自然語言處理(NLP)是人工智能領域下的一個龐大分支,其中面臨很多機遇與挑戰。史丹佛大學李紀爲博士在他的畢業論文《Teaching Machines to Converse》中對 NLP 領域近期的發展進行了解讀。這篇博士論文從多個方面嘗試解決如今對話系統面臨的諸多問題:(1) 如何產生具體、貼切、有意思的答覆;(2) 如何賦予機器人格情感,從而產生具有一致性的回覆;(3) 最早提出使用對抗性學習方法來生成與人類水平相同的回覆語句——讓生成器與鑑別器不斷進行類似「圖靈測試」的訓練;(4) 最後提出了賦予機器人通過與人的交流自我更新的自學習模型。
李紀爲是第一位在斯坦福大學僅用三年畢業的計算機科學博士。在由劍橋大學研究員 Marek Rei 發佈的一項統計中,李紀爲博士在最近三年在世界所有人工智能研究者中,以第一作者發表的頂級會議文章數量高居第一位。李紀爲博士期間實習於 facebook 人工智能實驗室以及微軟研究院。截止本報道,李紀爲博士 google scholar 論文引用量超過 1,200. H-index 高達 20.(參見:《如何生物轉 CS,並在斯坦福大學三年拿到 PhD:獨家專訪李紀爲博士》)。
論文鏈接:https://github.com/jiweil/Jiwei-Thesis
李紀爲博士個人主頁:https://web.stanford.edu/~jiweil/
摘要
機器與人類溝通的能力長期以來一直與人工智能發展水平的標杆。這個想法可以追溯到上世紀 50 年代初,阿蘭·圖靈提出的圖靈測試來檢測人工智能的水平。圖靈提到,如果一個機器可以讓與他對話的人誤以爲它(機器)是人而不是機器,那就說明人工智能已經發展到了非常高的高度。
在過去幾十年裏,對話學習領域取得了長足的進展。不過常見的對話系統仍然面臨着諸如魯棒性、可擴展性和域適應性等挑戰:很多系統是從很小的手寫標記/範本數據集中學習規則,這樣既昂貴又難以擴展到其他領域中。另一方面,對話系統正在變得越來越複雜:它們通常包括很多互相分開的複雜模塊,這意味着它們無法適應我們收集到的越來越多的數據。
最近,隨着神經網絡模型的出現,早期系統無法處理的很多問題變得可以解決了:端到端神經網絡提供了可擴展和語言獨立的框架,在語義理解上爲自動回覆的產生提供了可能性。與此同時,神經網絡模型也帶來了很多新的挑戰,比如它們傾向於無趣泛泛的回答,如:「我不知道你在說什麼。」;再有,它們經常缺乏像人類一樣的人格特性,導致產生的回覆經常是不一致的;他們大多數情況僅僅是被動地回答問題,而沒有能力去主導對話。
本論文試圖解決這些挑戰。這篇論文主要涉及兩個方面,第一個方面是四在開放域對話生成系統中的幾個問題::(a)使用互信息避免無趣泛化的回答;(b)賦予機器人格,解決用戶一致性問題;(c)用強化學習手段,增加長期對話成功率;(d)使用對抗學習方法推動機器生成與人類水平相同的回覆。
