量化模型(Quantized Model)是一種模型加速(Model Acceleration)方法的總稱,包括二值化網絡(Binary Network)、三值化網絡(Ternary Network),深度壓縮(Deep Compression)等。鑑於網上關於量化模型的不多,而且比較零散,本文將結合 TensorLayer 來講解各類量化模型,並討論一下我們過去遇到的各種坑。文章最後會介紹一些關於人工智能芯片的技術。
TensorLayer 是一個基於 TensorFlow 的高級開發工具,提供大量數據處理和建模 API,具備靈活性高、運行速度快等優點。今年 3 月,TensorLayer 提供了一套搭建量化網絡的試驗版本 API,不過目前這套 API 依然用矩陣乘法而不是加減或 bitcount 運算來加速(我們等會會提到)。
因此,這套 API 並不能加速,關於產品部署,目前可以用 TensorLayer 訓練模型,然後用自定義的 C/C++ 實現的二值化計算(TensorLayer 有可能會提供一套額外的專門運行二值化網絡的框架,並支持可以從 TensorLayer 那讀取模型)。
注意,作爲試驗版本,這套 API 有可能會被修改。更多關於模型加速的技術,可關注:https://github.com/tensorlayer/tensorlayer/issues/416
Keywords:模型壓縮(Model Compression),模型加速(Model Acceleration),二值化網絡(Binary Network),量化模型(Quantized Model)
隨着神經網絡深度增加,網絡節點變得越來越多,規模隨之變得非常大,這是對移動硬件設備非常不友好的,所以想要在有限資源的硬件設備上佈置性能良好的網絡,就需要對網絡模型進行壓縮和加速,其中量化模型由於在硬件上移植會非常方便,在理論上來講,是非常有發展潛力的。
比較有名氣的量化模型有 Deepcompression,Binary-Net,Tenary-Net,Dorefa-Net,下面對這幾種量化模型進行介紹。
DeepCompression
SongHan 這篇文章可以說是神經網絡壓縮領域開山之作,怎麼說呢這篇文章很早就注意到了,也復現了,做了很多實驗。也一直想用到硬件參數壓縮以及模型加速當中,在這個過程中遇到了很多問題,現在提出來跟大家一起探討。
算法整體框架如圖:
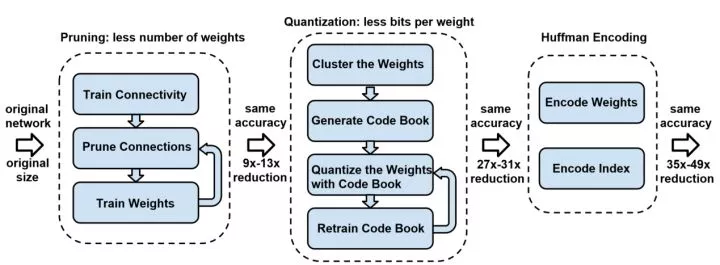
DeepCompression 主要分爲三個主要的部分:剪枝,量化,哈夫曼編碼,下面分別探討這幾種方法並且分析他們在硬件前向配置的加速潛力。
剪枝(purning):其實這個思路的核心非常簡單,就是當網絡收斂到一定程度的時候,作者認爲閾值小於一定權重的權重對網絡作用很小,那麼這些權重就被無情的拋棄了。注意,是拋棄,徹底拋棄,在復現的時候這個地方是一個大坑,被剪掉的權重不會再接收任何梯度。
然後下面的套路簡單了,就是很簡單的將網絡 reload,然後重新訓練至收斂。重複這個過程,直到網絡參數變成一個高度稀疏的矩陣。這個過程最難受的就是調參了,由於小的參數會不斷被剪枝,爲了持續增大壓縮率,閾值必須不斷增大,那麼剩下的就看你的調參大法 6 不 6 了。
當初爲了解決這個問題還專門設計了一個基於準確率損失和壓縮率上升的公式,用於壓縮。算是效果還可以,自己調參真的很難受。
最後參數會變成一個稀疏的矩陣,作者自己提出了一種編碼方式:
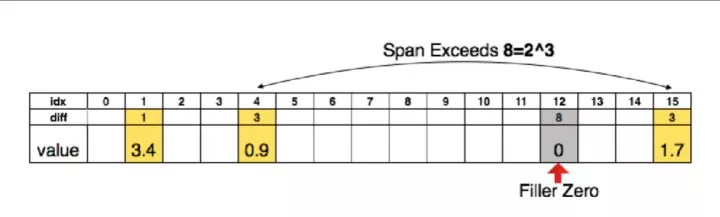
當壓縮率低於一定的值時,編碼解碼開銷其實是非常大的,甚至到一定範圍,編碼後的存儲量甚至大於不壓縮。
第二個就是量化了,將接近的值變成一個數。大概的思路如下:
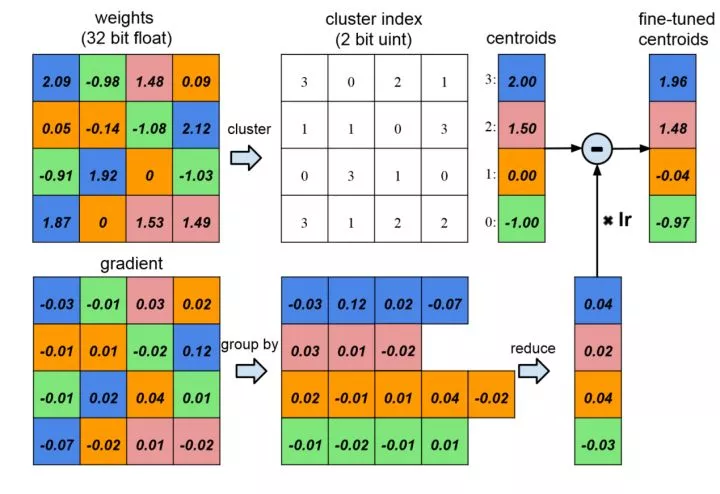
需要注意的是,量化其實是一種權值共享的策略。量化後的權值張量是一個高度稀疏的有很多共享權值的矩陣,對非零參數,我們還可以進行定點壓縮,以獲得更高的壓縮率。
