不一樣在哪兒呢?可能是本文沒有按照「正常」的深度學習博客結構:從數學講起,然後介紹論文、實現,最後講應用。我希望用講故事的方式來介紹深度學習,這可能要比只介紹信息和公式要更加平易近人一些。
我爲什麼要寫這篇深度學習簡介?

有時候,把自己的思考過程記錄下來非常重要。
目前,深度學習(Deep Learning)是數據科學、AI、技術和人類生活中重要的一部分,它值得我們去關注。你不能簡單地說:「深度學習就是往神經網絡中添加一個層,哇,神奇!」。不,不是這樣。我希望讀完本文後,大家會對深度學習有不一樣的認識。
深度學習時間線
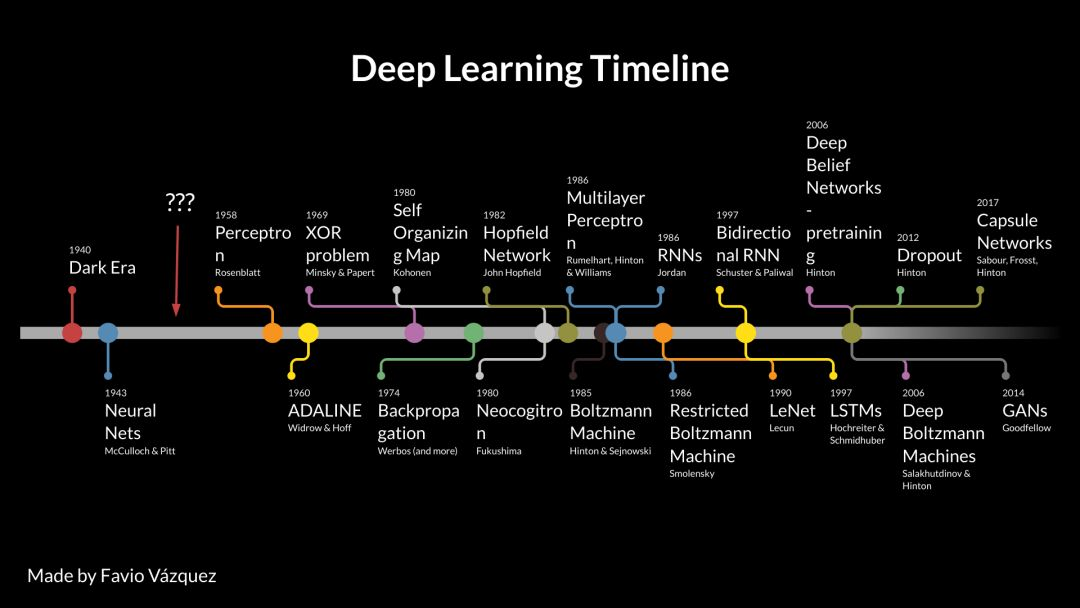
我根據多篇論文和其他文章的內容繪製了這份時間線,旨在使大家看到深度學習不只是神經網絡。在它的發展過程中出現了真正的理論進步、軟件和硬件進展。
深度學習有何「奇怪」之處?

深度學習已經出現很久了,那麼爲什麼它直到最近 5-7 年才聞名於世,並迅速發展起來呢?
如前所述,直到 21 世紀初,我們仍然缺乏訓練非常深層神經網絡的可靠途徑。現在,隨着多個簡單卻重要的理論、算法進步,硬件發展(大部分是 GPU,現在是 TPU)和數據的指數級增長和積累,深度學習快速發展,並改變我們做機器學習的方式。
深度學習也是非常活躍的研究領域,今天,衆多研究者們仍在尋找最好的模型、網絡拓撲、最好的超參數優化方法等等。要想像其他活躍的科學領域一樣緊跟研究成果很難,但是並非不可能。
Hofer 等人在論文《Deep Learning with Topological Signatures》如此介紹拓撲和機器學習:
近期代數拓撲方法僅在機器學習社區出現,最顯著的是,它出現在術語「拓撲數據分析」(topological data analysis,TDA)下面。TDA 幫助我們從數據中推斷出相關拓撲和幾何信息,因此它提供了一種看待多種機器學習問題的新型、有益的視角。
對我們來說很幸運的是,有很多人在幫助我們理解和消化此類信息,比如吳恩達的課程、一些相關博客等等。
參考閱讀:
機器之心專訪吳恩達,深度學習課程項目 Deeplearning.ai 正式發佈
吳恩達 Deeplearning.ai 課程學習全體驗:深度學習必備課程(已獲證書)
入門 | 吳恩達 Deeplearning.ai 全部課程學習心得分享
資源 | 吳恩達 deeplearning.ai 第四課學習心得:卷積神經網絡與計算機視覺
資源 | 吳恩達 deeplearning.ai 五項課程完整筆記了解一下?
