選自BAIR Blog
不久之前,我們推薦了一篇論文,介紹 UC Berkeley 研究員發佈的分佈式系統 Ray(參見:學界 | Michael Jodan 等人提出新型分佈式框架 Ray:實時動態學習的開端》。開發者稱,Ray 專門爲人工智能應用設計,通過這款框架,運行於筆記本電腦上的原型算法僅需加入數行代碼就可以轉化爲高效的分佈式計算應用。近日,該框架已被開源。在本文中,伯克利官方 AI 博客對開源框架 Ray 做了詳細介紹。
GitHub 鏈接:https://github.com/ray-project/ray
隨着機器學習算法和技術的進步,出現了越來越多需要在多臺機器並行計算的機器學習應用。然而,在集羣計算設備上運行的機器學習算法目前仍是專門設計的。儘管對於特定的用例而言(如參數服務器或超參數搜索),這些解決方案的效果很好,同時 AI 領域之外也存在一些高質量的分佈式系統(如 Hadoop 和 Spark),但前沿開發者們仍然常常需要從頭構建自己的系統,這意味着需要耗費大量時間和精力。
例如,應用一個簡單概念的算法,如在強化學習中的進化策略(論文《Evolution Strategies as a Scalable Alternative to Reinforcement Learning》)。算法包含數十行僞代碼,其中的 Python 實現也並不多。然而,在較大的機器或集羣上運行它需要更多的軟件工程工作。作者的實現包含了上千行代碼,以及必須定義的通信協議、信息序列化、反序列化策略,以及各種數據處理策略。
Ray 的目標之一在於:讓開發者可以用一個運行在筆記本電腦上的原型算法,僅需添加數行代碼就能輕鬆轉爲適合於計算機集羣運行的(或單個多核心計算機的)高性能分佈式應用。這樣的框架需要包含手動優化系統的性能優勢,同時又不需要用戶關心那些調度、數據傳輸和硬件錯誤等問題。
開源的人工智能框架
與深度學習框架的關係:Ray 與 TensorFlow、PyTorch 和 MXNet 等深度學習框架互相兼容,在很多應用上,在 Ray 中使用一個或多個深度學習框架都是非常自然的(例如,UC Berkeley 的強化學習庫就用到了很多 TensorFlow 與 PyTorch)。
與其他分佈式系統的關係:目前的很多流行分佈式系統都不是以構建 AI 應用爲目標設計的,缺乏人工智能應用的相應支持與 API,UC Berkeley 的研究人員認爲,目前的分佈式系統缺乏以下一些特性:
支持毫秒級的任務處理,每秒處理百萬級的任務;
嵌套並行(任務內並行化任務,例如超參數搜索內部的並行模擬,見下圖);
在運行時動態監測任意任務的依賴性(例如,忽略等待慢速的工作器);
在共享可變的狀態下運行任務(例如,神經網絡權重或模擬器);
支持異構計算(CPU、GPU 等等)。
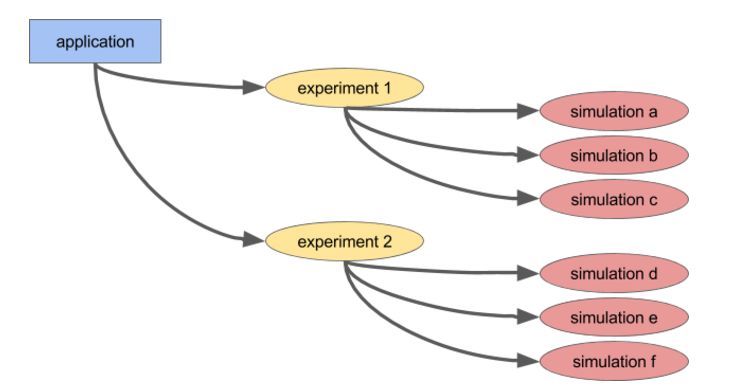
一個嵌套並行的簡單例子。一個應用運行兩個並行實驗(每個都是長時間運行任務),每個實驗運行一定數量的並行模擬(每一個同時也是一個任務)。
Ray 有兩種主要使用方法:通過低級 API 或高級庫。高級庫是構建在低級 API 之上的。目前它們包括 Ray RLlib,一個可擴展強化學習庫;和 Ray.tune,一個高效分佈式超參數搜索庫。
Ray 的低層 API
開發 Ray API 的目的是讓我們能更自然地表達非常普遍的計算模式和應用,而不被限制爲固定的模式,就像 MapReduce 那樣。
動態任務圖
Ray 應用的基礎是動態任務圖。這和 TensorFlow 中的計算圖很不一樣。TensorFlow 的計算圖用於表徵神經網絡,在單個應用中執行很多次,而 Ray 的任務圖用於表徵整個應用,並僅執行一次。任務圖對於前臺是未知的,隨着應用的運行而動態地構建,且一個任務的執行可能創建更多的任務。
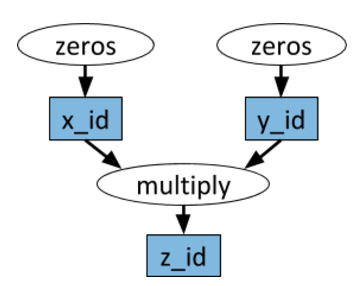
計算圖示例。白色橢圓表示任務,藍色方框表示對象。箭頭表示任務依賴於一個對象,或者任務創建了一個對象。
任意的 Python 函數都可以當成任務來執行,並且可以任意地依賴於其它任務的輸出。如下示例代碼所示:
# Define two remote functions. Invocations of these functions create tasks
# that are executed remotely.
@ray.remote
defmultiply(x,y):
returnnp.dot(x,y)
@ray.remote
defzeros(size):
returnnp.zeros(size)
# Start two tasks in parallel. These immediately return futures and the
# tasks are executed in the background.
x_id =zeros.remote((100,100))
y_id =zeros.remote((100,100))
# Start a third task. This will not be scheduled until the first two
# tasks have completed.
z_id =multiply.remote(x_id,y_id)
# Get the result. This will block until the third task completes.
z =ray.get(z_id)
動作器(Actor)
僅用遠程函數和上述的任務所無法完成的一件事是在相同的共享可變狀態上執行多個任務。這在很多機器學習場景中都出現過,其中共享狀態可能是模擬器的狀態、神經網絡的權重或其它。Ray 使用 actor 抽象以封裝多個任務之間共享的可變狀態。以下是關於 Atari 模擬器的虛構示例:
importgym
@ray.remote
classSimulator(object):
def__init__(self):
self.env =gym.make("Pong-v0")
self.env.reset()
defstep(self,action):
returnself.env.step(action)
# Create a simulator, this will start a remote process that will run
# all methods for this actor.
simulator =Simulator.remote()
observations =[]
for_ inrange(4):
# Take action 0 in the simulator. This call does not block and
# it returns a future.
observations.append(simulator.step.remote(0))
Actor 可以很靈活地應用。例如,actor 可以封裝模擬器或神經網絡策略,並且可以用於分佈式訓練(作爲參數服務器),或者在實際應用中提供策略。
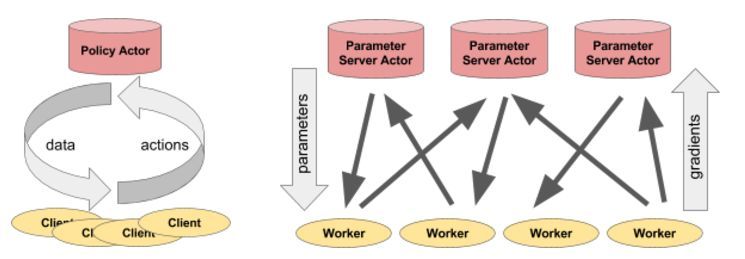
圖左:actor 爲客戶端進程提供預測/操作。圖右:多個參數服務器 actor 使用多個工作進程執行分佈式訓練。
參數服務器示例
一個參數服務器可以作爲一個 Ray actor 按如下代碼實現:
@ray.remote
classParameterServer(object):
def__init__(self,keys,values):
# These values will be mutated, so we must create a local copy.
values =[value.copy()forvalue invalues]
self.parameters =dict(zip(keys,values))
defget(self,keys):
return[self.parameters[key]forkey inkeys]
defupdate(self,keys,values):
# This update function adds to the existing values, but the update
# function can be defined arbitrarily.
forkey,value inzip(keys,values):
self.parameters[key]+=value
這裏有更完整的示例:http://ray.readthedocs.io/en/latest/example-parameter-server.html
執行以下代碼初始化參數服務器:
parameter_server =ParameterServer.remote(initial_keys,initial_values)
執行以下代碼,創建 4 個長時間運行的持續恢復和更新參數的工作進程:
@ray.remote
defworker_task(parameter_server):
whileTrue:
keys =['key1','key2','key3']
# Get the latest parameters.
values =ray.get(parameter_server.get.remote(keys))
# Compute some parameter updates.
updates =…
# Update the parameters.
parameter_server.update.remote(keys,updates)
# Start 4 long-running tasks.
for_ inrange(4):
worker_task.remote(parameter_server)
Ray 高級庫
Ray RLib 是一個可擴展的強化學習庫,其建立的目的是在多個機器上運行,可以通過示例訓練腳本或者 Python API 進行使用。目前它已有的實現爲:
A3C
DQN
Evolution Strategies
PPO
UC Berkeley 的開發者在未來將繼續添加更多的算法。同時,RLib 和 OpenAI gym 是完全兼容的。
Ray.tune 是一個高效的分佈式超參數搜索庫。它提供了一個 Python API 以執行深度學習、強化學習和其它計算密集型任務。以下是一個虛構示例的代碼:
fromray.tune importregister_trainable,grid_search,run_experiments
# The function to optimize. The hyperparameters are in the config
# argument.
defmy_func(config,reporter):
importtime,numpy asnp
i =0
whileTrue:
reporter(timesteps_total=i,mean_accuracy=(i **config['alpha']))
i +=config['beta']
time.sleep(0.01)
register_trainable('my_func',my_func)
run_experiments({
'my_experiment':{
'run':'my_func',
'resources':{'cpu':1,'gpu':0},
'stop':{'mean_accuracy':100},
'config':{
'alpha':grid_search([0.2,0.4,0.6]),
'beta':grid_search([1,2]),
},
}
})
可以使用 TensorBoard 和 rllab's VisKit 等工具對運行狀態的結果進行實時可視化(或者直接閱讀 JSON 日誌)。Ray.tune 支持網格搜索、隨機搜索和更復雜的早停算法,如 HyperBand。
原文地址:http://bair.berkeley.edu/blog/2018/01/09/ray/