需要的所有要素:在我們的例子中,就是矩形的長度和寬度。
然後,我們可以將矩形列表存儲在這種結構的 C 數組中,並將這個數組傳遞給我們的 check_rectangle 函數。此函數現在接受一個 C 數組作爲輸入,因此通過 cdef 關鍵字而不是 def 將其定義爲 Cython 函數(請注意,cdef 也用於定義 Cython C 對象)。
下面是我們的 Python 模塊的快速 Cython 版:
from cymem.cymem cimport Poolfrom random import randomcdef struct Rectangle: float w float hcdef int check_rectangles(Rectangle* rectangles, int n_rectangles, float threshold): cdef int n_out = 0 # C arrays contain no size information => we need to give it explicitly for rectangle in rectangles[:n_rectangles]: if rectangles[i].w * rectangles[i].h > threshold: n_out += 1 return n_outdef main(): cdef: int n_rectangles = 10000000 float threshold = 0.25 Pool mem = Pool() Rectangle* rectangles = <Rectangle*>mem.alloc(n_rectangles, sizeof(Rectangle)) for i in range(n_rectangles): rectangles[i].w = random() rectangles[i].h = random() n_out = check_rectangles(rectangles, n_rectangles, threshold) print(n_out)我們在這裏使用了原生 C 指針數組,但你也可以選擇其他選項,特別是 C ++ 結構,如向量、對、隊列等。在這個片段中,我還使用了 cymem 的便利的 Pool()內存管理對象,以避免必須手動釋放分配的 C 數組。當 Pool 由 Python 當做垃圾回收時,它會自動釋放我們使用它分配的內存。
spaCy API 的 Cython Conventions 是 Cython 在 NLP 中的實際運用的一個很好的參考。
spaCy:https://spacy.io
Cython Conventions:https://spacy.io/api/cython#conventions
讓我們試試這個代碼吧!
有很多方法可以測試、編譯和發佈 Cython 代碼!Cython 甚至可以直接用在 Python 這樣的 Jupyter Notebook 中。
Jupyter Notebook:http://cython.readthedocs.io/en/latest/src/reference/compilation.html#compiling-notebook
首先使用 pip install cython 安裝 Cython
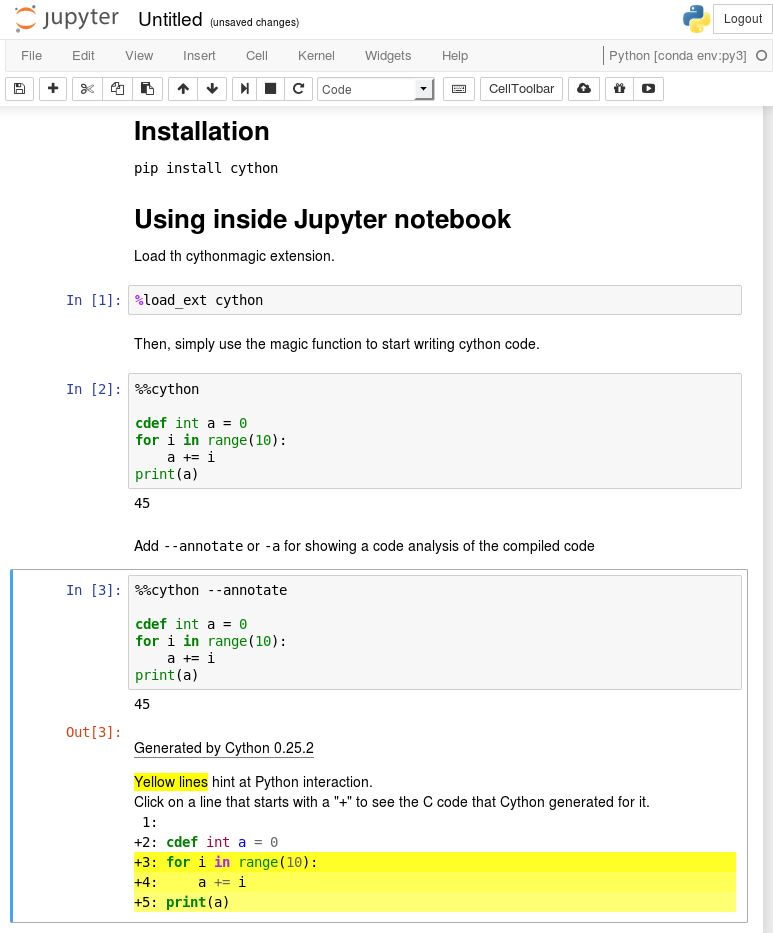
在 Jupyter 的第一次測試
使用 %load_ext Cython 將 Cython 插件加載到 Jupyter notebook 中。
現在,你可以使用黑魔術命令 %% cython 編寫像 Python 代碼一樣的 Cython 代碼。