第二個方面,我們嘗試開發交互問答系統:(a)讓機器具有提出問題的能力。通過問問題,擴大自己的知識庫而完善自己(b)提出交互式的模型,在線與人類進行交流,並通過與人類交流得到的反饋中,提高自己的水平。
第一章 介紹
利用語言進行對話一直是人類智慧的標籤之一,也幾乎是人類兒童學會的第一種技能——在生命中永遠不會停止使用。溝通/對話的意義超過了個人:通過對話,人們可以互相傳遞大量信息——其中的內容不僅包括周圍環境(提醒同伴小心森林裏的老虎),也包括我們自己(發出指令,談論個人需求等等)。這種能力是組織有效社會合作的必要條件。
在人工智能領域,企圖模仿人類語言交流能力的構想可以追溯到阿蘭·圖靈在 20 世紀 50 年代的構想(圖靈測試)。能夠通過圖靈測試的計算機被認爲具有接近人類智慧水平。
自圖靈測試被提出以來,一代代研究者提出了各種方法試圖通過測試,但我們目前距離完成任務還有很長一段路要走。在本論文中,我們受限簡要回顧一下過去幾十年里人們提出的各種系統。具體來說,這其中包括三種對話系統:開放領域聊天系統、目標導向的框架系統以及問答交互(QA)對話系統。我們會討論它們的成功應用、優缺點以及爲什麼它們仍然無法通過圖靈測試。本論文將着重討論如何改進聊天系統和交互式問答(QA)系統。
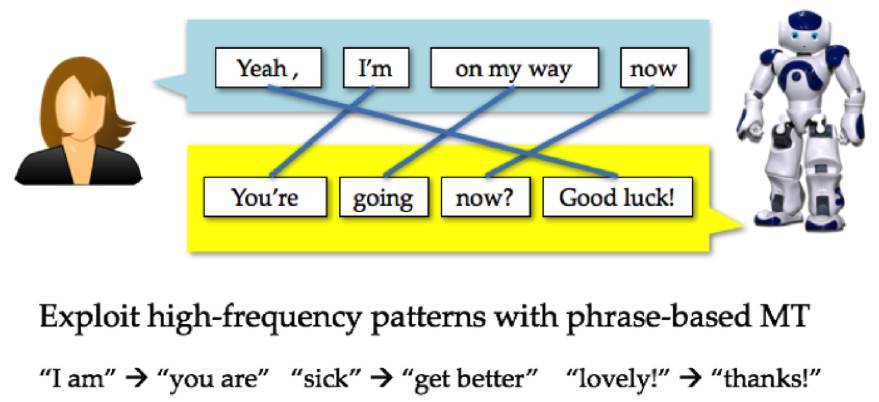
圖 1.1 使用 IBM 模型消息與回覆之間的字對齊。圖片來自 Michel Galley。
第二章 背景
2.1 序列到序列生成
SEQ2SEQ 模型可以被視爲一個用輸入內容生成目標句的基礎框架,適用於多種自然語言生成任務,例如利用給定的英文句子生成法語句子的機器翻譯;通過生成響應功能在接收到源信息時生成響應;在問答任務中針對問題做出回答;或是對一段文檔生成總結性短句等等。
本段將介紹語言模型基礎,循環神經網絡和長短期記憶網絡(LSTM),它們被視爲 SEQ2SEQ 模型的基礎。隨後,我們將詳細解讀 SEQ2SEQ 模型的基礎。最後,我們將討論不同 SEQ2SEQ 模型的算法,如注意力 (attention) 機制。
2.2 記憶網絡
記憶網絡(Weston et al., 2015;Sukhbaatar et al., 2015)是一類神經網絡模型,可以通過操作內存中的內容(存儲、取回、過濾和重用)來進行自然語言推理。記憶網絡中的存儲器部分可以嵌入長期記憶(例如,關於真實世界的常識)和短期上下文(例如,最近的幾段對話)。記憶網絡已被成功地應用於很多自然語言任務中了,例如問答系統(Bordes et al., 2014;Weston et al., 2016),語言建模(Sukhbaatar et al., 2015;Hill et al., 2016)以及對話(Doge et al., 2016;Bordes & Weston, 2017)。
2.3 策略梯度方法
