我之前的文章介紹瞭如何利用名爲人工蜂羣算法(ABC)的集羣智能(SI)算法來解決現實世界的優化問題:https://medium.com/cesar-update/a-swarm-intelligence-approach-to-optimization-problems-using-the-artificial-bee-colony-abc-5d4c0302aaa4
這篇文章將會介紹如何處理真實數據、如何使用 ABC 算法實現聚類。在此之前,我們先了解一下聚類問題。
聚類問題
聚類問題是一類 NP-hard 問題,其基本思想是發現數據中的隱藏模式。聚類沒有正式的定義,但它與元素分組的思想有關:通過分組我們可以區分元素爲不同的組。
不同的算法族以不同的方式定義聚類問題。一種常見的經典聚類方法如下:它將問題簡化爲一個數學問題,即找到原始數據的一個 k 分區。
找到集合 S 的 k 分區等價於找到 S 的 k 個子集,其遵循以下兩個規則:
1. 不同子集的交集等於空集。
2.k 個子集的並集爲 S。
在分區聚類過程結束時,我們希望找到原始數據集的一組子集,使得一個實例只屬於一個子集。具體如下圖所示:
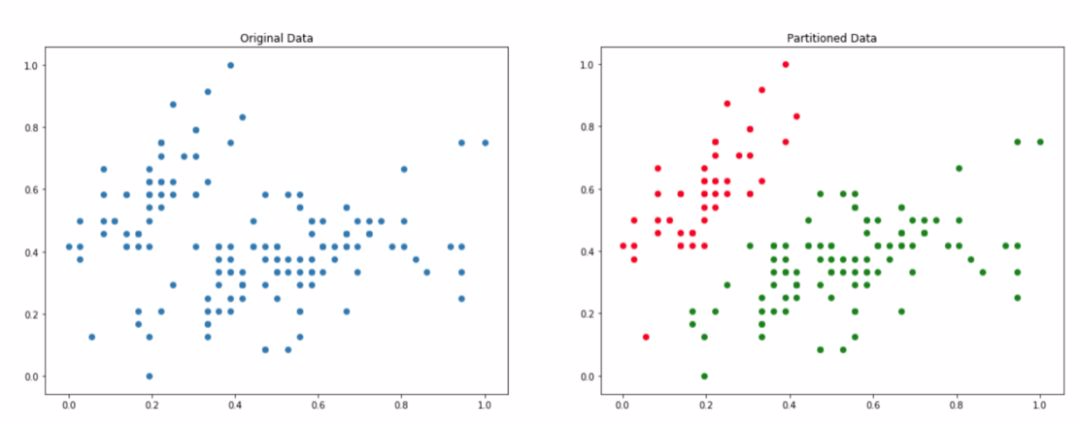
左邊是原始數據,右邊是 k=2 分區處理後的數據。
如何劃分數據以達到上圖所示的分區效果?聚類過程的輸出是一組質心。質心是每個分組的代表實體,所以如果數據有 k 個分區,那麼它有 k 個質心。
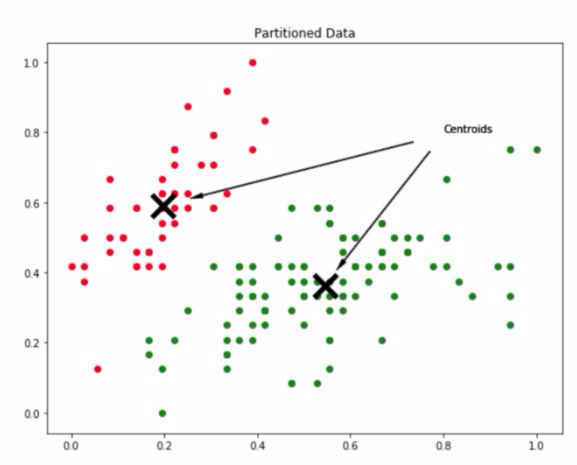
k=2 數據分區的質心演示示例。
質心也可理解爲由數據定義的搜索空間上的點,由於每個質心定義了一個分組,每個數據點將被分配到距離它最近的質心。
人工蜂羣算法的聚類應用
如何修改原始的 ABC 算法使其得以執行聚類任務?實際上,此處 ABC 算法沒作任何改動。唯一要做的就是將聚類問題轉化爲優化問題。如何做到這一點?
