選自arXiv
參與:路雪、黃小天
鑑於目前注意力機制方法在場景文本識別中表現欠佳,近日,海康威視、復旦大學與上海交通大學等在 arXiv 上聯合發表了一篇題爲《Focusing Attention: Towards Accurate Text Recognition in Natural Images》的論文,其中提出了一種稱爲注意力聚焦網絡(FAN)的新方法,可有效對齊注意力與圖像中的目標區域,調整偏移注意力,成功解決了注意力漂移問題,從而顯著提升場景文本識別精確度。在不同基準(包括 IIIT5k、SVT 和 ICDAR 數據集)上進行的大量實驗表明 FAN 方法明顯優於現有方法。
場景文本識別(Scene text recognition)已引起計算機視覺領域人士的很大興趣。識別場景文本對場景理解意義重大。儘管光學字符識別(OCR)的研究已經進行了數十年,但是識別自然圖像中的文本仍然是一個挑戰。頂尖技術通過注意力機制識別字符,取得了顯著的性能提升。
通常情況下,基於注意力的文本識別器是編碼器-解碼器框架。在編碼階段,圖像通過 CNN/LSTM 轉換成特徵向量序列,每個特徵向量對應輸入圖像上的一個區域。本文中,我們將這類區域稱作注意力區域。在解碼階段,注意力網絡(AN)首先通過參照目標字符的歷史和用於生成合成向量(又叫 glimpse 向量)的編碼特徵向量計算對齊因子,這種方式可以使注意力區域與對應的真值標籤對齊。然後,使用循環神經網絡(RNN)根據 glimpse 向量和目標字符歷史生成目標字符。

圖 1. 複雜/低質量圖像的實例。子圖像 (a) 至 (f) 分別代表正常、複雜背景、模糊、不完整、字符大小不同和字體不正常的圖像。
動機。我們都知道真實的場景文本識別任務中存在很多複雜圖像(比如扭曲或重疊的字符,不同字體、大小、顏色的字符,以及複雜背景圖像等)或低質量圖像。圖 1 展示了複雜/低質量圖像的實例。對於這類圖像,現有的基於注意力的方法通常表現不佳。我們在真實數據上仔細分析了基於注意力方法的很多中間結果和最終結果,發現表現不佳的一個主要原因是注意力模型評估的對齊很容易因爲圖像的複雜性和/或低質量而受到損壞。換言之,注意力模型無法將每一個特徵向量和輸入圖像中對應的目標區域準確對齊。我們將這種現象叫作注意力漂移(attention drift),即 AN 的注意力區域一定程度上偏離圖像中目標字符的確切位置。這促使我們開發一種機制,調整 AN 的注意力,使之集中在輸入圖像中目標字符的正確位置。
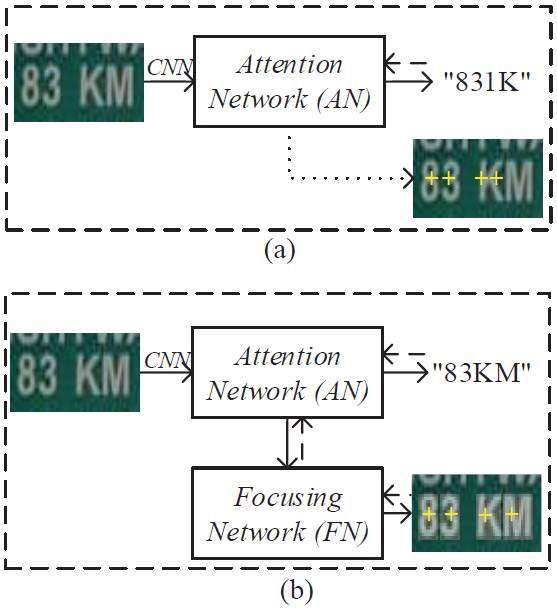
圖 2. AN 模型中的注意力漂移和 FAN 方法中的聚焦機制(focusing mechanism)。
在子圖像(a)中,帶有文本「83KM」的真實圖像作爲輸入,並輸出「831K」。最後兩個字符「K」和「M」沒有識別出,因爲 AN 的這兩個字符的注意力區域與圖像中的位置偏離太多。在子圖像(b)中,在 FN 模塊的幫助下,最後兩個字符的 AN 注意力中心得到調整,與字符的位置恰好對齊,使得 FAN 輸出正確的文本字符串「83KM」。這裏,虛線箭頭和黃色的「+」分別代表注意力區域的計算和中心;圖像右下角的白色矩形掩模代表字符的真值區域。