論文的最後一步是使用哈夫曼編碼進行權值的壓縮,其實如果將權值使用哈夫曼編碼進行編碼,解碼的代價其實是非常大的,尤其是時間代價。還需要注意的是,DeepCompression 中對於輸出沒有壓縮。所以這種方案對於硬件加速的主要作用體現在遇到 0 即可 zero skip,即使用判斷語句替代乘法器。
Binary-Net
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
通常我們在構建神經網絡模型中使用的精度都是 32 位單精度浮點數,在網絡模型規模較大的時候,需要的內存資源就會非常巨大,而浮點數是由一位符號位,八位指數位和尾數位三個部分構成的。完成浮點加減運算的操作過程大體分爲四步:
1. 0 操作數的檢查,即若至少有一個參與運算的數爲零直接可得到結果;
2. 比較階碼大小並完成對階;
3. 尾數進行加或減運算;
4. 結果規格化並進行舍入處理。
帶來的問題是網絡在運行過程中不僅需要大量的內存還需要大量的計算資源,那麼 quantization 的優越性就體現出來了,在 2016 年發表在 NIPS 的文章 Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1 中,提出了利用降低權重和輸出的精度的方法來加速模型,因爲這樣會大幅的降低網絡的內存大小和訪問次數,並用 bit-wise operator 代替 arithmetic operator。
下面具體介紹一下這種方法的原理,在訓練 BNN 時,將權重和輸出置爲 1 或 -1,下面是兩種二值化的方法:
第一種直接將大於等於零的參數置爲 1,小於 0 的置爲 -1;
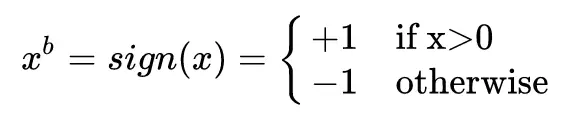
第二種將絕對值大於 1 的參數置爲 1,將絕對值小於 1 的參數根據距離 ±1 的遠近按概率隨機置爲 ±1。
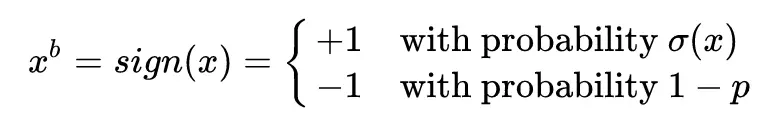
公式中是一個 clip 函數:
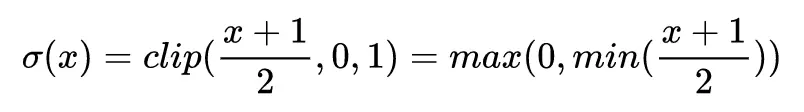
第二種二值化方式看起來更爲合理,但是由於引入了按概率分佈的隨機一比特數,所以硬件實現會消耗很多時間,我們通常使用第一種量化方法來對權重和輸出進行量化。
雖然 BNN 的參數和各層的輸出是二值化的,但梯度不得不用較高精度的實數而不是二值進行存儲。因爲梯度很小,所以使用無法使用低精度來正確表達梯度,同時梯度是有高斯白噪聲的,累加梯度才能抵消噪聲。
另一方面,二值化相當於給權重和輸出值添加了噪聲,而這樣的噪聲具有正則化作用,可以防止模型過擬合。所以,二值化也可以被看做是 Dropout 的一種變形,Dropout 是將輸出按概率置 0,從而造成一定的稀疏性,而二值化將權重也進行了稀疏,所以更加能夠防止過擬合。
由於 sign 函數的導數在非零處都是 0,所以,在梯度回傳時使用 tanh 來代替 sign 進行求導。假設 loss function 是 C,input 是 r,對 r 做二值化有:
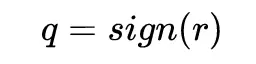
C 對 q 的的導數使用 gq 表示,那麼 q 對 r 的導數就變成了:
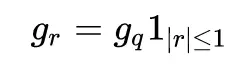
這樣就可以進行梯度回傳,給出一種包含 bn 的二值化網絡的梯度算法:

BN 最大的作用就是加速學習,減少權重尺度影響,帶來一定量的正則化,可以提高網絡性能,但是,BN 涉及很多矩陣運算(matrix multiplication),會降低運算速度,因此,提出了一種 shift-based Batch Normalization。
使用 SBN 來替換傳統的 BN,SBN 最大的優勢就是幾乎不需要進行矩陣運算,而且還不會對性能帶來損失。基於 SBN,又提出 Shift based AdaMax:

網絡除了輸入以外,全部都是二值化的,所以需要對第一層進行處理:

作者還對二值化網絡擴展到 n-bit quantized:
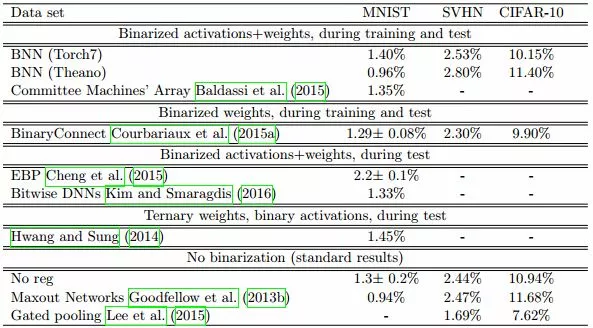
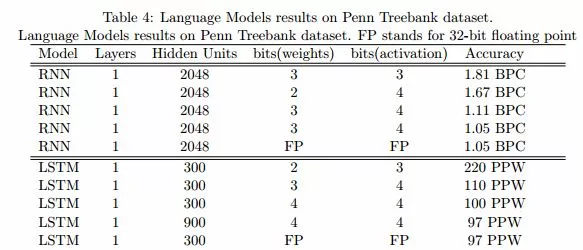
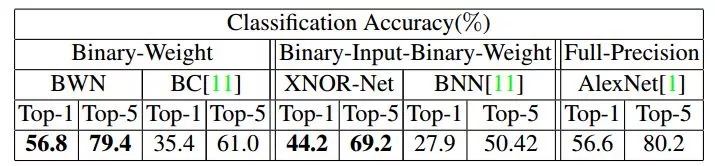
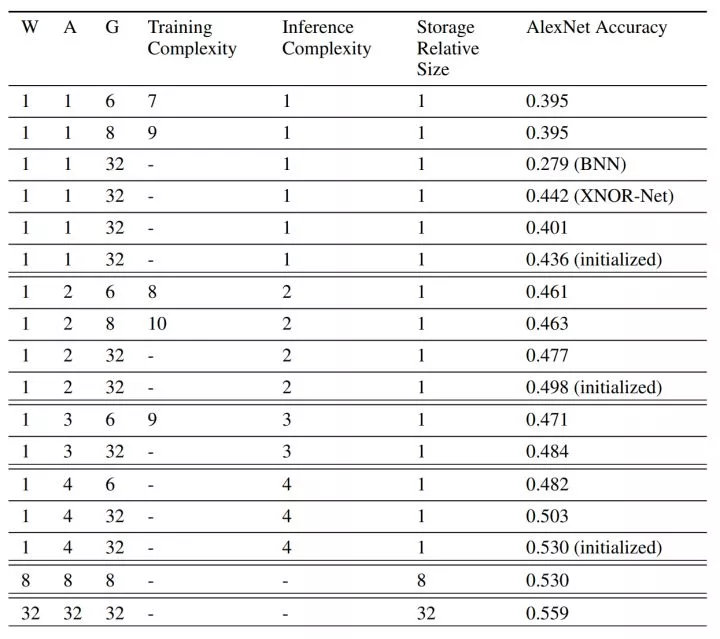
二值化的論文對 mnist、cifar-10、SVHN 進行了測試,最後得到的 test error 如下:
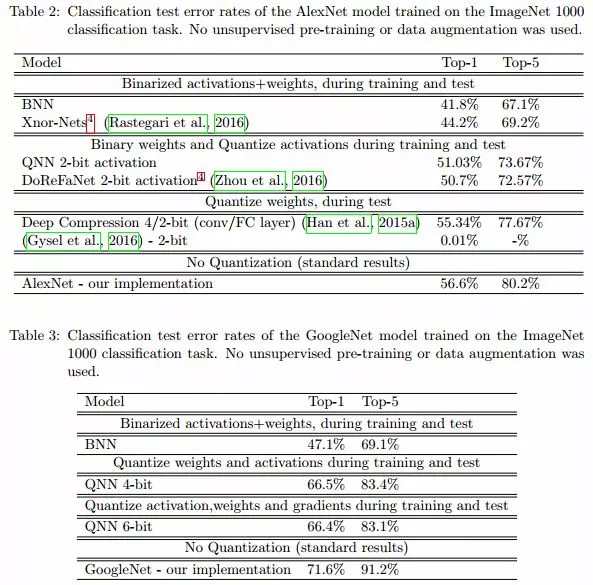
完了作者爲了挑戰高難度,又用了 alexnet 和 googlenet 在 imagenet 上做了測試,看出來結果也是一般,所以較複雜的網絡較大的數據集採用 bnn 看來影響還是蠻大的。
作者不服氣又提出了一些小技巧,比如什麼放寬 tanh 的邊界啊,用 2-bit 的 activitions,也提升了一些準確率,作者也在 rnn 做 language task 上進行了二值化,結果也貼出來,分析了那麼多模型,應該可以說在犧牲那麼多運算和儲存資源的情況下準確率差強人意。
x = tf.placeholder(tf.float32, shape=[batch_size, 28, 28, 1])net = tl.layers.InputLayer(x, name='input')net = tl.layers.BinaryConv2d(net, 32, (5, 5), (1, 1), padding='SAME', b_init=None, name='bcnn1')net = tl.layers.MaxPool2d(net, (2, 2), (2, 2), padding='SAME', name='pool1')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn1')net = tl.layers.SignLayer(net)net = tl.layers.BinaryConv2d(net, 64, (5, 5), (1, 1), padding='SAME', b_init=None, name='bcnn2')net = tl.layers.MaxPool2d(net, (2, 2), (2, 2), padding='SAME', name='pool2')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn2')net = tl.layers.FlattenLayer(net)net = tl.layers.SignLayer(net)net = tl.layers.BinaryDenseLayer(net, 256, b_init=None, name='dense')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn3')net = tl.layers.SignLayer(net)net = tl.layers.BinaryDenseLayer(net, 10, b_init=None, name='bout')net = tl.layers.BatchNormLayer(net, is_train=is_train, name='bno')上面是給 MNIST 設計的一個 BinaryNet。
作者最後又分析了一下時間複雜度和功率效率,畢竟 bnn 的主要任務就是壓縮和加速,說了時間複雜度可以降低 60%,原理是說可以卷積覈覆用。
舉個例子,因爲一個 3 x 3 的卷積核做了二值以後,只有 2 的 9 次方個獨一的卷積核,相比於沒有二值化的卷積核,在文章中的 cifar-10 網絡中獨一的卷積核數量只有 42% 那麼多。
內存資源減少了 31/32(原本每個參數 32bit,壓縮後每個參數 1bit),運算資源,硬件層面上看 32bits 損耗 200 個位,1bit 只損耗一個位(bit-wise operation)。
最後在 gpu 上還可以進行 SWAR(single instruction,multiple data within register)的處理,對 xnor 進行優化,SWAR 的基本思想是將 32 個二進制變量組連接成 32 位寄存器,從而在按位操作(例如 XNOR)上獲得 32 倍的加速。
使用 SWAR,可以僅用 3 條指令評估 32 個連接:
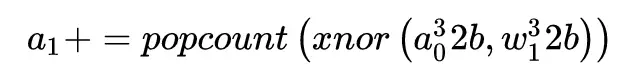
就可以用 1(加和)+4(popcount,四個 8 位)+1(xnor)個 time cycle 來進行運算,原來的 ,則是 32 個 time cycle,提高了 32/6 倍的速度。
,則是 32 個 time cycle,提高了 32/6 倍的速度。
Xnor-Net 在 BNN 的基礎上引入了比例因子,讓二值化之後的參數和原始的參數的 L2 範數最小,提高了模型的精度。
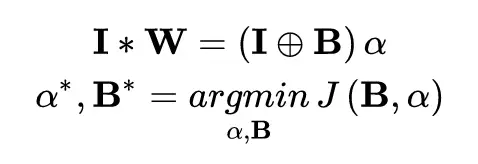
對卷積操作的比例因子進行簡化,降低了其運算複雜度。
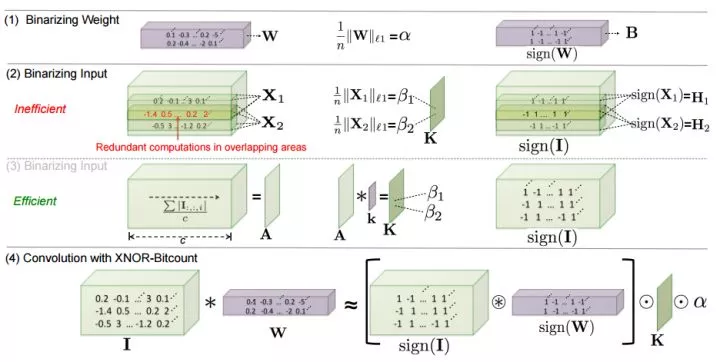
由於在一般網絡下,一層卷積的 kernel 規格是固定的,kernel 和 input 在進行卷積的時候,input 會有重疊的地方,所以在進行量化因子的運算時,先對 input 全部在 channel 維求平均,得到的矩陣 A,再和一個 w x h 的卷積核 k 進行卷積得到比例因子矩陣 K,其中:
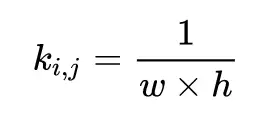
在 imagenet 上結果也比 bnn 要好很多。
Ternary-Net
Ternary Weight Networks paper
權值三值化的核心:
首先,認爲多權值相對比於二值化具有更好的網絡泛化能力。其次,認爲權值的分佈接近於一個正態分佈和一個均勻分佈的組合。最後,使用一個 scale 參數去最小化三值化前的權值和三值化之後的權值的 L2 距離。
基本原理闡述如下:
參數三值化的方式如下:
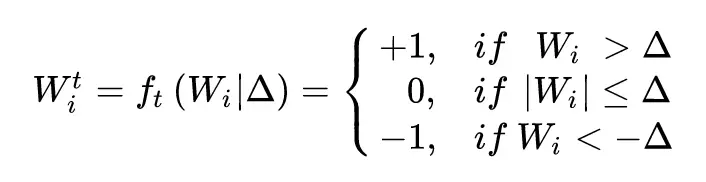
其實就是簡單的選取一個閾值(Δ),大於這個閾值的權值變成 1,小於-閾值的權值變成 -1,其他變成 0。當然這個閾值其實是根據權值的分佈的先驗知識算出來的。本文最核心的部分其實就是閾值和 scale 參數 alpha 的推導過程。
在參數三值化之後,作者使用了一個 scale 參數去讓三值化之後的參數更接近於三值化之前的參數。具體的描述如下:
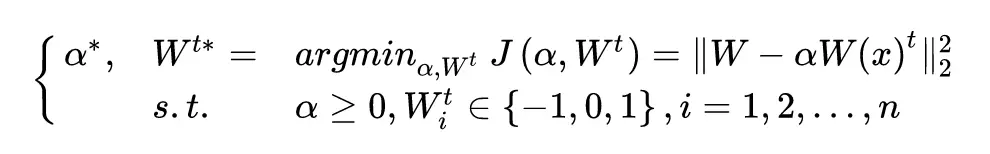
利用此公式推導出 alpha 的值如下:
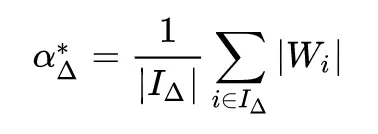
由此推得閾值的計算公式如下:
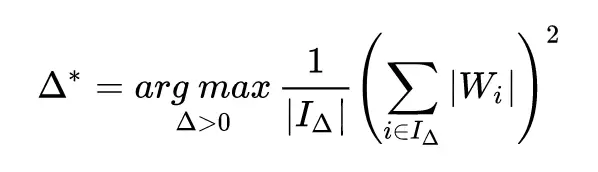
由於這個式子需要迭代才能得到解,會造成訓練速度過慢的問題,所以如果可以提前預測權值的分佈,就可以通過權值分佈大大減少閾值計算的計算量。文中推導了正態分佈和平均分佈兩種情況,並按照權值分佈是正態分佈和平均分佈組合的先驗知識提出了計算閾值的經驗公式。
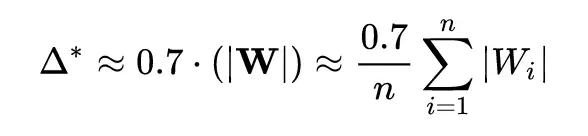
三值化論文的最終結果如下:
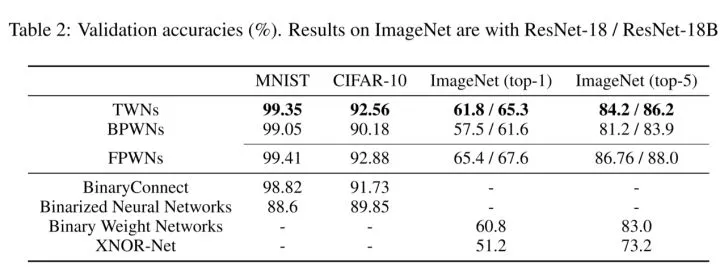
反正就是抓住 BNN 一頓 diss 唄,誰讓人家準確率高呢。
當然,這種方法有進化版本,我們完全可以將權值組合變成(-2,-1,0,1,2)的組合,以期獲得更高的準確率。正好我之前也推過相關的公式,現在貼出來供大家參考,這個時候權值的離散化公式變成了:
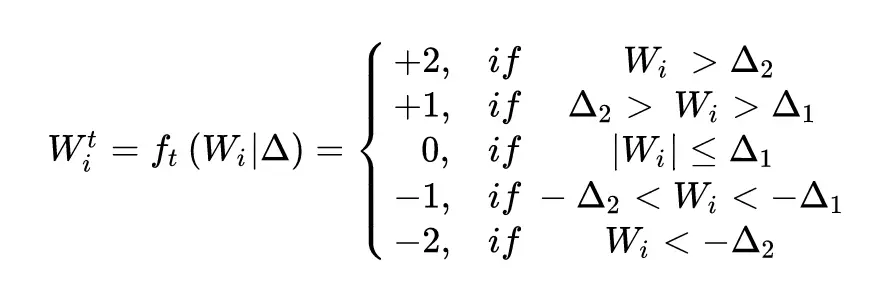
Scale 參數的計算公式變成了:
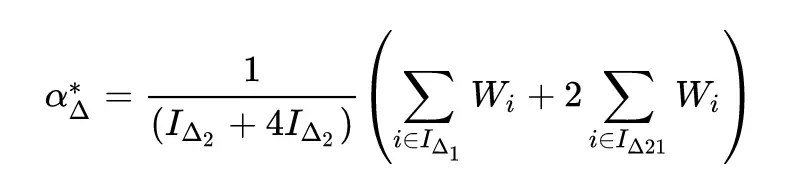
此時閾值的計算公式變成了:
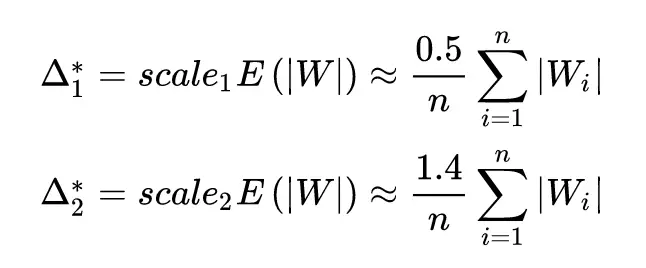
需要聲明的是,這個算法我只在一個非常不知名的 matlab 的一個純 cpu 版本慢到爆炸反正就是難以忍受那種框架上面實際實現過,取得了比三值化更高的準確率,但是!對於這個算法在 tensorflow 上面的實現我真是一籌莫展,因爲 tensorflow 某些機制……算法的具體實現方式如下:

net = tl.layers.InputLayer(x, name='input')net = tl.layers.TernaryConv2d(net, 32, (5, 5), (1, 1), padding='SAME', b_init=None, name='bcnn1')net = tl.layers.MaxPool2d(net, (2, 2), (2, 2), padding='SAME', name='pool1')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn1')net = tl.layers.TernaryConv2d(net, 64, (5, 5), (1, 1), padding='SAME', b_init=None, name='bcnn2')net = tl.layers.MaxPool2d(net, (2, 2), (2, 2), padding='SAME', name='pool2')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn2')net = tl.layers.FlattenLayer(net)net = tl.layers.TernaryDenseLayer(net, 256, b_init=None, name='dense')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn3')net = tl.layers.TernaryDenseLayer(net, 10, b_init=None, name='bout')net = tl.layers.BatchNormLayer(net, is_train=is_train, name='bno')return net上面是 TensorLayer 提供的三值化的 MNIST 測試代碼。
權值三值化並沒有完全消除乘法器,在實際前向運算的時候,它需要給每一個輸出乘以一個 scale 參數,然後這個時候的權值是(-1,0,1),以此來減少了乘法器的數目,至於爲什麼減少跟 BNN 是一樣的道理。
DoReFa-Net
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
Face++ 團隊在 16 年 6 月提出的 Dorefa-Net 和上面兩種量化方法思路也是比較接近,但 DoReLa-Net 對比例因子的設計更爲簡單,這裏並沒有針對卷積層輸出的每一個過濾映射計算比例因子,而是對卷積層的整體輸出計算一個均值常量作爲比例因子。這樣的做法可以簡化反向運算,因爲在他們反向計算時也要實現量化。
文章首先概述如何利用 DoReFa-Net 中的比特卷積內核,然後詳細說明量化權值,激活和梯度以低比特數的方法。
和之前 BNN 的點積方法一樣,DoReFa 也採用了這種簡化的點積方式。
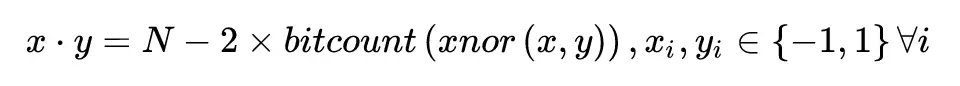
對於定點數 x 和 y,可以得到下面的公式:
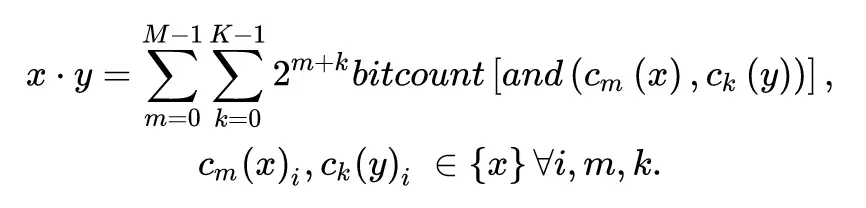
同樣爲了規避 0 梯度的問題,採用了直通估計(STE):
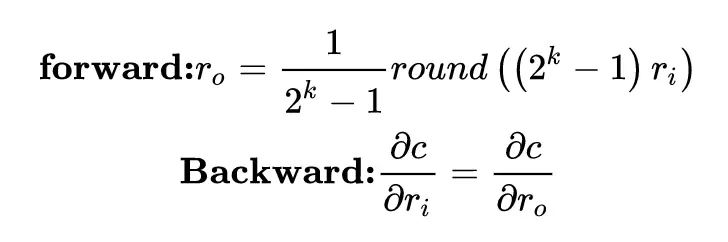
對於權重二值化的梯度回傳,採用下面的方法,即二值化乘比例因子,回傳時直接跳過二值化。
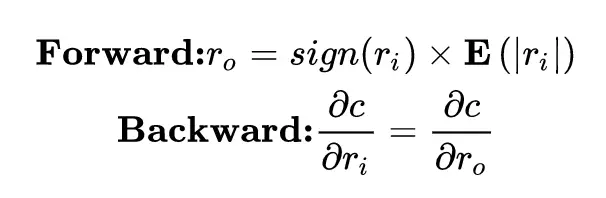
比特數 k 大於 1 的梯度回傳,需要先對參數 clip 到 [0,1] 之間:
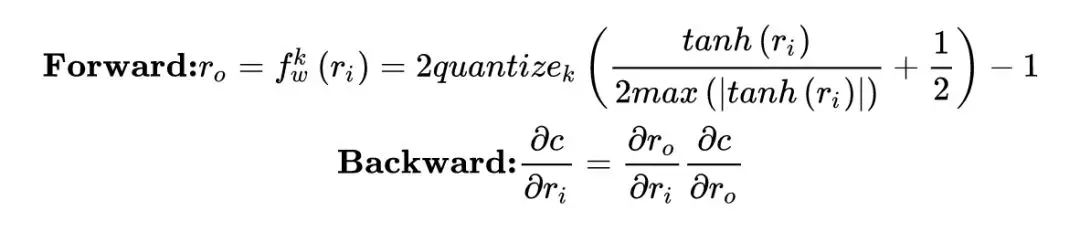
由於二值化輸出會降準確率,所以採用 k-bit 量化(k>1),這裏的 r 也要經過 clip。
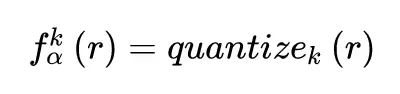
DoReFa 的梯度量化方法比較複雜,因爲梯度是無界的,並且可能具有比隱層輸出更大的值範圍。我們可以通過使可微分非線性函數傳遞值來將隱層輸出範圍映射到 [0,1]。 但是,這種構造不適用於漸變。 文章設計了以下用於梯度 k 位量化的函數,這裏 dr 是 r 對損失函數 C 的偏導。
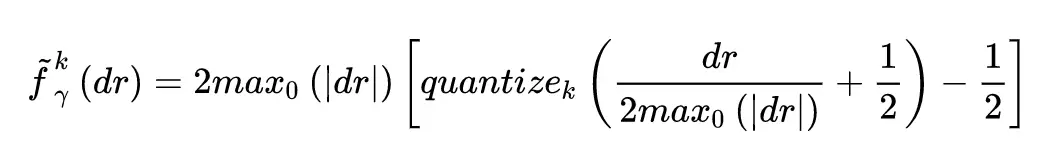
爲了補償量化梯度帶來的潛在偏差,在 clip 後的結果增加了一個高斯噪聲。
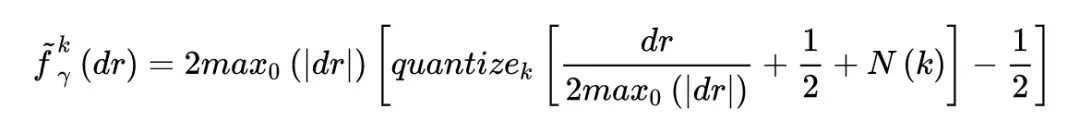
梯度的量化僅在回程中完成,因此文章在每個卷積層的輸出上應用以下 STE:
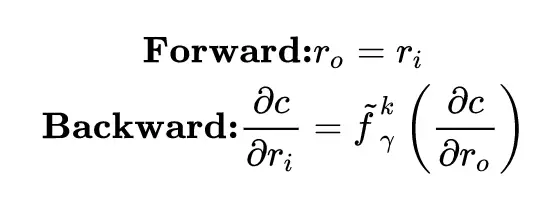
最終得到了 DoReFa-net 的算法,這裏對第一層和最後一層不做量化,因爲輸入層就圖像任務來說通常是 8-bit 的數據,做低比特量化會對精度造成很大的影響,輸出層一般是一些 one-hot 向量,所以一般對輸出層也保持原樣,除非做特殊的聲明。
DoReFa-net 爲了進一步節省資源將 3,4,6 步放在一起做,將 11,12 步融合在一起,節省了中間步驟的全精度數儲存消耗的資源。

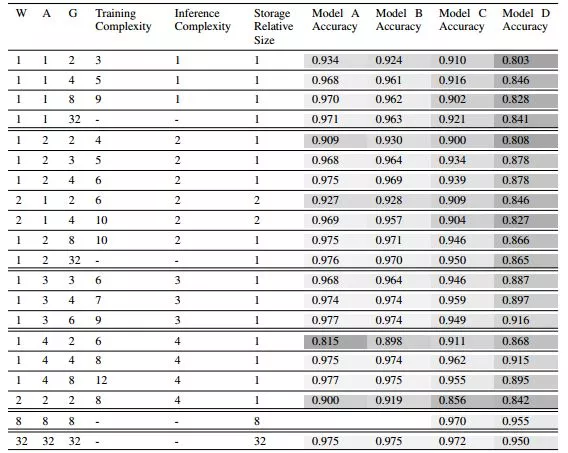
DoReFa-Net 分別對 SVHN 和 ImageNet 進行了實驗,準確率如下:
net = tl.layers.InputLayer(x, name='input')net = tl.layers.DorefaConv2d(net, 1, 3, 32, (5, 5), (1, 1), padding='SAME', b_init=None, name='bcnn1') #pylint: disable=bare-exceptnet = tl.layers.MaxPool2d(net, (2, 2), (2, 2), padding='SAME', name='pool1')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn1')net = tl.layers.DorefaConv2d(net, 1, 3, 64, (5, 5), (1, 1), padding='SAME', b_init=None, name='bcnn2') #pylint: disable=bare-exceptnet = tl.layers.MaxPool2d(net, (2, 2), (2, 2), padding='SAME', name='pool2')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn2')net = tl.layers.FlattenLayer(net)net = tl.layers.DorefaDenseLayer(net, 1, 3, 256, b_init=None, name='dense')net = tl.layers.BatchNormLayer(net, act=tl.act.htanh, is_train=is_train, name='bn3')net = tl.layers.DenseLayer(net, 10, b_init=None, name='bout')net = tl.layers.BatchNormLayer(net, is_train=is_train, name='bno')上面是 TensorLayer 提供的 DoReFa-Net 的 MNIST測試代碼,需要注意的是不同於DoReFa-Net,我們的實現默認梯度爲 32bits 來儘量獲得更高的訓練準確率,而且在實際的硬件前向配置中其實是不需要梯度信息的。