策略梯度法(Aleksandrov et al., 1968;Williams, 1992)是一類強化學習模型,通過使用梯度下降預測獎勵的參數化策略來學習參數。與其他強化學習模型(如 Q 學習模型)比較而言,策略梯度方法不會受到如缺乏價值函數等方面的問題(因爲它不需要明確估算價值函數),或由於高維空間連續狀態或動作導致難以控制。
第三章 用交互信息避免泛化回覆
當我們將 SEQ2SEQ 模型應用與生成回覆的時候,一個嚴重的問題脫穎而出:神經對話模型總是會傾向於生成無意義的回覆,例如「I don't know」、「I don't know what you are talking about」(Serban et al., 2015;Vinyals & Le, 2015)。從表 3.1 中我們可以看出,很多排名靠前的回覆是泛化的。那些看起來更加有意義、更有針對性的回覆可以在非最佳列表中找到,但是排名非常靠後。這種現象是因爲通用性回覆如 I don't know 在對話數據集中相對較高的頻率。MLE(最大似然估計)目標函數對源到目標的單向依賴性進行了建模,由於無意義回覆沒有意義,有意義回覆多種多樣,系統總會傾向於生成這些無意義的回覆。直觀上,似乎不僅要考慮回覆與信息的相關性,也需要考慮傳遞的信息是否具有意義:如果回答是「I don't know」,我們就難以猜測對話者開始詢問的是什麼。
我們建議通過最大互信息(Maximum Mutual Information,MMI),作爲測量輸入和輸出之間的相互依賴性的優化目標來捕獲這種直覺,作爲傳統 MLE 目標函數中源到目標單向依賴性的反向。我們提出了使用 MMI 作爲目標函數神經生成模型的實際訓練和解碼策略。我們證明了使用 MMI 可以顯著減少泛化回覆產生的機率,在 BLEU 和人類評測的結果中得出了顯著提升性能的結果。

表 3.1 從 OpenSubtitles 數據集 2000 萬對話配對中訓練的 4 層 SEQ2SEQ 神經模型生成的回覆。解碼實現的 Beam size 被設爲 200。最大概率的回覆選項爲 N-best 列表中平均可能性對數似然的最高概率。更低的概率回覆是手動選擇的。
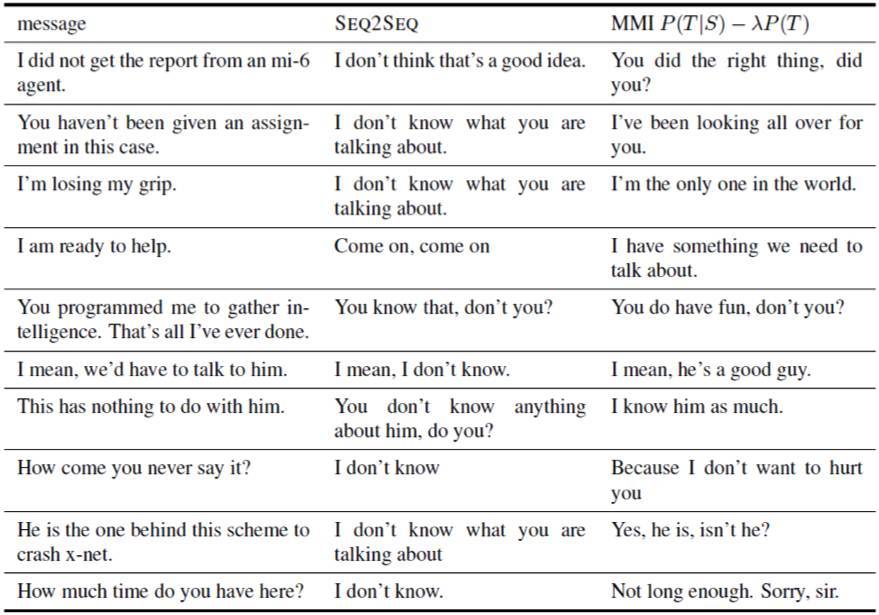
表 3.4:在 Open-Subtitles 數據集上 SEQ2SEQ 基線和 MMI-antiLM 模型的對比。
第四章 解決說話者一致性問題
目前聊天系統的一個嚴重的問題是缺少說話者一致性。這是由於訓練集中包含了不同的人的談話,而且一個解碼模型總是選擇最大似然的應答,從而使輸出變得非常的混亂且不一致。
在這一章中,我們討論了應對不一致問題的方法以及如何爲數據驅動的系統賦予合乎邏輯的「人格角色」(persona)以模仿類人的行爲,無論是個人助理,個性化的「阿凡達」智能體,亦或是遊戲角色。爲了這個目的,我們將把 persona 定義爲一個人工智能體在對話交流中所扮演或表現出來的一種特徵。persona 可以看成身份要素(背景事實或用戶外形)、語言行爲和交互方式的混合物。persona 是有適應性的,由於智能體在面對不同的人類談話者的時候需要按交互的需求表現不同的側面。

表 4.1:由 4 層 SEQ2SEQ 模型經過 2500 萬個推特對話片段訓練而生成的不一致應答。m 表示輸入的信息,r 表示生成的應答。
我們在 SEQ2SEQ 框架中探索了兩個 persona 模型,一個是單一說話者的「說話者模型」(SPEAKER MODEL),另一個是兩人對話的「說話者-受話者模型」(SPEAKER-ADDRESSEE MODEL)。SPEAKER MODEL 將說話者級別(speaker-level)的向量表示整合到 SEQ2SEQ 模型的目標部分中。類似地,SPEAKER-ADDRESSEE MODEL 通過談話者各自的嵌入構建一個交流的表示編碼兩個談話者的交流模式,再合併到 SEQ2SEQ 模型中。這些 persona 向量利用人和人對話數據訓練,並在測試時用於生成個性化的應答。我們在由電視劇腳本組成的推特對話數據集的開域語料庫上的實驗結果表明使用 persona 向量可以提升相關性能,如 BLEU 分數提高最多 20%,困惑度 (perplexity)12%,而相應的,由人類標註員評判的一致性也有同樣的提高。
第五章 讓對話更持久
在前兩節中,我們討論了聊天系統如何避免一般性的應答並對不同的問題生成滿足一致性的應答。目前爲止,我們談論的只是單輪(single-turn)應答的性質,但這只是對人類對話的過於簡化的近似。人類對話通常包含了數十到數百輪的交互。這些多輪對話通常是有結構的,比如以開場白啓動對話、設置語境、抓住對話重點等等,而且人類很擅長掌控一場對話中的信息流動,從而成功的進行長期的對話(包括總體一致性、意義性等等)。
目前的模型通過在給定的對話語境中使用最大似然度估計(maximum-likelihood estimation,MLE)目標函數預測下一個對話輪。由於無法成功的應對長期對話而經常陷入很多種困境:首先,SEQ2SEQ 模型傾向生成非常一般化的應答,正如第三章中所討論的:諸如「我不知道」這樣的應答;其次,如表 5.1 左側的兩個對話樣本所示,系統陷入了重複應答的無限循環中。這是由於基於 MLE 的 SEQ2SEQ 模型無法測量重複次數。在左下方的例子中,經過三輪後對話進入了死循環,兩個智能體都一直在生成枯燥、一般性的話語如「我不知道你在說什麼」、「你不知道你在說什麼」。
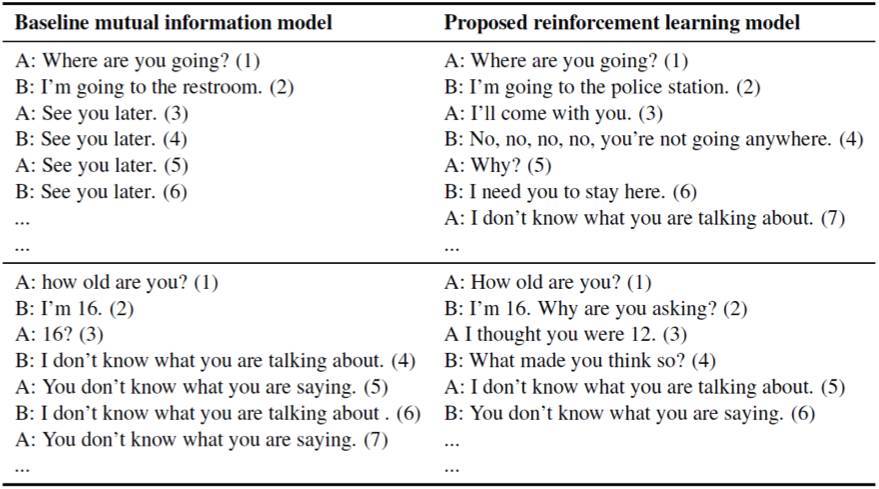
表 5.1:左列:使用 SEQ2SEQ 模型和 OpenSubtitles 數據集訓練的兩個智能體之間的對話模擬。第一輪(指標 1)是由作者輸入的,然後兩個智能體輪流應答,一個智能體的輸入將作爲另一個的在前生成輪。右列:使用我們提出的強化學習模型的對話模擬。新的模型擁有更具前瞻性的言辭(諸如「你爲什麼要問這個問題」、「我和你一起去」),在掉入對話黑洞之前能進行更持久的對話。
爲了應對這些挑戰,我們需要一個擁有以下能力的對話框架:
(1)更好的獎勵函數;
(2)對生成的某一句話的長期影響進行建模。
爲了達到這些目的,我們利用了強化學習,其在 MDP 和 POMDP 對話系統中早已被廣泛應用。我們提出了神經網絡強化學習生成方法,可以優化長期的獎勵。我們的模型使用了編碼器-解碼器架構作爲主幹,讓兩個機器人模擬對話。這樣的話,通過優化獎勵函數,探索可能行爲的空間。我們認爲針對對話好的獎勵函數應該有如下特點:好的談話是具備前瞻性或交互性(一輪帶動下一輪對話)、提供有用以及合乎邏輯的信息。我們可以通過這些方面定義獎勵函數,從而通過獎勵函數來優化編碼器-解碼器模型。
在訓練過程中,我們使用隨機梯度下降的更新策略,借用了 Yoshua Bengio 在 09 年提出的課程學習(Curriculum learning)的策略,逐漸增加對話模擬的輪數。這樣訓練的複雜度逐漸增加。
實驗結果(表 5.1 中右側的樣本結果)表明我們的方法產生了更持久的對話,並且相比使用 MLE 目標訓練的標準 SEQ2SEQ 模型,能生成更具交互性的應答。
兩個對話機器人之間的對話模擬
模擬兩個機器人輪流對話的過程是這樣的,在一開始,從訓練集中隨意找到一句話作爲輸入給第一個機器人,這個代理通過編碼器網絡把這個輸入編碼成一個隱層向量,然後解碼器來生成回答。之後,第二個機器人把之前那個機器人輸出的響應和對話歷史結合起來,重新通過編碼器網絡編碼得到一個隱層向量(相當於更新了對話的狀態),然後通過解碼器網絡生成一個新的回覆,並傳給第一個機器人。這個過程不斷被重複下去:
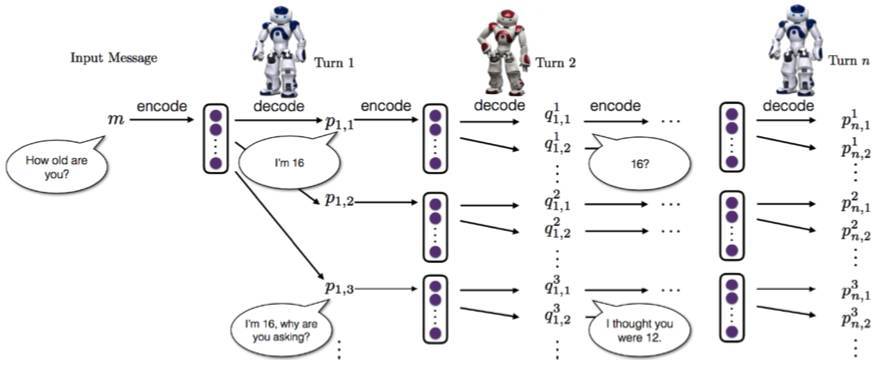
圖 5.1 描述了兩個對話機器人之間的對話模擬。
更具體地,我們把之前利用互信息訓練過的模型作爲初始模型,然後利用策略梯度方法來更新參數,以達到一個比較大的期待獎勵值的。對於一系列的響應,其獎勵函數爲:
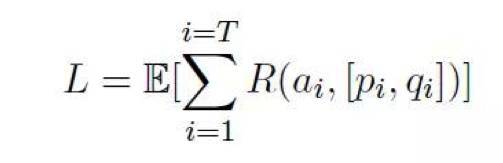
之後用強化學習對梯度進行更新。
在最終模型的訓練當中,課程學習的策略又一次被使用了。
模型起初只侷限於兩輪,後來慢慢增加到多輪。因爲每一輪的候選集合數目固定,所以每增加一輪,整個路徑空間就成倍變大,呈現一個指數級別的增長狀態,所以最終模型最多限定爲五輪對話。
第六章 通過對抗學習生成對話
在上一章(第五章)中,我們人工定義了一些理想對話的特性,即回覆的舒適性、信息性和條理性,然後用這些作爲強化學習回覆的獎勵。然而,衆所周知,人爲定義的獎勵函數無法覆蓋所有重要的方面,這個會導致最後得到的結果是次優的。解決這個涉及到兩個重要的問題:什麼是一個好的對話應該有的特徵,以及如何定量地計算這些特徵?
一個好的的對話模型應該能生成和人類對話沒有區別的話語,所以我們可以找一個類似圖靈測試的訓練目標。我們借用了計算機視覺中的對抗學習的想法:我們同時訓練兩個模型,一個是生成器(以神經 SEQ2SEQ 模型的形式),其定義了生成一個對話序列的概率,另一個是判別器,生成模型產生的對話進行標註,來判斷是人類生成還是機器生成。這個判別器和圖靈測試中的評估器非常類似。我們將這個任務作爲一個強化學習問題處理,其中機器生成的話語的品質由其是否能夠欺騙判別器誤以爲是人類生成的來測量。判別器的輸出作爲對生成器的獎勵,促進其生成更加擬人化的話語。
圖靈測試的想法(利用一個判別器從人類生成的文本中辨別出機器生成的)不僅可以用於訓練,還可以用於測試,因而可將其命名爲對抗評估(Adversarial evaluation)。對抗評估由 Bowman 等人於 2016 年首次提出用於評估語句生成的品質,並在 Kannan 和 Vinyals(2016 年)的「對話生成的語境」的工作中被初步研究。
實驗結果表明我們的方法,相比使用 MLE 目標函數訓練的標準的 SEQ2SEQ 模型,能生成更加交互性、趣味性和非重複的應答。
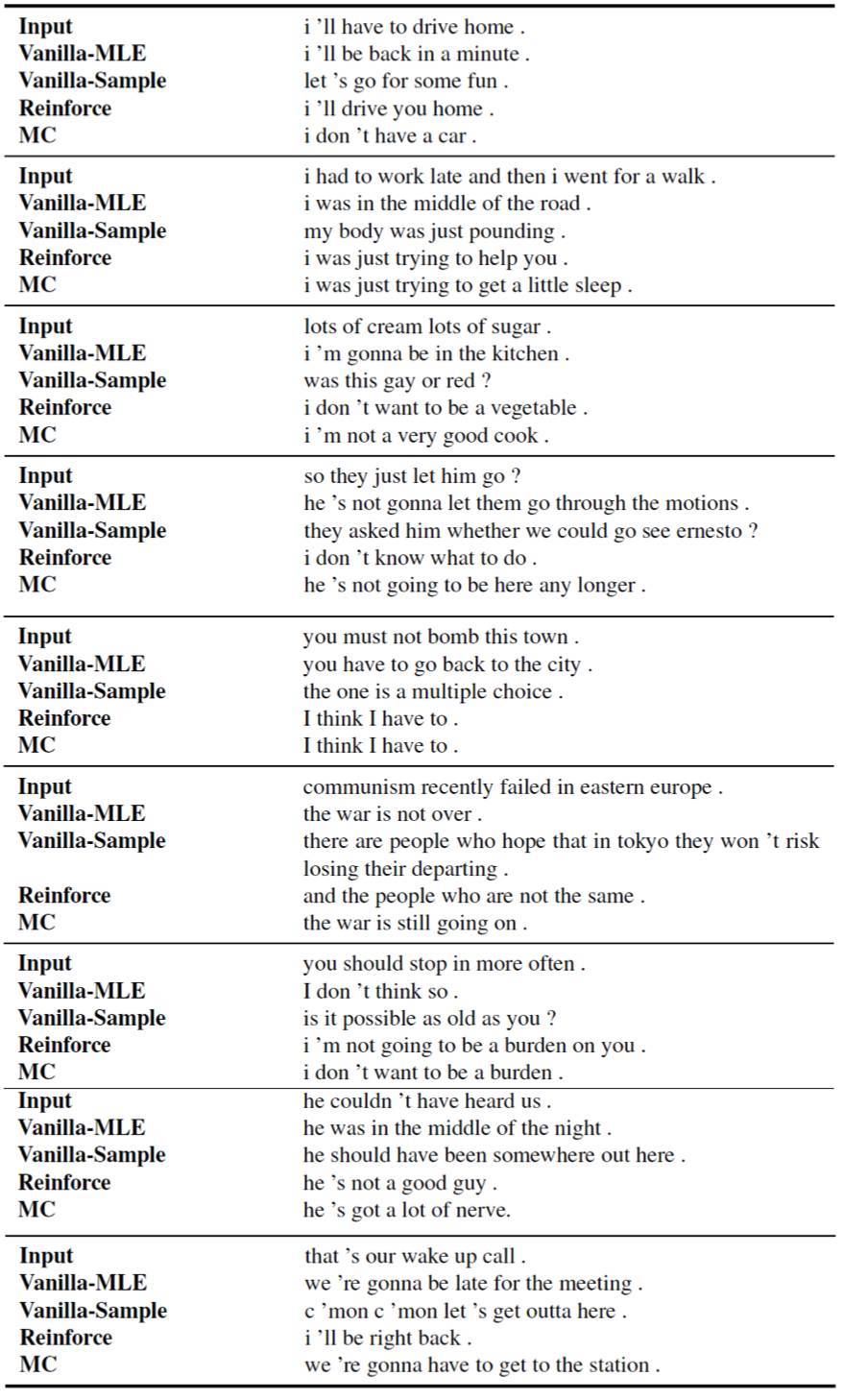
表 6.5:不同模型輸出的應答樣本
第七章 給機器人提問的能力
在這一章中我們討論瞭如何訓練機器學會提問。考慮一下以下的場景:當一個學生被老師提問的時候,由於對自己的答案不夠自信,學生可能會要求一些提示。一個好的對話智能體應該要具備這樣的和對話對象交互的能力。然而,最近的研究幾乎都集中於用訓練集中的固定回答學習,而不是通過交互。在這種情況下,當遇到令人迷惑的的情況比如一個未知的表面句子形式(詞組或結構)、一個語義複雜的句子或一個未知的詞,智能體要麼進行猜測(通常很糟糕),要麼將用戶重導向到其它的資源(例如,搜索引擎,正如我們在 Siri 上遇到的)。而人類相反,可以通過提問應對不同的情況。更重要的是,通過提問來獲取更多的知識。
第八章 利用人機迴圈(Human-in-the-Loop)的對話學習