一個明確定義的優化問題需要一個搜索空間:一組 d 維決策變量輸入和一個目標函數。如果將人工集羣中的每一個點(蜂)視爲聚類問題的一個劃分,那麼每一個點可以代表一整組候選質心。如果對 d 維空間上的數據集執行 k 分區,那麼每個點都將是一個 k·d 維向量。
上文定義瞭如何表示輸入決策變量,接下來只需要弄清楚如何定義搜索空間的邊界以及選用什麼目標函數。
搜索空間邊界的定義很容易,用 [0,1] 區間對整個數據集進行歸一化,並將目標函數的值域定義爲 0 到 1。麻煩的是如何定義目標函數。
分區聚類方法希望最大化兩個不同組之間的距離,並最小化組內的距離。文獻中提到了幾個目標函數,但是最爲人熟知的方法是所謂的平方誤差和(Sum of Squared Errors,SSE)。
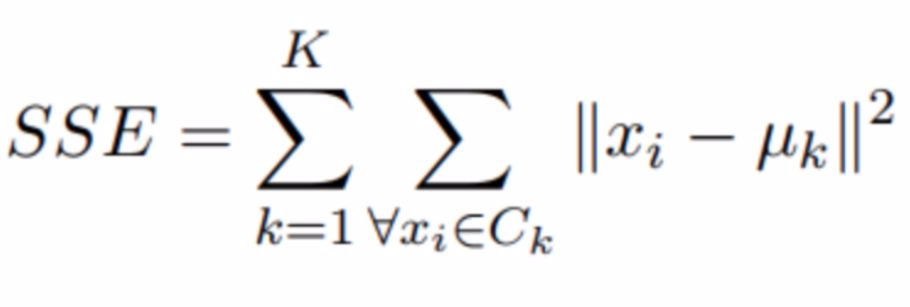
平方誤差和的公式。
這個公式是什麼意思?平方誤差和(SSE)是一種聚類度量指標,其思想非常簡單。它是一個計算數據中每個實例到其最接近質心的平方距離的值。算法優化的目標是儘量減小這個值的大小。
可以使用之前的目標函數框架來實現平方誤差和,具體如下:
@add_metaclass(ABCMeta)class PartitionalClusteringObjectiveFunction(ObjectiveFunction): def __init__(self, dim, n_clusters, data): super(PartitionalClusteringObjectiveFunction, self)\ .__init__('PartitionalClusteringObjectiveFunction', dim, 0.0, 1.0) self.n_clusters = n_clusters self.centroids = {} self.data = data def decode(self, x): centroids = x.reshape(self.n_clusters, self.dim) self.centroids = dict(enumerate(centroids)) @abstractmethod def evaluate(self, x): passclass SumOfSquaredErrors(PartitionalClusteringObjectiveFunction): def __init__(self, dim, n_clusters, data): super(SumOfSquaredErrors, self).__init__(dim, n_clusters, data) self.name = 'SumOfSquaredErrors' def evaluate(self, x): self.decode(x) clusters = {key: [] for key in self.centroids.keys()} for instance in self.data: distances = [np.linalg.norm(self.centroids[idx] - instance) for idx in self.centroids] clusters[np.argmin(distances)].append(instance) sum_of_squared_errors = 0.0 for idx in self.centroids: distances = [np.linalg.norm(self.centroids[idx] - instance) for instance in clusters[idx]] sum_of_squared_errors += sum(np.power(distances, 2)) return sum_of_squared_errors處理真實數據
現在開始嘗試處理一些真實的數據,並測試 ABC 算法處理聚類問題的能力。此處我們使用著名的 Iris 數據集進行測試。
初始的四維數據集包含了從三種植物身上提取得到的特徵。爲了便於可視化,此處只使用該數據集的兩個維度。觀察該數據集第二維和第四維之間的關係:
import matplotlib.pyplot as pltfrom abc import ABCfrom objection_function import SumOfSquaredErrorsfrom sklearn.datasets import load_irisfrom sklearn.preprocessing import MinMaxScalerdata = MinMaxScaler().fit_transform(load_iris()['data'][:, [1,3]])plt.figure(figsize=(9,8))plt.scatter(data[:,0], data[:,1], s=50, edgecolor='w', alpha=0.5)plt.title('Original Data')上述代碼的輸出結果如下:
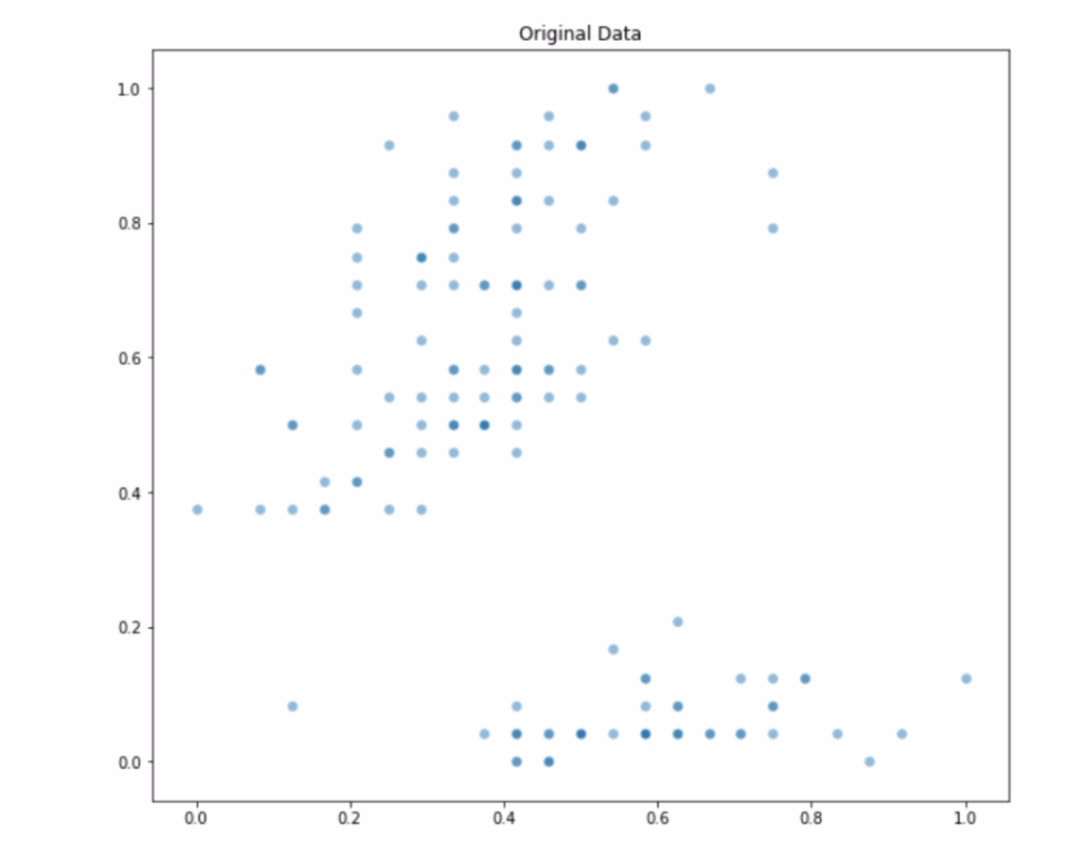
原始數據分佈。
由於使用這些數據作爲基準進行測試,因此其最佳劃分已知,它是由這三種花的原始分佈給出的。我們可以用下面的 Python 代碼可視化 Iris 數據集的原始優化分區:
colors = ['r', 'g', 'y']target = load_iris()['target']plt.figure(figsize=(9,8))for instance, tgt in zip(data, target): plt.scatter(instance[0], instance[1], s=50, edgecolor='w', alpha=0.5, color=colors[tgt])plt.title('Original Groups')它顯示瞭如下分佈:
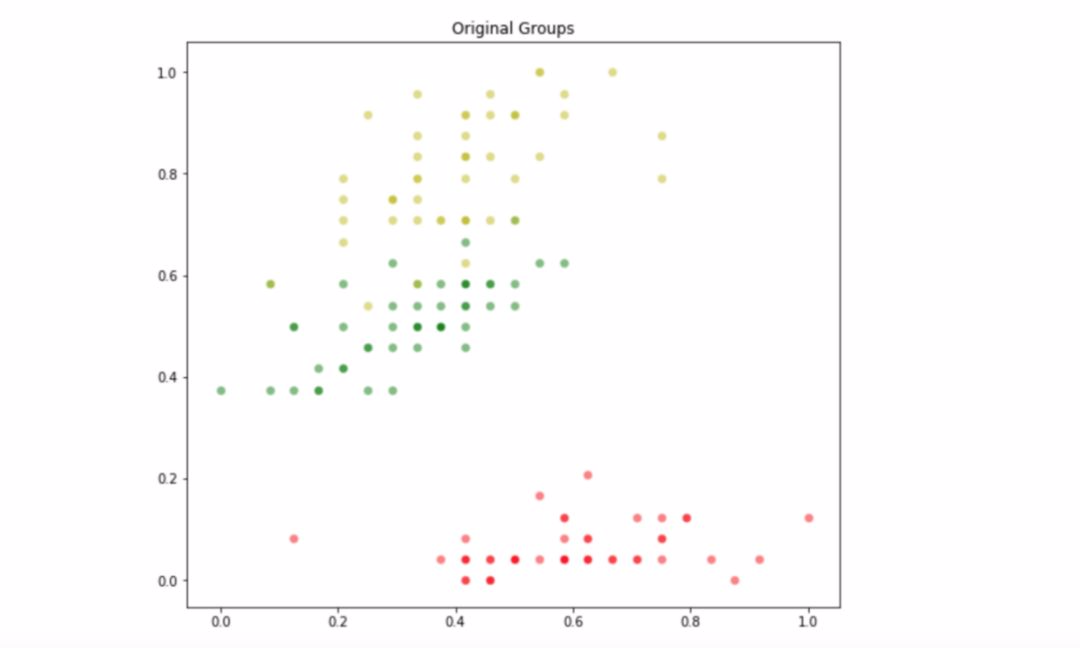
數據集的初始劃分。
由於已經知道這個樣本數據的原始最優分區是什麼,接下來的實驗將測試 ABC 算法能否找到一個接近最優解的解決方案。使用平方誤差和作爲目標函數,並將分區數設置爲 3。
由於隨機初始化,生成的質心的順序可能與類的順序不匹配。因此在 ABC 算法的輸出圖像中,組的顏色可能會不匹配。不過這並不重要,因爲人們更關心的是對應分組的外觀。
objective_function = SumOfSquaredErrors(dim=6, n_clusters=3, data=data)optimizer = ABC(obj_function=objective_function, colony_size=30, n_iter=300, max_trials=100)optimizer.optimize()def decode_centroids(centroids, n_clusters, data): return centroids.reshape(n_clusters, data.shape[1])centroids = dict(enumerate(decode_centroids(optimizer.optimal_solution.pos, n_clusters=3, data=data)))def assign_centroid(centroids, point): distances = [np.linalg.norm(point - centroids[idx]) for idx in centroids] return np.argmin(distances)custom_tgt = []for instance in data: custom_tgt.append(assign_centroid(centroids, instance))colors = ['r', 'g', 'y']plt.figure(figsize=(9,8))for instance, tgt in zip(data, custom_tgt): plt.scatter(instance[0], instance[1], s=50, edgecolor='w', alpha=0.5, color=colors[tgt])for centroid in centroids: plt.scatter(centroids[centroid][0], centroids[centroid][1], color='k', marker='x', lw=5, s=500)plt.title('Partitioned Data found by ABC')代碼的輸出如下:
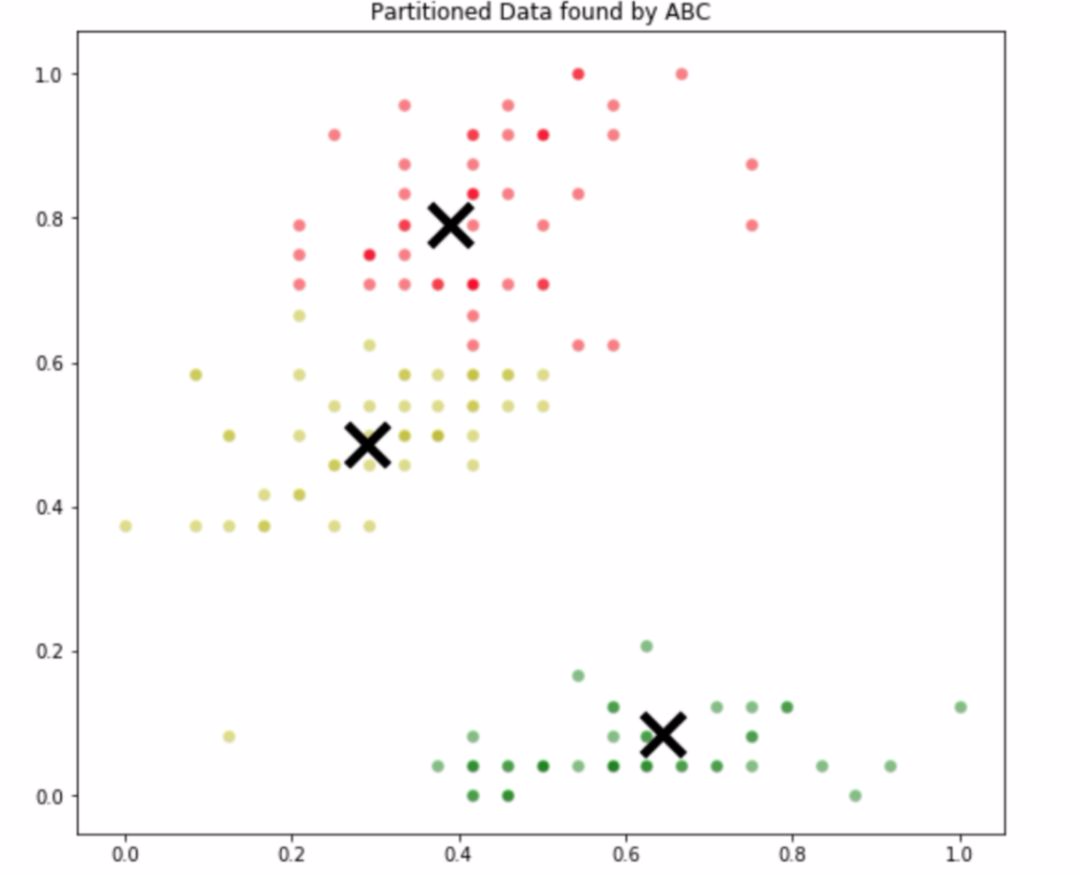
ABC 算法生成的分區
仔細觀察原始分區和 ABC 算法生成的分區,可以看到 ABC 算法能夠找到一個十分接近最優解的分區方法。這證明了用於聚類的 ABC 算法到底有多強大。還可以查看 ABC 算法的優化曲線來看看優化過程是如何進行的:
