近日,來自北京大學的研究者在 arXiv 上發佈論文,提出一種新型注意力通信模型 ATOC,使智能體在大型多智能體強化學習的部分可觀測分佈式環境下能夠進行高效的通信,幫助智能體開發出更協調複雜的策略。
從生物學角度來看,通信與合作關係密切,並可能起源於合作。例如,長尾黑顎猴可以發出不同的聲音來警示羣體中的其他成員有不同的捕食者 [2]。類似地,在多智能體強化學習(multi-agent reinforcement learning,MARL)中,通信對於合作尤爲重要,特別是在大量智能體協同工作的場景下,諸如自動車輛規劃 [1]、智能電網控制 [20] 和多機器人控制 [14]。
深度強化學習(RL)在一系列具有挑戰性的問題中取得了顯著成功,如遊戲 [16] [22] [8] 和機器人 [12] [11] [5]。我們可以把 MARL 看作是獨立的 RL,其中每個學習器都將其他智能體看成是環境的一部分。然而,隨着訓練進行,其他智能體的策略是會變動的,所以從任意單個智能體的角度來看,環境變得不穩定,智能體間難以合作。此外,使用獨立 RL 學習到的策略很容易與其他智能體的策略產生過擬合 [9]。
本論文研究者認爲解決該問題的關鍵在於通信,這可以增強策略間的協調。MARL 中有一些學習通信的方法,包括 DIAL [3]、CommNet [23]、BiCNet [18] 和 master-slave [7]。然而,現有方法所採用的智能體之間共享的信息或是預定義的通信架構是有問題的。當存在大量智能體時,智能體很難從全局共享的信息中區分出有助於協同決策的有價值的信息,因此通信幾乎毫無幫助甚至可能危及協同學習。此外,在實際應用中,由於接收大量信息需要大量的帶寬從而引起長時間的延遲和高計算複雜度,因此所有智能體之間彼此的通信是十分昂貴的。像 master-slave [7] 這樣的預定義通信架構可能有所幫助,但是它們限定特定智能體之間的通信,因而限制了潛在的合作可能性。
爲了解決這些困難,本論文提出了一種名爲 ATOC 的注意力通信模型,使智能體在大型 MARL 的部分可觀測分佈式環境下學習高效的通信。受視覺注意力循環模型的啓發,研究者設計了一種注意力單元,它可以接收編碼局部觀測結果和某個智能體的行動意圖,並決定該智能體是否要與其他智能體進行通信並在可觀測區域內合作。如果智能體選擇合作,則稱其爲發起者,它會爲了協調策略選擇協作者來組成一個通信組。通信組進行動態變化,僅在必要時保持不變。研究者利用雙向 LSTM 單元作爲信道來連接通信組內的所有智能體。LSTM 單元將內部狀態(即編碼局部觀測結果和行動意圖)作爲輸入並返回指導智能體進行協調策略的指令。與 CommNet 和 BiCNet 分別計算內部狀態的算術平均值和加權平均值不同,LSTM 單元有選擇地輸出用於協作決策的重要信息,這使得智能體能夠在動態通信環境中學習協調策略。
研究者將 ATOC 實現爲端到端訓練的 actor-critic 模型的擴展。在測試階段,所有智能體共享策略網絡、注意力單元和信道,因此 ATOC 在大量智能體的情況下具備很好的擴展性。研究者在三個場景中通過實驗展示了 ATOC 的成功,分別對應於局部獎勵、共享全局獎勵和競爭性獎勵下的智能體協作。與現有的方法相比,ATOC 智能體被證明能夠開發出更協調複雜的策略,並具備更好的可擴展性(即在測試階段添加更多智能體)。據研究者所知,這是注意力通信首次成功地應用於 MARL。
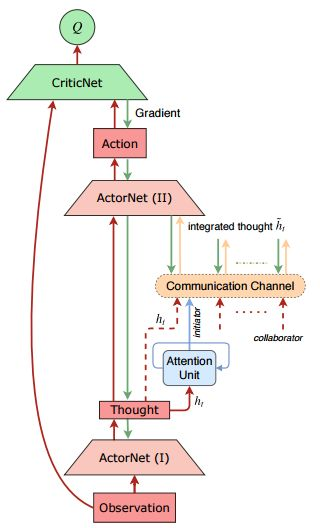
圖 1:ATOC 架構。