壓縮算法侷限性
目前的壓縮算法是存在一些侷限性的,最主要的問題還是準確率,論文中爲了數據好看往往是選擇傳統的神經網絡結構比如 AlexNet,VGG 作爲測試對象,而這種網絡一般是比較冗餘的。
如果想把參數壓縮方案和其他一些方案結合,比如說下面講到的一些 SqueezeNet,MobileNets,ShuffleNet 結合起來,會對準確率造成比較大的影響。原因可以歸爲參數壓縮算法其實是一個找次優解的問題,當網絡冗餘度越小,解越不好找。所以,目前的高精度壓縮算法只適合於傳統的有很多冗餘的網絡。
更多加速方法
理論上來講,量化模型是通往高速神經網絡最佳的方法,不過由於種種問題,如實現難度大、準確性不穩定,使用門檻非常大,所以除了量化模型外,目前有很多更加常用的模型加速方法:
A Survey of Model Compression and Acceleration for Deep Neural Networks (end of 2017)
這是 2017 年底的一篇 survey。
有基於 Pruning 的:
Channel Pruning for Accelerating Very Deep Neural Networks
也有基於改變卷積方式的,這是目前最常用的方法:
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
傳送門:縱覽輕量化卷積神經網絡:SqueezeNet、MobileNet、ShuffleNet、Xception
值得注意的是,當 TensorLayer 和 Keras 使用完全相同的 MobileNet 時,TensorLayer 的速度是後者的 3 倍(Titan XP 上測試),大家可以試試。
關於AI芯片
關於硬件實現,這裏要推薦一篇非常好的survey:
http://www.rle.mit.edu/eems/wp-content/uploads/2017/11/2017_pieee_dnn.pdf
大家看完這篇文章會對目前最先進的神經網絡硬件加速架構有所瞭解。
由於目前基於 PC 平臺的神經網絡加速一定程度上不能滿足需要,開發基於硬件例如 FPGA 的硬件加速平臺顯得很有必要。其實硬件加速神經網絡前向運算的最主要的任務就是完成卷積優化,減少卷積運算的資源和能源消耗非常核心。
卷積優化的主要思路
內存換取時間:如果深度學習中每一層的卷積都是針對同一張圖片,那麼所有的卷積核可以一起對這張圖片進行卷積運算,然後再分別存儲到不同的位置,這就可以增加內存的使用率,一次加載圖片,產生多次的數據,而不需要多次訪問圖片,這就是用內存來換時間。
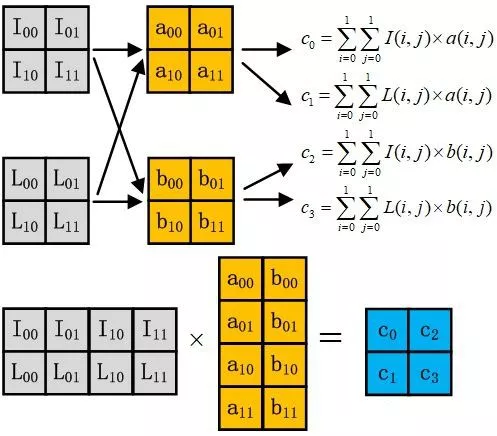
乘法優化:以下圖爲例,上面是兩張圖片,右邊是卷積核。我們可以把卷積核心展開成一條行,然後多個卷積核就可以排列成多行,再把圖像也用類似的方法展開,就可以把一個卷積問題轉換成乘法問題。這樣就是一行乘以一列,就是一個結果了。這樣雖然多做了一些展開的操作,但是對於計算來講,速度會提升很多。
GPU優化:
1. 瞭解 IO 訪問的情況以及 IO 的性能;
2. 多線程的並行計算特性;
3. IO 和並行計算間的計算時間重疊。
對於 NVIDIA 的 GPU 來講,內存訪問是有一些特性的,連續合併訪問可以很好地利用硬件的帶寬。你可以看到,NVIDIA 最新架構的 GPU,其核心數目可能並沒有明顯增加,架構似乎也沒有太大變化,但在幾個計算流處理器中間增加緩存,就提高了很大的性能,爲 IO 訪問這塊兒帶來了很大優化。
Strassen 算法