如果在執行 Cython 單元時遇到編譯錯誤,請務必檢查 Jupyter 終端輸出以查看完整的信息。
大多數情況下,在 %% cython 編譯爲 C ++(例如,如果你使用 spaCy Cython API)或者 import numpy(如果編譯器不支持 NumPy)之後,你會丟失 - + 標記。
正如我在開始時提到的,查看這篇文章的同步 Jupyter Notebook,該 Notebook 包含本文討論的所有示例。
編寫、使用和發佈 Cython 代碼
Cython 代碼寫在 .pyx 文件中。這些文件由 Cython 編譯器編譯爲 C 或 C ++ 文件,然後通過系統的 C 編譯器編譯爲字節碼文件。Python 解釋器可以使用字節碼文件。
你可以使用 pyximport 直接在 Python 中加載 .pyx 文件:
>>> import pyximport; pyximport.install()>>> import my_cython_module你還可以將你的 Cython 代碼構建爲 Python 包,並將其作爲常規 Python 包導入/發佈,詳見下方地址。這可能需要一些時間才能開始工作,尤其在全平臺上。如果你需要一個有效示例,spaCy』s install script 是一個相當全面的例子。
導入教程:http://cython.readthedocs.io/en/latest/src/tutorial/cython_tutorial.html#
Before we move to some NLP, let's quickly talk about the def, cdef and cpdef keywords, because they are the main things you need to grab to start using Cython.
在我們轉向 NLP 之前,讓我們先快速討論一下 def、cdef 和 cpdef 關鍵字,因爲它們是你開始使用 Cython 需要掌握的主要內容。
你可以在 Cython 程序中使用三種類型的函數:
Python 函數,用常用的關鍵字 def 定義。它們可作爲輸入和輸出的 Python 對象。也可以在內部同時使用 Python 和 C / C ++ 對象,並可以調用 Cython 和 Python 函數。
用 cdef 關鍵字定義的 Cython 函數。它們可以作爲輸入,在內部使用並輸出 Python 和 C / C ++對象。這些函數不能從 Python 空間訪問(即 Python 解釋器和其他可導入 Cython 模塊的純 Python 模塊),但可以由其他 Cython 模塊導入。
用 cpdef 關鍵字定義的 Cython 函數就像 cdef 定義的 Cython 函數一樣,但它們也提供了一個 Python 封裝器,因此可以從 Python 空間(以 Python 對象作爲輸入和輸出)以及其他 Cython 模塊(以 C / C ++ 或 Python 對象作爲輸入)中調用它們。
cdef 關鍵字有另一種用途,即在代碼中定義 Cython C / C ++ 對象。除非用這個關鍵字定義對象,否則它們將被視爲 Python 對象(因此訪問速度很慢)。
使用 Cython 與 spaCy 來加速 NLP
這些東西又好又快,但是...... 我們現在還沒有融入 NLP!沒有字符串操作、沒有 unicode 編碼,也沒有我們在自然語言處理中幸運擁有的微妙聯繫。
官方的 Cython 文檔甚至建議不要使用 C 字符串:
一般來說:除非你知道自己在做什麼,否則應儘可能避免使用 C 字符串,而應使用 Python 字符串對象。
那麼我們如何在使用字符串時在 Cython 中設計快速循環?