這對我來說有些奇怪或者不尋常,因爲正常情況下你必須花費一段時間(甚至好多年)才能消化論文或期刊中那麼多艱深、前沿的信息。當然,現在大部分科學領域從論文到一篇博客解讀的時間越來越快,雖然我認爲深度學習還有一些不一樣的感覺。
深度學習和表徵學習的突破性成果

機器學習領域中的大多數人都認爲,幾十年來深度學習論文中的每個最新思想(具體來說是指神經網絡或算法的新型拓撲結構和配置)都是機器學習中的最棒思想(要知道深度學習是機器學習的子領域)。
我在本文中用了很多次「學習」(learning)這個詞,那麼「學習」究竟是什麼意思呢?
在機器學習中,「學習」是指爲你正在分析和研究的數據自動搜索更好的數據表徵的過程(記得,這並不是讓機器來學習)。
「表徵」(representation)一詞在這個領域中特別重要,那什麼是「表徵」呢?「表徵」就是觀察數據的方式。
舉個例子,如下圖所示,假設問題是畫出一條直線將圖中的藍色圓和綠色三角形分開:
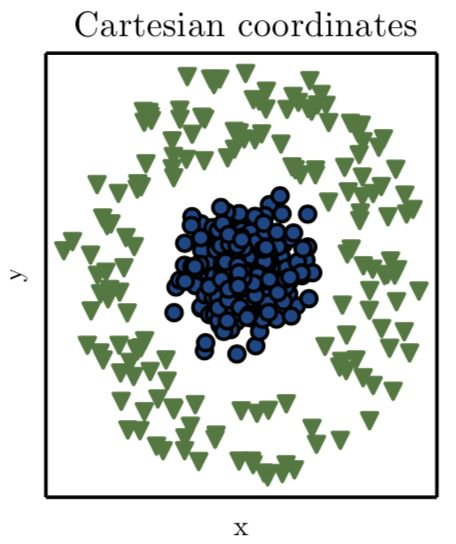
Ian Goodfellow et al. (《深度學習》, 2016)
在《深度學習》這本書中,作者解釋道:我們使用笛卡爾座標系來表徵數據,這時該問題不可解。
難道就沒辦法了嗎?當然不是。如果我們採用不同的方式來表徵數據,使得可以用直線分離不同的數據類型。這種方法在數學中已經出現了好幾百年。在這個例子中我們需要的僅僅是一次座標變換。通過座標變換,我們得到了問題的解:
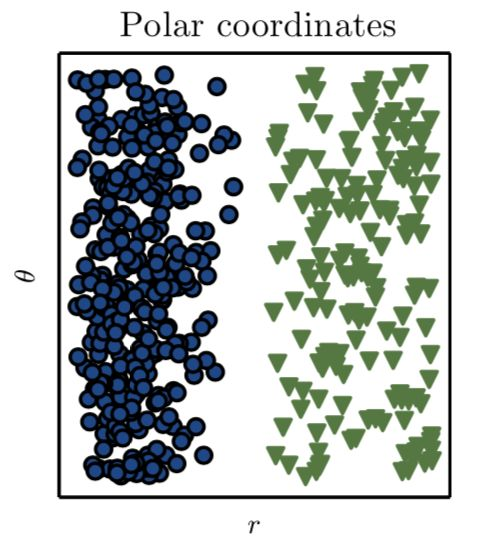
Ian Goodfellow et al. (《深度學習》, 2016)
現在我們就可以畫出一條直線來分離數據:
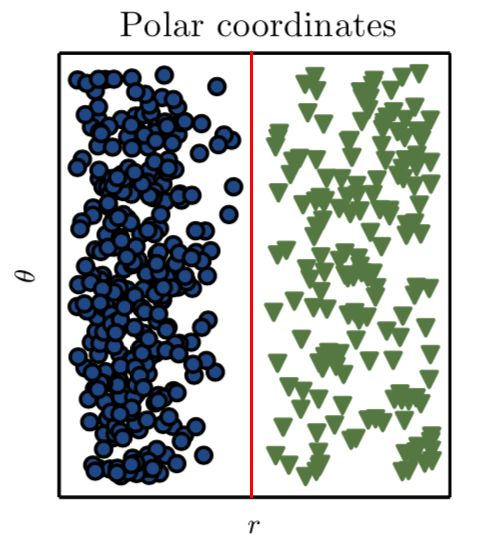
因此在這個例子中,我們通過手動探索並選擇了能獲得更好的表徵方式的變換。但是,假如我們能開發一個系統或程序來自動搜索不同的表徵(在這個例子中是座標變換),然後確定新方法的分類準確率的計算方式,這時候就變成了機器學習。
這一點很重要,深度學習是使用不同類型神經網絡的表徵學習,通過優化網絡的超參數來獲得對數據的更好表徵。
而沒有深度學習中的突破性研究,這一切也將不可能出現,這裏我列出幾個經典案例:
1:反向傳播
參考閱讀:
被 Geoffrey Hinton 拋棄,反向傳播爲何飽受質疑?(附 BP 推導)
A theoretical framework for Back-Propagation——Yann Lecun:http://yann.lecun.com/exdb/publis/pdf/lecun-88.pdf
2:更好的初始化網絡參數。需要記住的是:初始化策略需要根據所使用的激活函數來選擇。
參考閱讀:
「深度學習的權重初始化」——Coursera:https://www.coursera.org/learn/deep-neural-network/lecture/RwqYe/weight-initialization-for-deep-networks
How to train your Deep Neural Network:http://rishy.github.io/ml/2017/01/05/how-to-train-your-dnn/
斯坦福大學 CS231n Convolutional Neural Networks for Visual Recognition:http://cs231n.github.io/neural-networks-2/#init
