日前,滴滴副總裁章文嵩的一段演講片段掀起了一波吐槽滴滴的高潮。
他的原文如下:
「所以說,我們這個問題的複雜度,比下圍棋要複雜一百倍以上,就比 AlphaGo 面臨的問題複雜一百倍,因爲我們知道一天有 86400 秒,如果除以兩秒鐘撮合一次,我們的步數我們要考慮 43200 步,我們知道下圍棋,格子裏面只有 19 乘 19,最多 361 步,而且都有確定性的解,是贏,還是輸,還是平局。那我們實際上最優解是怎麼樣?都是目前我們在不斷迭代,所以這個問題複雜度,比下圍棋複雜多了,所以這可能是跟大家想象得不一樣,滴滴是真正背後是拿很多科技的手段在解決問題……」
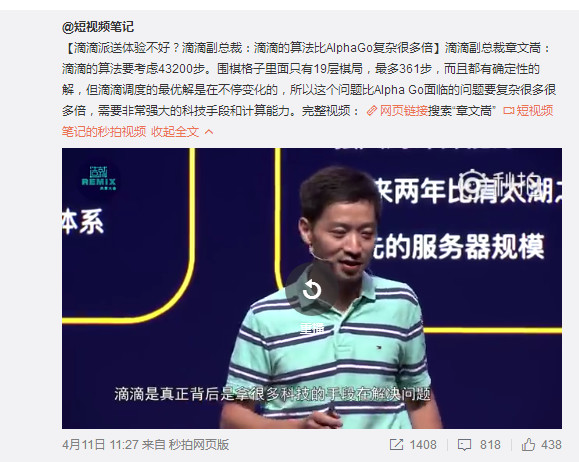
這段話核心觀點如下——滴滴所面臨的問題比 AlphaGo 要複雜得多。
然而很不幸,我們看到,微博上某些媒體將標題引申爲:【滴滴派送體驗不好?滴滴副總裁:滴滴的算法比 AlphaGo 複雜很多倍】
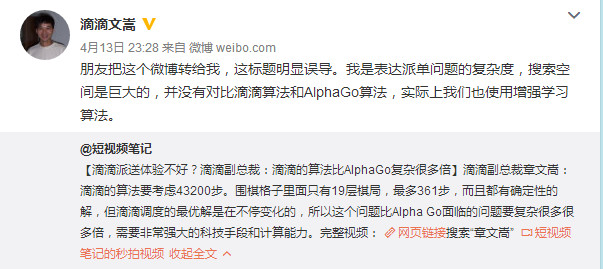
當然,被有意誤導之後,他第一時間發表微博表示:「這標題明顯誤導。我是表達派單問題的複雜度,搜索空間是巨大的,並沒有對比滴滴算法和 AlphaGo 算法,實際上我們也使用增強學習算法。」
但是事情已經發生,出現了很多(讓人覺得標題沒常識的)新聞:
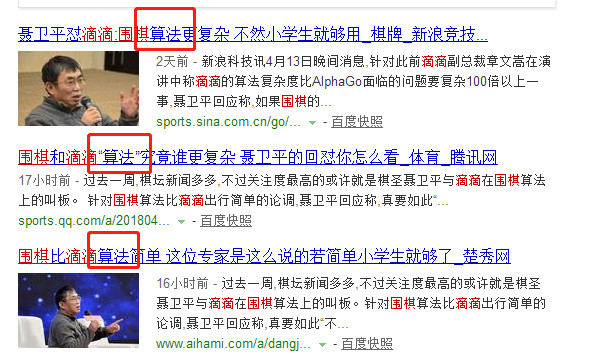
嗯,對於算法,章文嵩根本就沒有進行比較(攤手)。
值得注意的一點是,這些新聞都圍繞棋聖聶衛平展開。
據媒體報道,在江蘇姜堰觀戰世界女子圍棋擂臺賽期間,心直口快的聶衛平聽說了章文嵩的言論,忍不住反問:
「我就問一句,圍棋有 361 個格子,你知道這其中的變化量是多少嗎?……中國圍棋協會主席林建超在擔任總參辦公廳主任時組織力量進行研究,得出的結論是圍棋變化是 10 的 808 次方。如果圍棋的算法比滴滴都簡單,何須擁有巨大資金和技術支撐的 AlphaGo 團隊出馬,一個小學生就足夠研究透徹了!」
棋聖在這裏高冷地表示,我們圍棋並不簡單。當然,他的這番言論中也出現了一個小 bug——「如果圍棋的算法比滴滴都簡單」,事實上章文嵩在演講中並沒有將兩者的算法進行比較。
隨後,章文嵩發文詳細說明了滴滴派單問題的複雜性:
在圍棋裏,每一步落子都會影響棋局變化。在 19*19 的棋盤上,最多對弈 361 步,若不考慮棋盤的對稱性,圍棋的變化是 361 的階乘,約 10 的 768 次方...,這已經是一個驚人的量。
滴滴派單問題是極爲複雜的時空調度問題,一天有幾千萬乘客在不同的時空中發出需求,也有大幾百萬司機在不同的時空出現,每一次不同的派單都會影響不同的時空裏供需分佈,乘客和司機對派單響應是動態的,交通路況也不斷地變化,優化目標也挺難刻畫的,不光考慮全局的需求滿足率,還得考慮人們心目中對服務的感覺等約束,把服務確定性描述清楚就不容易,是個開放的問題。若要跟圍棋對比,我們簡單抽象這個問題,一天完成 2500 萬以上的訂單,每 2 秒的一次撮合完成幾百到上千的派單,一次撮合本身的計算複雜度非常高,可載客的車輛數和需求訂單數遠遠大於派單數,組合的空間非常大 10 萬以上,每 2 秒撮合都會影響到未來的時空上供需分佈,就像下棋每一步落子都會影響棋局變化,一天共撮合 43200 次,時空的變化是(10 萬)43200 次方的量級。滴滴也用強化學習算法來解這個問題,不斷迭代和改進。
圍棋的規則是確定的,是完美信息博弈,AlphaZero 可以自己根據規則創造出棋譜,AlphaGo 和 AlphaZero 在圍棋上可以超過人類棋手。而在開放問題上,AlphaGo 和 AlphaZero 目前還不能超越人類,例如,在星際爭霸上還打不過人類,在王者榮耀上也勝不過人類。相信在大家共同努力下,技術不斷突破邊界,我們人類也有信心駕馭它,爲人類的智慧不斷增長而服務。在不同的戰場,我們一起加油。
以上。
然而,不幸地是,他的話語又捅出了簍子。身爲前阿里雲 CTO,LVS(Linux Virtual Server)開源軟件創始人,雖然對技術是極懂的,但是看起來卻不那麼懂圍棋。
他說道,「我們知道下圍棋,格子裏面只有 19 乘 19,最多 361 步。」
然後,微博下面是一波類似這樣的羣嘲:
隨後,他也爲自己的失誤道歉並表示,雖然自己前面的說法有誤,但圍棋的複雜度並不是無限提升的:
圍棋最多 361 步這個說法不準確,抱歉!沒有考慮到打劫和提子的情況,感謝大家的討論提升了我的認知。圍棋的複雜度不是無限提升的,不能反覆打劫,提子後空間也有限,聶棋聖在微博上說有專家團隊研究過圍棋變化是 10 的 808 次方。還是挺想學習一下里面的計算方法。
但是,解決的問題越複雜就意味着更厲害嗎?
對於這一問題,其實已經有一大批知乎 er 展開了討論。
雖然提問的打開方式並不怎麼正確:
如何看待滴滴章文嵩稱,滴滴的算法比 AlphaGo 複雜 100 倍?(章文嵩哪裏有說滴滴的算法比 AlphaGo 複雜了???)
隨後引發了一大波不明真相的羣衆的歪樓,大家都在嘲笑:
你這個算法有什麼可比的。
算法更復雜,不就證明代碼越費時費力,不就證明你的工程水平不高?
(不明覺厲)
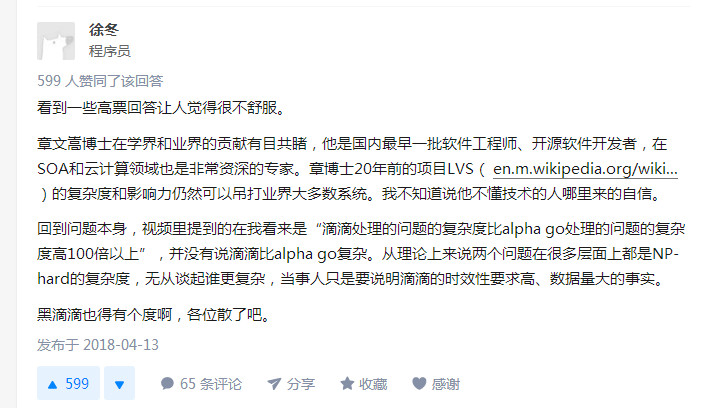
當然,也有正正經經研究過事情始末的人,表達了這樣的言論:
從理論上來說兩個問題在很多層面上都是 NP-hard 的複雜度,無從談起誰更復雜,當事人只是要說明滴滴的時效性要求高、數據量大的事實。
在這兩種言論之間,也有人站在客觀的立場看待這一問題。
知乎上一位匿名用戶表示,雖然圍棋的複雜度或許更高,但從用戶體驗上來看,滴滴並沒有成功解決問題:
第一,圍棋場景複雜度也許更高。
圍棋的場景複雜度,並不在於其每一步最多 361 種選擇。它複雜在,坐在你對面是高智商的對手。需時刻提防對手隨時「留陷阱」,要每一步皆需統籌全局,並能大致預測對方接下來幾步落子位置,且要有與之相應的應對措施。
而滴滴的派單場景呢,沒有「高智商對手」主動「下絆子」是前提。在這種相對穩定又絕對動態的情境下進行派單。具體每一步的複雜程度有多高,按照章所言,43200 種選擇。
我沒有讀過 AlphaGo 源碼,所以只能做一個不負責的數字推斷:
鑑於隨着棋局的進行,每一步的落子選擇也減少,因而保守假設平均每一步有 100 種選擇。
之前看到報道說 AlphaGo 最多可以提前預判 50 步棋。如此,AlphaGo 每走一步棋需要考慮 100 的 50 次方。這個數字相信遠遠超過 43200 吧。
100 的 50 次方這個數字可能有點誇張,畢竟 AlphaGo 不是窮舉的。但是肯定不是章以爲的「最多 361 種選擇」這麼簡單。
第二,用戶體驗上來看,滴滴沒有成功解決問題。
目前看來,AlphaGo 是成功解決了圍棋爭霸這個難題了。
至於滴滴嘛,他的派單算法有多複雜先不談,但是其提供的服務說實話是沒辦法硬着脖子講「完全解決」這四個字的。
退一萬步講,假設派單場景確實比下圍棋複雜的多。那麼,章的行爲就像某些人宣稱的:「我在試圖形成一個比相對論更高的模型,雖然還沒成功,但是我比愛因斯坦更偉大!」
第三,章文嵩本人非算法領域。
有很多答主都提到了,他是阿里的高級專家,是真正的系統級開發高手。但是問題就在這兒。
其實 AlphaGo 算法跟系統開發是兩個截然不同的領域。
相比對算法方面的評價,其實他在 AlphaGo 的網絡延遲、分佈式計算效率、CPU 利用率等問題上會更專業。
至於算法複雜度,鑑於 Deep Learning 是強凸優化強矩陣變換的一種統計學習算法,我相信滴滴內部的算法相關負責人應該更有發言權。
而微博上,也有一大票用戶評論,不管討論的是問題複雜度還是算法複雜度,首要問題應該是解決用戶體驗。
我們也將持續跟進這一問題的後續,敬請期待。
PS:關於滴滴的調度系統,滴滴研究院副院長、密歇根大學終身教授葉傑平博士曾非常全面地進行了揭祕,大家可以在看過之後,再回望這場鬧劇。
傳送門:滴滴研究院副院長葉傑平:揭開滴滴人工智能調度系統的真面目