分析 CNN 的線性代數特性,增加加法減少乘法,這樣降低了卷積運算的計算的複雜度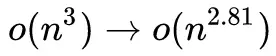 ,但是這種方法不適合在硬件裏面使用,這裏就不做詳細的介紹了。
,但是這種方法不適合在硬件裏面使用,這裏就不做詳細的介紹了。
卷積中的數據重用
在軟件中的卷積運算,其實我們是在不斷的讀取數據,進行數據計算。也就是說卷積操作中數據的存取其實是一個很大的浪費,卷積操作中數據的重用如下圖所示:
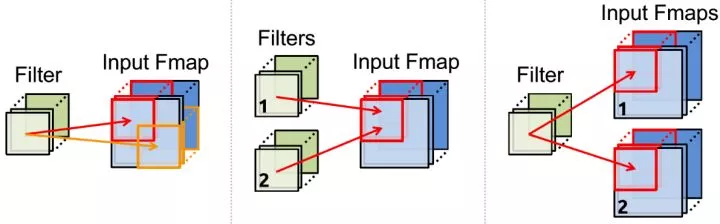
那麼想辦法減少數據的重用,減少數據的存取成爲解決卷積計算問題的一個很重要的方面。
目前這樣的方法有很多種,最主要的方法包括以下幾種:
權重固定:最小化權重讀取的消耗,最大化卷積和卷積核權重的重複使用;
輸出固定:最小化部分和 R/W 能量消耗,最大化本地積累;
NLR (No Local Reuse):使用大型全局緩衝區共享存儲,減少 DRAM 訪問能耗;
RS:在內部的寄存器中最大化重用和累加,針對整體能源效率進行優化,而不是隻針對某種數據類型。
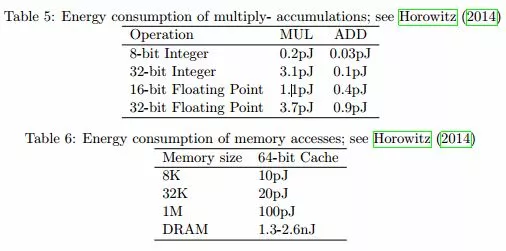
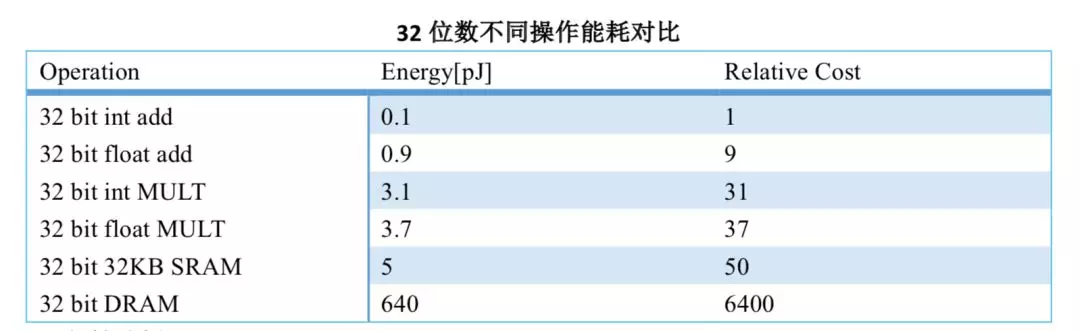
下表是在 45NM CMOS 的基礎上對於不同的操作的能耗進行的統計。對 32 位的各種操作的能耗進行統計,可以看到從 DRAM 裏面存取數據的能量消耗是最大的。是 32 位整型數據進行加法的能量消耗的 6400 倍。那麼,從數據存取角度考慮卷積的優化就顯得尤爲必要了。
可行性分析
在進行設計之前先對設計的可行性進行分析,分析過程包括卷積運算可實現性分析、卷積運算並行性分析,卷積的計算公式可以表示成下面的形式:
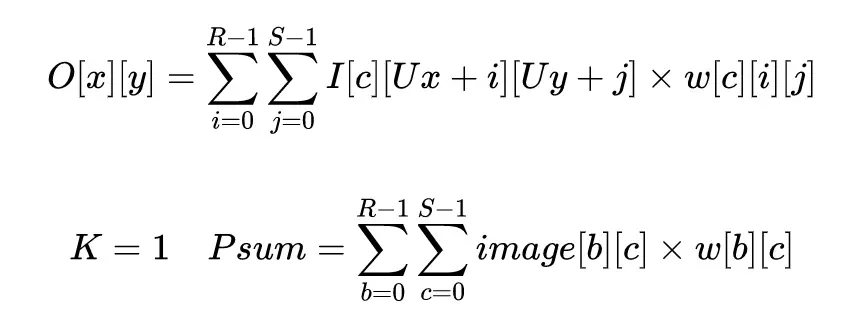
各個參數的意義在表內詳細表示:

在 GPU 中加速時,主要通過將數據最大程度的並行運算,增加了 GPU 的使用率從而加快了速度。但是這種方法在硬件實現的時候是不可行的,因爲這種方法本質上沒有降低能耗,而 DNN 模型的高能耗和大量的數據是其在可穿戴設備上面進行部署所需要面對的困難。
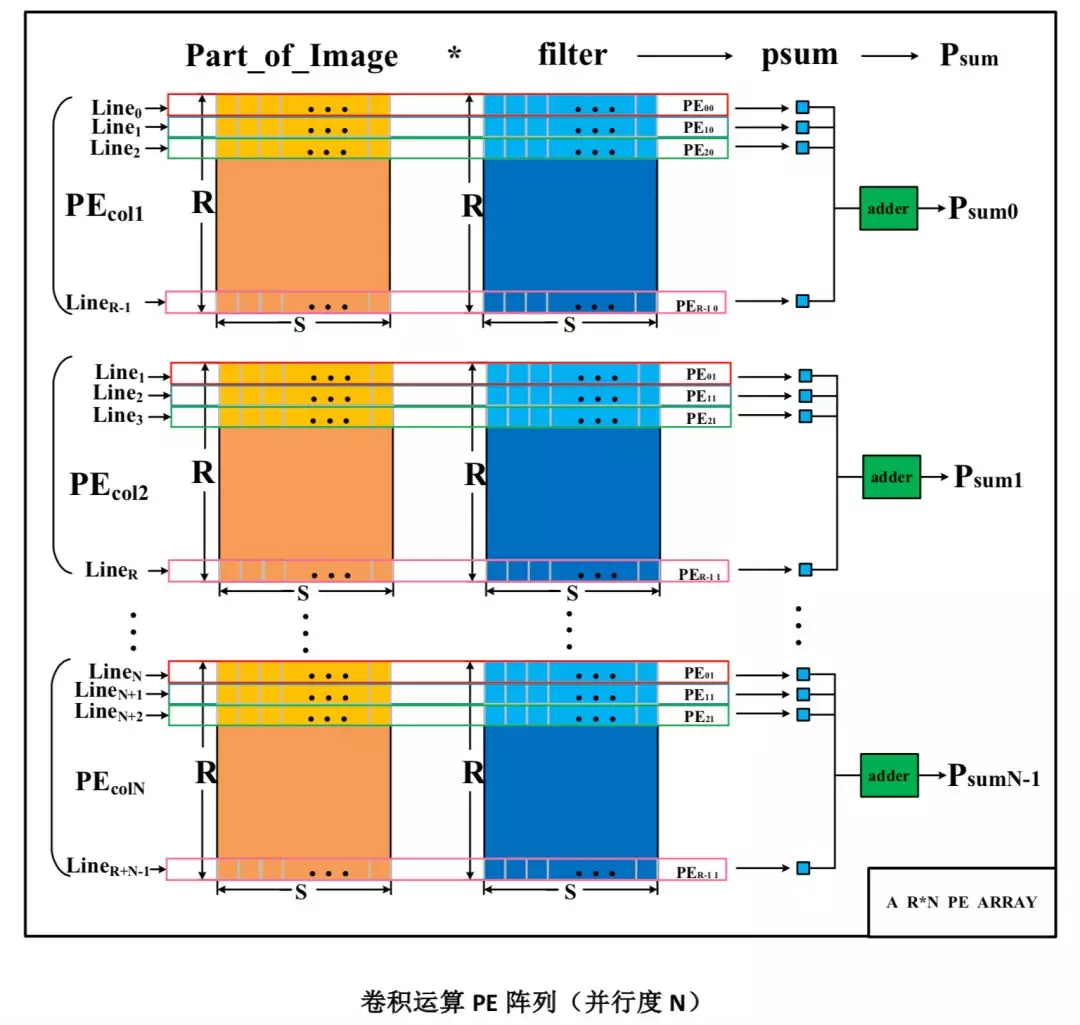
下面對一個卷積部分和運算進行分析,如下圖 :
對第一組的 PE 整列,輸入的是從 Image 的第 0 行到第 R-1 行的 S 列的數據,同樣的對於第二列的 PE 陣列輸入的是第 2 行到第 R 的 S 列的數據。每一列的 PE 計算得到一個最終的 Psum 的結果,那麼如果設置 PE 陣列的列數爲 N 的話,每次我們就可以計算得到連續的 N 個部分和的結果。
不斷更新 PE(process element,即處理單元)中 Image 緩衝區的數據,就可以模擬卷積在水平方向上面的滑動,不斷更新整個 PE 陣列的數據輸入,就可以模擬卷積窗在垂直方向上面的滑動,最終完成整個卷積運算的實現。
對應的卷積運算公式的細節在圖中已經給出了,每一組 PE 產生一個部分和的結果的話,那麼增加 PE 陣列的組數,就可以一次性產生多個部分和計算結果,這裏的組數就是並行度。
上面的內容簡單論證用數據重用的方式實現卷積運算的可行性,至於實現的具體數據流,還有相對用的系統的架構。
壓縮算法在實際硬件芯片的應用
其實壓縮算法應用硬件芯片非常簡單,就是簡單的將硬件芯片原來使用的乘法器進行替換,如果是 BNN,參數只有兩種情形,那麼如果參數爲 1 的時候,直接通過,不計算,如果參數爲 -1 的時候,翻轉最高位即可。
同理三值化中增加了一個 0 參數,這個可以直接跳過不進行計算。至於參數爲(-2,-1,0,1,2)的情形,參數爲 2 時就增加了一個移位運算,參數爲 -2 的時候增加了一個最高位的翻轉。
如果是 DoReFaNet,權值和輸出都固定在一定的種類內部,那麼他們的乘積情形也只有一定的種類,這個時候相當於把乘法器變成了一個尋址操作,每次乘法只需要在 LUT(look-up table,查找表)裏面尋找到正確的結果讀出即可。