3:更好的激活函數。這意味着,可以更快地逼近函數,從而實現更快的訓練。
參考閱讀:
4:Dropout:防止過擬合等問題。
Learning Less to Learn Better—Dropout in (Deep) Machine learning:https://medium.com/@amarbudhiraja/https-medium-com-amarbudhiraja-learning-less-to-learn-better-dropout-in-deep-machine-learning-74334da4bfc5
Geoffrey Hinton 等人的「Dropout: A Simple Way to Prevent Neural Networks from Overfitting」:http://www.jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf?utm_content=buffer79b43&utm_medium=social&utm_source=twitter.com&utm_campaign=buffer
5:卷積神經網絡(CNN)
參考閱讀:
Yann LeCun 等人的「Gradient-Based Learning Applied to Document Recognition」:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
6:殘差網絡(ResNet)
參考閱讀:
孫劍等人的論文「Deep Residual Learning for Image Recognition」:https://arxiv.org/abs/1512.03385v1
論文「Residual Networks of Residual Networks: Multilevel Residual Networks」:https://arxiv.org/abs/1608.02908
7:基於區域的 CNN,可用於目標檢測等。
參考閱讀:
論文「Rich feature hierarchies for accurate object detection and semantic segmentation」:https://arxiv.org/abs/1311.2524v5
先理解 Mask R-CNN 的工作原理,然後構建顏色填充器應用
從論文到測試:Facebook Detectron 開源項目初探
8:循環神經網絡(RNN)與 LSTM
參考閱讀:
9:生成對抗網絡(GAN)
參考閱讀:
Ian Goodfellow 等人的 GAN 論文:https://arxiv.org/abs/1406.2661v1
機器之心 GitHub 項目:GAN 完整理論推導與實現,Perfect!
10:Geoffrey Hinton 近期提出的 Capsule
終於,Geoffrey Hinton 那篇備受關注的 Capsule 論文公開了
淺析Geoffrey Hinton最近提出的Capsule計劃
Capsule 官方代碼開源之後,機器之心做了份核心代碼解讀
當然,還有很多其它的重要成果。我認爲正是以上所列舉的研究給我們帶來了重要的理論和算法上的突破,並改變了世界,推動了深度學習的革命。
如何入門深度學習?

深度學習的入門並不容易,但我會盡我所能指導你完成這一階段。參考以下學習資源,但記住,你需要的不僅僅是觀看視頻和閱讀論文,還需要不斷地理解、編程、寫代碼、經歷失敗,然後成功。
-1. 請先學習 Python 和 R 語言:)
0. 學習吳恩達的深度學習課程
Siraj Raval 的視頻:Siraj Raval 非常 amazing,他可以用風趣易懂的方式來解釋複雜的概念。你可以在 YouTube 上關注他的個人頻道,其中這兩個視頻非常棒:
François Chollet 的兩本書:
Deep Learning with Python
Deep Learning with R
分佈式深度學習
深度學習是數據科學家應該學習的最重要的工具和理論之一。我們很幸運,有那麼多深度學習方向的研究、軟件、工具和硬件被開發出來。
深度學習的計算成本很昂貴,即使在理論、軟件和硬件有所進展的情況下,我們也需要大數據和分佈式機器學習的發展來提升深度學習的性能和效率。爲此,人們開發出了分佈式框架(Spark)和深度學習庫(TensorFlow、PyTorch 和 Keras)。
參考閱讀:
學習了!谷歌今日上線基於 TensorFlow 的機器學習速成課程(中文版)
分佈式 TensorFlow 入坑指南:從實例到代碼帶你玩轉多機器深度學習
分佈式 Keras(Keras+Spark):https://github.com/cerndb/dist-keras
在谷歌雲上運行 TensorFlow 和 Spark:https://cloud.google.com/blog/big-data/2017/11/using-apache-spark-with-tensorflow-on-google-cloud-platform
使用深度學習完成任務

正如之前所說的,深度學習領域最重要的里程碑之一就是 TensorFlow 的創建與開源。
TensorFlow 是一個使用數據流圖進行數學計算的開源軟件庫,圖中的節點表示數學運算,而圖的邊表示在節點之間通信的多維數據陣列(張量)。

上圖是廣義相對論黎曼張量中的張量運算。
張量,從數學定義上看,就是簡單的數或函數的陣列,根據座標變換的特定規則進行變換。
但是在機器學習和深度學習領域中,張量是向量和矩陣在更高維度上的泛化形式。TensorFlow 將張量表示爲基礎數據類型的 n 維數組。
我們在深度學習中廣泛使用張量,但是你不必成爲這方面的專家,只需要稍微瞭解就足夠了。
參考閱讀:
現在你已經瞭解了我之前提到的突破和編程框架(如 TensorFlow 或 Keras),那麼你應該明白自己需要了解和使用深度學習的哪些方面了。
但是目前我們使用深度學習取得了什麼成就?下面我列舉了一些(來自 François Chollet 的書):
接近人類水平的圖像識別能力;
接近人類水平的語音識別能力;
接近人類水平的手寫體轉錄能力;
機器翻譯水平提高;
文本轉語音水平提高;
數字助手,如 Google Now 或 Amazon Alexa;
接近人類水平的自動駕駛能力;
廣告定向投放水平提高;
網頁搜索結果優化;
自然語言問答能力提高;
超越人類的圍棋水平。
參考閱讀:
30 AMAZING APPLICATIONS OF DEEP LEARNING:http://www.yaronhadad.com/deep-learning-most-amazing-applications/
關於深度學習的未來,我認爲 GUI 和 AutoML 是深度學習不久後能夠達到的。不要誤會,我喜歡寫代碼,但是我也認爲以後我們寫的代碼數量會減少。我們不能重複浪費那麼多時間一遍一遍寫同樣的東西,因此我認爲這兩個功能(GUI 和 AutoML)將幫助數據科學家提高生產力,解決更多問題。
參考閱讀:
在簡單的 GUI 中完成這些任務的最好免費平臺之一是 Deep Cognition。其簡單的拖放界面可以幫助你輕鬆設計深度學習模型。Deep Learning Studio 具備先進的 AutoML 功能(幾乎可以一鍵完成),可以爲你的自定義數據集設計深度學習模型。
該平臺還是免費的~
我的意思是,這個領域的發展實在太迅速,現在我們已經可以使用簡單的 GUI 來學習本文中涉及的所有複雜和有趣的概念。
我喜歡這個平臺的原因是,你不需要安裝任何東西就可以寫代碼,用命令行或 Notebook 來使用 TensorFlow、Keras、Caffe、MXNet 等。
其它有趣的深度學習應用:
http://skejul.com/
https://www.microsoft.com/en-us/seeing-ai/
https://dialogflow.com/
原文鏈接:https://towardsdatascience.com/a-weird-introduction-to-deep-learning-7828803693b0