spaCy 會幫我們的。
spaCy 解決這個問題的方式非常聰明。
將所有字符串轉換爲 64 位哈希碼
spaCy 中的所有 unicode 字符串(token 的文本、其小寫文本、引理形式、POS 鍵標籤、解析樹依賴關係標籤、命名實體標籤...)都存儲在叫 StringStore 的單數據結構中,它們在裏面由 64 位散列索引,即 C uint64_t。
StringStore 對象實現了 Python unicode 字符串和 64 位哈希碼之間的查找表。
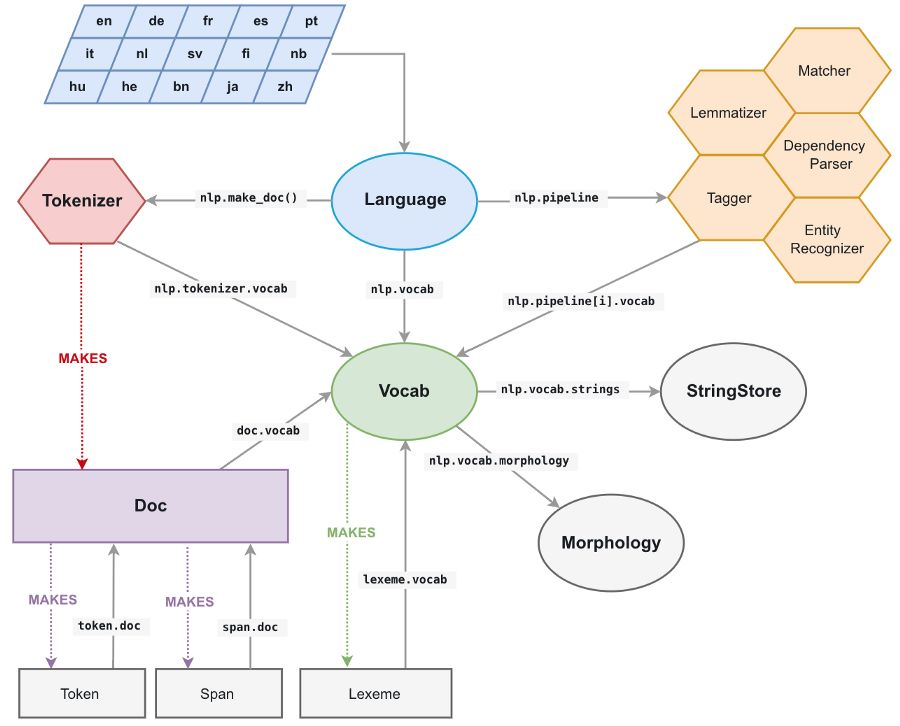
它可以通過 spaCy 任意處及任意對象訪問(請參閱上圖),例如 nlp.vocab.strings、doc.vocab.strings 或 span.doc.vocab.string。
當某個模塊需要對某些 token 執行快速處理時,僅使用 C 級別的 64 位哈希碼而不是字符串。調用 StringStore 查找表將返回與哈希碼相關聯的 Python unicode 字符串。
但是,spaCy 做的遠不止這些,它使我們能夠訪問文檔和詞彙表的完全覆蓋的 C 結構,我們可以在 Cython 循環中使用這些結構,而不必自定義結構。
spaCy 的內部數據結構
與 spaCy Doc 對象關聯的主要數據結構是 Doc 對象,該對象擁有已處理字符串的 token 序列(「單詞」)以及 C 對象中的所有稱爲 doc.c 的標註,它是一個 TokenC 結構數組。
TokenC 結構包含我們需要的關於每個 token 的所有信息。這些信息以 64 位哈希碼的形式存儲,可以重新關聯到 unicode 字符串,就像我們剛剛看到的那樣。
要深入瞭解這些 C 結構中的內容,只需查看剛創建的 SpaCy 的 Cython API doc。
我們來看看一個簡單的 NLP 處理示例。
使用 spaCy 和 Cython 進行快速 NLP 處理
假設我們有一個需要分析的文本數據集
import urllib.requestimport spacywith urllib.request.urlopen('https://raw.githubusercontent.com/pytorch/examples/master/word_language_model/data/wikitext-2/valid.txt') as response:text = response.read()nlp = spacy.load('en')doc_list = list(nlp(text[:800000].decode('utf8')) for i in range(10))我在左邊寫了一個腳本,它生成用於 spaCy 解析的 10 份文檔的列表,每個文檔大約 170k 字。我們也可以生成每個文檔 10 個單詞的 170k 份文檔(比如對話數據集),但創建速度較慢,因此我們堅持使用 10 份文檔。
我們想要在這個數據集上執行一些 NLP 任務。例如,我們想要統計數據集中單詞「run」作爲名詞的次數(即用 spaCy 標記爲「NN」詞性)。
一個簡單明瞭的 Python 循環就可以做到:
def slow_loop(doc_list, word, tag): n_out = 0 for doc in doc_list: for tok in doc: if tok.lower_ == word and tok.tag_ == tag: n_out += 1 return n_outdef main_nlp_slow(doc_list): n_out = slow_loop(doc_list, 'run', 'NN') print(n_out)但它也很慢!在我的筆記本電腦上,這段代碼需要大約 1.4 秒才能得到結果。如果我們有一百萬份文件,則需要一天以上才能給出結果。
我們可以使用多線程,但在 Python 中通常不是很好的解決方案,因爲你必須處理 GIL。另外,請注意,Cython 也可以使用多線程!而且這實際上可能是 Cython 最棒的部分,因爲 GIL 被釋放,我們可以全速運行。Cython 基本上直接調用 OpenMP。
現在我們嘗試使用 spaCy 和部分 Cython 加速我們的 Python 代碼。
首先,我們必須考慮數據結構。我們將需要一個 C 數組用於數據集,指針指向每個文檔的 TokenC 數組。我們還需要將我們使用的測試字符串(「run」和「NN」)轉換爲 64 位哈希碼。
當我們所需的數據都在 C 對象中時,我們可以在數據集上以 C 的速度進行迭代。
下面是如何使用 spaCy 在 Cython 中編寫的示例:
%%cython -+import numpy # Sometime we have a fail to import numpy compilation error if we don't import numpyfrom cymem.cymem cimport Poolfrom spacy.tokens.doc cimport Docfrom spacy.typedefs cimport hash_tfrom spacy.structs cimport TokenCcdef struct DocElement: TokenC* c int lengthcdef int fast_loop(DocElement* docs, int n_docs, hash_t word, hash_t tag): cdef int n_out = 0 for doc in docs[:n_docs]: for c in doc.c[:doc.length]: if c.lex.lower == word and c.tag == tag: n_out += 1 return n_outdef main_nlp_fast(doc_list): cdef int i, n_out, n_docs = len(doc_list) cdef Pool mem = Pool() cdef DocElement* docs = <DocElement*>mem.alloc(n_docs, sizeof(DocElement)) cdef Doc doc for i, doc in enumerate(doc_list): # Populate our database structure docs[i].c = doc.c docs[i].length = (<Doc>doc).length word_hash = doc.vocab.strings.add('run') tag_hash = doc.vocab.strings.add('NN') n_out = fast_loop(docs, n_docs, word_hash, tag_hash) print(n_out)代碼有點長,因爲我們必須在調用 Cython 函數之前在 main_nlp_fast 中聲明並填充 C 結構。(如果你在代碼中多次使用低級結構,使用 C 結構包裝的 Cython 擴展類型來設計我們的 Python 代碼是比每次填充 C 結構更優雅的選擇。這就是大多數 spaCy 的結構,它是一種結合了快速,低內存以及與外部 Python 庫和函數接口的簡便性的非常優雅的方法。)
但它也快很多!在我的 Jupyter Notebook 中,這個 Cython 代碼的運行時間大約爲 20 毫秒,比我們的純 Python 循環快大約 80 倍。
Jupyter Notebook cell 中編寫的模塊的絕對速度同樣令人印象深刻,並且可以爲其他 Python 模塊和函數提供本地接口:在 30ms 內掃描約 1,700 萬字意味着我們每秒處理高達 8000 萬字。
我們這就結束了使用 Cython 進行 NLP 的快速介紹。我希望你喜歡它。
Cython 還有很多其他的東西可講,但這會讓我們遠離主題。從現在開始,最好的地方可能就是 Cython tutorials 的概述和適用於 NLP 的 spaCy’s Cython page。
原文鏈接:https://medium.com/huggingface/100-times-faster-natural-language-processing-in-python-ee32033bdced