圖 2(a)描述了 AN 模型中的注意力漂移現象。輸入左側圖像之後,我們期待 AN 模型可以輸出文本串「83KM」,但是它輸出的是「831K」。注意,這不是一個虛構案例,它是從我們的實驗中選出來的真實案例。在實踐中,還有很多這樣的案例。很明顯,最後兩個字符「K」和「M」沒有得到準確識別。爲什麼?通過對圖像中四個字符的注意力區域進行計算,我們得到了它們的注意力中心,即右下角原始圖像中的黃色「+」。我們可以看到「8」和「3」的注意力中心就在它們上方,而第三個注意力中心覆蓋在「K」的左半邊,第四個注意力區域覆蓋「K」的右半邊。由於「K」的左半邊看起來像「1」,AN 模型輸出了「1」。第四個注意力區域覆蓋了「K」的大部分,所以 AN 模型輸出了「K」。
我們的工作。爲了解決以上問題,本文我們提出了一種新方法 FAN(Focusing Attention Network)來準確識別自然圖像中的文本。圖 2(b)展示了 FAN 方法的架構。FAN 由兩個主要子網絡構成:用於識別目標字符的注意力網絡(與現有方法一樣);聚焦網絡(focusing network/FN),首先檢測 AN 的注意力區域是否與圖像中目標字符的確切位置準確對齊,然後自動調整 AN 的注意力中心。在圖 2(b)中,使用 FN 模塊後,最後兩個字符的 AN 注意力區域得到調整,FAN 輸出了正確的文本字符串「83KM」。
本論文的貢獻有:
1)我們提出注意力漂移的概念,解釋了現有注意力方法在複雜/低質量自然圖像上性能較差的原因。
2)我們開發了一種 FAN 新方法來解決注意力漂移問題,這種方法在大多數現有方法都有的注意力模塊之外,還引入了一個全新的模塊——聚焦網絡(FN),該網絡可以使 AN 偏離的注意力重新聚焦在目標區域上。
3)我們採用強大的基於 ResNet 的卷積神經網絡,以豐富場景文本圖像的深度表徵。
4)我們在多個基準上實施大量實驗,展示了我們的方法與現有方法相比的性能優越性。
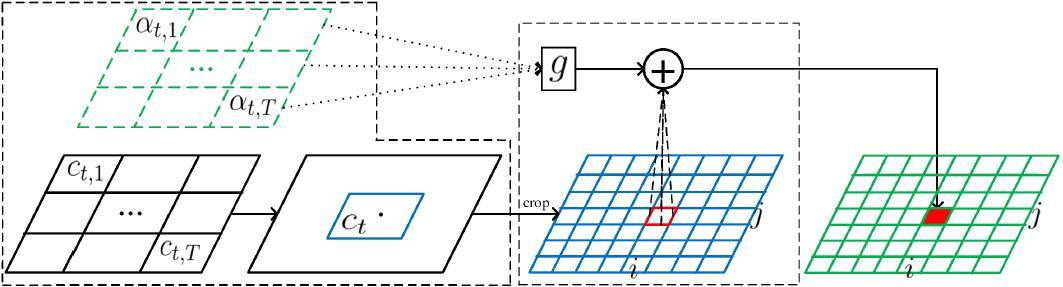
圖 3. FAN 的注意力機制。
這裏,α、c、g 和+分別代表對齊因子、輸入圖像中每個特徵的中心、glimpse 向量和聚焦操作。藍色網格和綠色網格分別代表每個像素的裁剪特徵和預測結果。爲了預測第 t 個目標,我們首先爲每個由 CNN-LSTM 獲得的特徵向量 h_j 評估中心位置 c_t,j,並計算所有中心的總權重獲取權重位置 c_t,然後從輸入圖像或卷積輸出中裁剪一組特徵,針對注意力區域進行聚焦操作。
論文:Focusing Attention: Towards Accurate Text Recognition in Natural Images
論文鏈接:https://arxiv.org/abs/1709.02054
摘要:
由於應用範圍廣泛,場景文本識別一直是計算機視覺中的熱門研究領域。目前最先進的技術是基於注意力機制的編碼器-解碼器框架,該技術以純數據驅動的方式學習輸入圖像和輸出序列的映射關係。然而,我們發現目前基於注意力機制的方法在複雜和低質量圖像中表現不佳。其主要原因是現有的方法無法獲取特徵區域和目標字符的準確對齊。我們稱之爲「注意力漂移」。爲了解決該問題,我們提出了 FAN 方法,該方法使用聚焦注意力機制來自動拉回漂移的注意力。FAN 包括兩個主要模塊:用於識別目標字符的注意力網絡(與現有方法一樣);聚焦網絡(FN),評估 AN 的注意力是否與圖像中的目標區域對齊,然後調整偏離的注意力。此外,與現有方法不同,我們還採用了基於 ResNet 的網絡來豐富場景文本圖像的深度表徵。在不同基準(包括 IIIT5k、SVT 和 ICDAR 數據集)上進行的大量實驗表明 FAN 方法明顯優於現有方法。
本文爲機器之心編譯,轉載請聯繫本公衆號獲得授權。
責任編輯: