雷鋒網(公衆號:雷鋒網)按:本文轉自統計之都。原文是從張志華老師在第九屆中國R語言會議和上海交通大學的兩次講座中整理出來的。張志華老師是上海交通大學計算機科學與工程系教授,上海交通大學數據科學研究中心兼職教授,計算機科學與技術和統計學雙學科的博士生指導導師。在加入上海交通大學之前,是浙江大學計算機學院教授和浙江大學統計科學中心兼職教授。張老師主要從事人工智能、機器學習與應用統計學領域的教學與研究,迄今在國際重要學術期刊和重要的計算機學科會議上發表70餘篇論文,是美國「數學評論」的特邀評論員,國際機器學習旗艦刊物Journal of Machine Learning Research 的執行編委。其公開課《機器學習導論》和《統計機器學習》受到廣泛關注。
最近人工智能或者機器學習的強勢崛起,特別是剛剛過去的AlphaGo和韓國棋手李世石九段的人機大戰,再次讓我們領略到了人工智能或機器學習技術的巨大潛力,同時也深深地觸動了我。面對這一前所未有的技術大變革,作爲10多年以來一直從事統計機器學習一線教學與研究的學者,希望藉此機會和大家分享我個人的一些思考和反思。

我的演講主要包含兩部分,在第一部分,首先討論機器學習所蘊含的內在本質,特別是它和統計學、計算機科學、運籌優化等學科的聯繫,以及它和工業界、創業界相輔相成的關係。在第二部分,試圖用「多級」、「自適應」以及 「平均」等概念來簡約紛繁多彩的機器學習模型和計算方法背後的一些研究思路或思想。
第一部分:回顧和反思
1、 什麼是機器學習
毋庸置疑,大數據和人工智能是當今是最爲時髦的名詞,它們將爲我們未來生活帶來深刻的變革。數據是燃料,智能是目標,而機器學習是火箭,即通往智能的技術途徑。機器學習大師Mike Jordan和Tom Mitchell 認爲機器學習是計算機科學和統計學的交叉,同時是人工智能和數據科學的核心。
「It is one of today’s rapidly growing technical fields, lying at the intersection of computer science and statistics, and at the core of artificial intelligence and data science」 ---M. I. Jordan
通俗地說,機器學習就是從數據裏面挖掘出有用的價值。數據本身是死的,它不能自動呈現出有用的信息。怎麼樣才能找出有價值的東西呢?第一步要給數據一個抽象的表示,接着基於表示進行建模,然後估計模型的參數,也就是計算,爲了應對大規模的數據所帶來的問題,我們還需要設計一些高效的實現手段。
我把這個過程解釋爲機器學習等於矩陣+統計+優化+算法。首先,當數據被定義爲一個抽象的表示時,往往形成一個矩陣或者一個圖,而圖其實也是可以理解爲矩陣。統計是建模的主要工具和途徑,而模型求解大多被定義爲一個優化問題,特別是,頻率統計方法其實就是一個優化問題。當然,貝葉斯模型的計算牽涉隨機抽樣方法。而之前說到面對大數據問題的具體實現時,需要一些高效的方法,計算機科學中的算法和數據結構裏有不少好的技巧可以幫助我們解決這個問題。
借鑑Marr的關於計算機視覺的三級論定義,我把機器學習也分爲三個層次:初級、中級和高級。初級階段是數據獲取以及特徵的提取。中級階段是數據處理與分析,它又包含三個方面,首先是應用問題導向,簡單地說,它主要應用已有的模型和方法解決一些實際問題,我們可以理解爲數據挖掘;第二,根據應用問題的需要,提出和發展模型、方法和算法以及研究支撐它們的數學原理或理論基礎等,我理解這是機器學習學科的核心內容。第三,通過推理達到某種智能。最後,高級階段是智能與認知,即實現智能的目標。從這裏,我們看到,數據挖掘和機器學習本質上是一樣的,其區別是數據挖掘更接地於數據庫端,而機器學習則更接近於智能端。
2、 統計與計算
機學家通常具有強的計算能力和解決問題的直覺,而統計學家長於理論分析,具有強的建模能力,因此,兩者有很好的互補性。
Boosting, SVM 和稀疏學習是機器學習界也是統計界,在近十年或者是近二十年來,最活躍的方向,現在很難說誰比誰在其中做的貢獻更大。比如,SVM的理論其實很早被Vapnik等提出來了,但計算機界發明了一個有效的求解算法,而且後來又有非常好的實現代碼被陸續開源給大家使用,於是SVM就變成分類算法的一個基準模型。再比如,KPCA是由計算機學家提出的一個非線性降維方法,其實它等價於經典MDS。而後者在統計界是很早就存在的,但如果沒有計算機界從新發現,有些好的東西可能就被埋沒了。
機器學習現在已成爲統計學的一個主流方向,許多著名統計系紛紛招聘機器學習領域的博士爲教員。計算在統計已經變得越來越重要,傳統多元統計分析是以矩陣爲計算工具,現代高維統計則是以優化爲計算工具。另一方面,計算機學科開設高級統計學課程,比如統計學中的核心課程「經驗過程」。
我們來看機器學習在計算機科學佔什麼樣的地位。最近有一本還沒有出版的書 「Foundation of Data Science, by Avrim Blum, John Hopcroft, and Ravindran Kannan,」作者之一John Hopcroft是圖靈獎得主。在這本書前沿部分,提到了計算機科學的發展可以分爲三個階段:早期、中期和當今。早期就是讓計算機可以運行起來,其重點在於開發程序語言、編譯原理、操作系統,以及研究支撐它們的數學理論。中期是讓計算機變得有用,變得高效。重點在於研究算法和數據結構。第三個階段是讓計算機具有更廣泛的應用,發展重點從離散類數學轉到概率和統計。那我們看到,第三階段實際上就是機器學習所關心的。
現在計算機界戲稱機器學習「全能學科」,它無所不在。一方面,機器學習有其自身的學科體系;另一方面它還有兩個重要的輻射功能。一是爲應用學科提供解決問題的方法與途徑。說的通俗一點,對於一個應用學科來說,機器學習的目的就是把一些難懂的數學翻譯成讓工程師能夠寫出程序的僞代碼。二是爲一些傳統學科,比如統計、理論計算機科學、運籌優化等找到新的研究問題。
3、 機器學習發展的啓示
機器學習的發展歷程告訴我們:發展一個學科需要一個務實的態度。時髦的概念和名字無疑對學科的普及有一定的推動作用,但學科的根本還是所研究的問題、方法、技術和支撐的基礎等,以及爲社會產生的價值。
機器學習是個很酷的名字,簡單地按照字面理解,它的目的是讓機器能像人一樣具有學習能力。但在前面我們所看到的,在其10年的黃金髮展期,機器學習界並沒有過多地炒作「智能」,而是更多地關注於引入統計學等來建立學科的理論基礎,面向數據分析與處理,以無監督學習和有監督學習爲兩大主要的研究問題,提出和開發了一系列模型、方法和計算算法等,切實地解決工業界所面臨的一些實際問題。近幾年,因應大數據的驅動和計算能力的極大提升,一批面向機器學習的底層架構又先後被開發出來,深度神經網絡的強勢崛起給工業界帶來了深刻的變革和機遇。
機器學習的發展同樣詮釋了多學科交叉的重要性和必要性。然而這種交叉不是簡單地彼此知道幾個名詞或概念就可以的,是需要真正的融化貫通。Mike Jordan教授既是一流的計算機學家,又是一流的統計學家,所以他能夠承擔起建立統計機器學習的重任。而且他非常務實,從不提那些空洞無物的概念和框架。他遵循自下而上的方式,即先從具體問題、模型、方法、算法等着手,然後一步一步系統化。Geoffrey Hinton教授是世界最著名的認知心理學家和計算機科學學家。雖然他很早就成就斐然,在學術界名聲卓越,但他一直活躍在一線,自己寫代碼。他提出的許多想法簡單、可行又非常有效,因此被稱爲偉大的思想家。正是由於他的睿智和力行,深度學習技術迎來了革命性的突破。
機器學習這個學科同時是兼容並收。我們可以說機器學習是由學術界、工業界、創業界(或競賽界)等合力而造就的。學術界是引擎,工業界是驅動,創業界是活力和未來。學術界和工業界應該有各自的職責和分工。學術界職責在於建立和發展機器學習學科,培養機器學習領域的專門人才;而大項目、大工程更應該由市場來驅動,由工業界來實施和完成。
第二部分:幾個簡單的研究思路
在這部分,我的關注則回到機器學習的研究本身上來。機器學習內容博大精深,而且新方法、新技術正源源不斷地被提出、被發現。這裏,我試圖用「多級」、「自適應」以及 「平均」等概念來簡約紛繁多彩的機器學習模型和計算方法背後的一些研究思路和思想。希望這些對大家理解機器學習已有的一些模型、方法以及未來的研究有所啓發。
1. 多級 (Hierarchical)
首先,讓我們來關注「多級」這個技術思想。我們具體看三個例子。
第一個例子是隱含數據模型,它就是一種多級模型。作爲概率圖模型的一種延伸,隱含數據模型是一類重要的多元數據分析方法。隱含變量有三個重要的性質。第一,可以用比較弱的條件獨立相關性代替較強的邊界獨立相關性。著名的de Finetti 表示定理支持這點。這個定理說,一組可以交換的隨機變量當且僅當在某個參數給定條件下,它們可以表示成一組條件隨機變量的混合體。這給出了一組可以交換的隨機變量的一個多級表示。即先從某個分佈抽一個參數,然後基於這個參數,獨立地從某個分佈抽出這組隨機變量。第二,可以通過引入隱含變量的技術來方便計算,比如期望最大算法以及更廣義的數據擴充技術就是基於這一思想。具體地,一些複雜分佈,比如t-distribution, Laplace distribution 則可以通過表示成高斯尺度混合體來進行簡化計算。第三,隱含變量本身可能具有某種有可解釋的物理意思,這剛好符合應用的場景。比如,在隱含狄利克雷分配(LDA)模型,其中隱含變量具有某種主題的意思。
第一個例子是隱含數據模型,它就是一種多級模型。作爲概率圖模型的一種延伸,隱含數據模型是一類重要的多元數據分析方法。隱含變量有三個重要的性質。第一,可以用比較弱的條件獨立相關性代替較強的邊界獨立相關性。著名的de Finetti 表示定理支持這點。這個定理說,一組可以交換的隨機變量當且僅當在某個參數給定條件下,它們可以表示成一組條件隨機變量的混合體。這給出了一組可以交換的隨機變量的一個多級表示。即先從某個分佈抽一個參數,然後基於這個參數,獨立地從某個分佈抽出這組隨機變量。第二,可以通過引入隱含變量的技術來方便計算,比如期望最大算法以及更廣義的數據擴充技術就是基於這一思想。具體地,一些複雜分佈,比如t-distribution, Laplace distribution 則可以通過表示成高斯尺度混合體來進行簡化計算。第三,隱含變量本身可能具有某種有可解釋的物理意思,這剛好符合應用的場景。比如,在隱含狄利克雷分配(LDA)模型,其中隱含變量具有某種主題的意思。
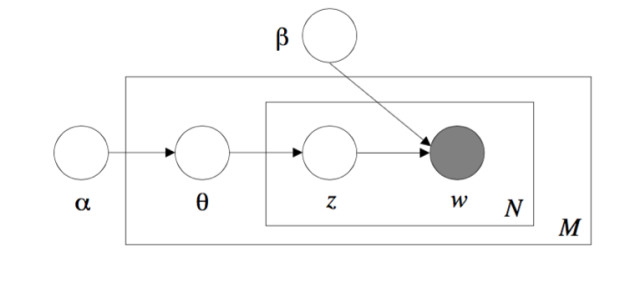
Laten Dirichlet Allocation
第二個例子,我們來看多級貝葉斯模型。在進行MCMC抽樣後驗估計時,最上層的超參數總是需要先人爲給定的,自然地,MCMC算法收斂性能是依賴這些給定的超參數的,如果我們對這些參數的選取沒有好的經驗,那麼一個可能做法我們再加一層,層數越多對超參數選取的依賴性會減弱。
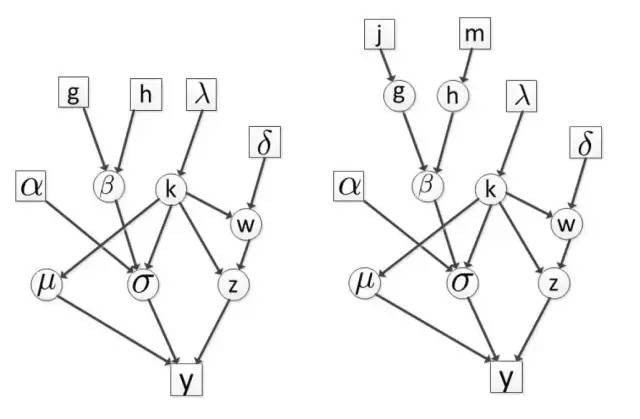
Hierarchical Bayesian Model
第三例子,深度學習蘊含的也是多級的思想。如果把所有的節點全部的放平,然後全連接,就是一個全連接圖。而CNN深度網絡則可以看成對全連接圖的一個結構正則化。正則化理論是統計學習的一個非常核心的思想。CNN和RNN是兩大深度神經網絡模型,分別主要用於圖像處理和自然語言處理中。研究表明多級結構具有更強的學習能力。
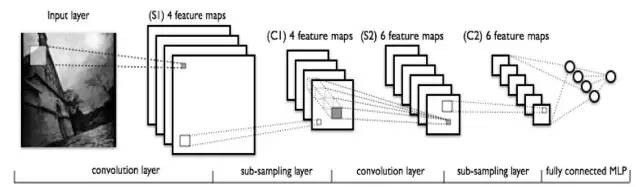
Deep Learning
2. 自適應 (Adaptive)
我們來看自適應這個技術思路,我們通過幾個例子來看這個思路的作用。
第一個例子是自適應重要採樣技術。重要採樣方法通常可以提高均勻採樣的性能,而自適應則進一步改善重要採樣的性能。
第二個例子,自適應列選擇問題。給定一個矩陣A,我們希望從中選取部分列構成一個矩陣C,然後用CC^+A去近似原矩陣A,而且希望近似誤差儘可能小。這是一個NP難問題。在實際上,可以通過一個自適應的方式,先採出非常小一部分C_1,由此構造一個殘差,通過這個定義一個概率,然後用概率再去採一部分C_2, 把C_1 和 C_2 合在一起組成C。
第三個例子,是自適應隨機迭代算法。考慮一個帶正則化的經驗風險最小問題,當訓練數據非常多時,批處理的計算方式非常耗時,所以通常採用一個隨機方式。存在的隨機梯度或者隨機對偶梯度算法可以得到參數的一個無偏估計。而通過引入自適應的技術,可以減少估計的方差。
第四個例子,是Boosting分類方法。它自適應調整每個樣本的權重,具體地,提高分錯樣本的權重,而降低分對樣本的權重。
3. 平均 (Averaging)
其實,boosting 蘊含着平均思想,即我最後要談的技術思路。簡單地說,boosting是把一組弱分類器集成在一起,形成一個強的分類器。第一好處是可以降低擬合的風險。第二,可以降低陷入局部的風險。第三,可以擴展假設空間。Bagging同樣是經典的集成學習算法,它把訓練數據分成幾組,然後分別在小數據集上訓練模型,通過這些模型來組合強分類器。另外這是一個兩層的集成學習方式。
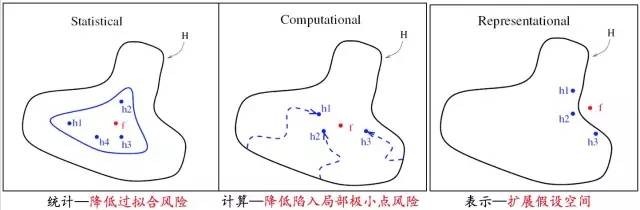
經典的Anderson 加速技術則是通過平均的思想來達到加速收斂過程。具體地,它是一個疊加的過程,這個疊加的過程通過求解一個殘差最小得到一個加權組合。這個技術的好處,是沒有增加太多的計算,往往還可以使數值迭代變得較爲穩定。
另外一個使用平均的例子是分佈式計算中。很多情況下分佈式計算不是同步的,是異步的,如果異步的時候怎麼辦?最簡單的是各自獨立做,到某個時候把所有結果平均,分發給各個worker, 然後又各自獨立運行,如此下去。這就好像一個熱啓動的過程。
正如我們已經看到,這些思想通常是組合在一起使用的,比如boosting模型。我們多級、自適應和平均的思想很直接,但的確也很有用。