圖 2:實驗場景圖示:協作導航(左)、協作推球(中)、捕食者-獵物(右)。
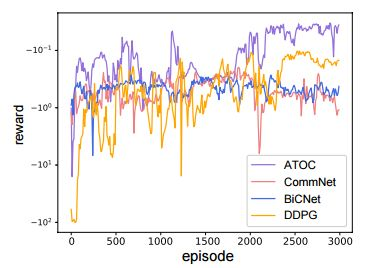
圖 3:在協作導航訓練期間,ATOC 獎勵與基線獎勵的對比。

表 1:協作導航。
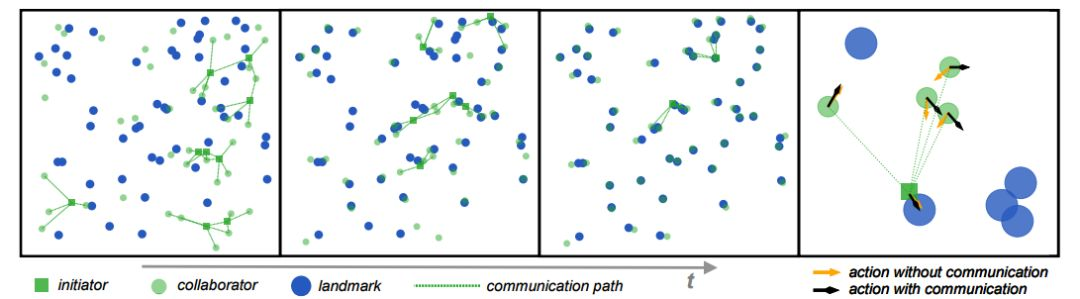
圖 4:ATOC 智能體之間關於協作導航的通信可視化。最右邊的圖片說明在有無通信時,一組智能體採取的行動。
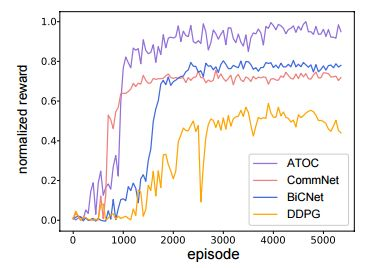
圖 5:在協作推球訓練期間,ATOC 獎勵與基線獎勵的對比。

表 2:協作推球。
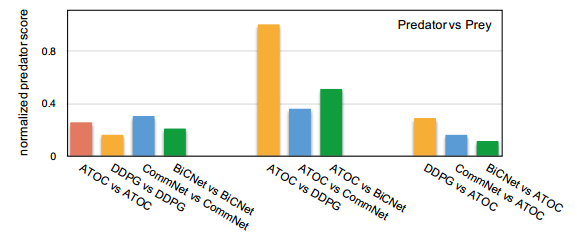
圖 6:在捕食者-獵物中,ATOC 和基線的捕食者得分的交叉對比。

ATOC 算法。
論文:Learning Attentional Communication for Multi-Agent Cooperation

論文鏈接:https://arxiv.org/pdf/1805.07733.pdf
摘要:通信可能是多智能體協作的一個有效途徑。然而,現有方法所採用的智能體之間共享的信息或是預定義的通信架構存在問題。當存在大量智能體時,智能體很難從全局共享的信息中區分出有助於協同決策的有用信息。因此通信幾乎毫無幫助甚至可能危及多智能體間的協同學習。另一方面,預定義的通信架構限定特定智能體之間的通信,因而限制了潛在的合作可能性。爲了解決這些困難,本論文提出了一種注意力通信模型,它學習何時需要通信以及如何整合共享信息以進行合作決策。我們的模型給大型的多智能體協作帶來了有效且高效的通信。從實驗上看,我們證明了該模型在不同協作場景中的有效性,使得智能體可以開發出比現有方法更協調複雜的策略。