itr = range(len(optimizer.optimality_tracking))val = optimizer.optimality_trackingplt.figure(figsize=(10, 9))plt.plot(itr, val)plt.title('Sum of Squared Errors')plt.ylabel('Fitness')plt.xlabel('Iteration')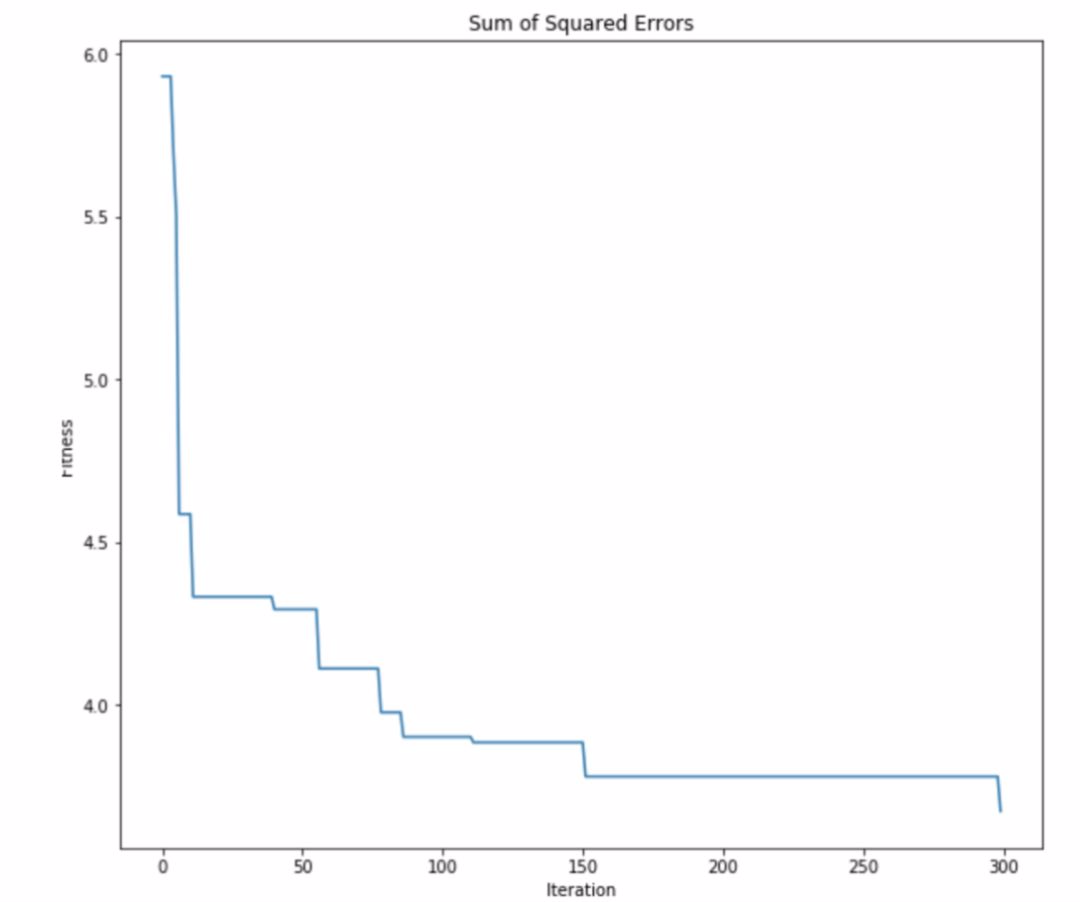
正如所料,ABC 算法能有效地最小化 SSE 目標函數。可以看到,集羣智能擁有一些強大的機制來處理優化問題。只要能將現實世界的問題簡化爲優化問題,就能很好地利用這些算法。
參考文獻:
A novel clustering approach: Artificial Bee Colony (ABC) algorithm—Dervis Karaboga, Celal Ozturk
A Clustering Approach Using Cooperative Artificial Bee Colony Algorithm—Wenping Zou, Yunlong Zhu, Hanning Chen, and Xin Sui
A Review on Artificial Bee Colony Algorithms and Their Applications to Data Clustering—Ajit Kumar , Dharmender Kumar , S. K. Jarial
A two-step artificial bee colony algorithm for clustering—Yugal Kumar, G. Sahoo
未來展望
本文通過實現人工蜂羣算法簡要介紹了集羣智能,以及如何利用它來解決一些有趣的問題:例如優化實際函數、修改 ABC 算法解決聚類問題。
這些算法有很多應用,如圖像分割、人工神經網絡訓練、數字圖像處理和模式識別、蛋白質結構預測等等。還有一些其他強大的羣體智能(SI)算法,如粒子羣優化(PSO)和魚羣搜索(FSS)等,它們也是非常有名的技術,並且也有一些有趣的應用。
原文鏈接:https://towardsdatascience.com/a-modified-artificial-bee-colony-algorithm-to-solve-clustering-problems-fc0b69bd0788