在這一章中,我們將探索的方向是讓機器人跟人進行對話,得到反饋,然後機器人可以通過人的反饋來增強自己。該任務在的強化學習框架下,讓教師跟機器對話,從而讓機器自學習。對話將在問答任務的語境中進行,而機器必須在給定一個短故事或一系列事實的前提下,回答教師提出的一系列問題。我們考慮了兩種類型的反饋:傳統強化學習中的明確的數值獎勵,以及在人類對話中更爲自然的文本反饋。我們考慮了兩種在線訓練方案:
(i)使用易於分析和重複實驗的對話模擬器;
(ii)對話對象是真人,使用 Amazon Mechanical Turk 和機器對話。
我們探索了在線學習中的關鍵問題,比如機器如何使用最少的教師反饋進行最高效的訓練,機器如何處理不同類型的反饋信號,如何通過平衡數據和探索避免隱藏的風險(比如在線學習中不同類型的反饋的數量經常差別非常大)。我們的發現表明可以建立這樣一個系統,使模型從固定的數據開始訓練,與人交互,隨後更新自己的模型,新的模型再與人交互,繼續得到反饋,然後再一次更新模型。這個過程反覆持續下去。

圖 8.1:我們的模擬器實現的 10 個任務,其中評估了不同類型的應答和互反的反饋。每一個案例中給定 WikiMovies 中的例子,其中左側學生(機器)全部回答正確,而右側學生全部回答錯誤。學生的應答用紅色文本表示,學生用 S 表示,教師的反饋用藍色文本表示,而教師用 T 表示。爲了模仿學習過程,教師需要提供學生(以 S 表示)在任務 1 和 8 中做出的應答。(+)表示一次正面獎勵。
第九章 結論和未來工作
我們以討論聊天系統目前面臨的挑戰的形式結束這篇論文,併爲未來研究提供一些有益的啓發。
對於本論文中的較大語境 (context),我們使用帶有 attention 機制的分級 LSTM 模型捕捉語境,其中字詞級 LSTM 用於獲取每一個語境語句的表徵,並且另一級的 LSTM 把語句級表徵納入一個語境向量從而表徵整個對話歷史。(1) 但是該語境向量能捕捉到多少語境信息、以及該分級注意力模型能分離出多少有效信息並不好說。原因有兩個:當前神經網絡模型能力的欠缺,其中單一的語境信息沒有足夠能力編碼所有語境信息。或者 (2) 模型無法弄明白那句之前說過話相比其他更重要。
解決這些問題對於實際應用極其重要,比如用於客服聊天機器人開發。考慮一下包裹郵寄跟蹤的問題,其中聊天機器人需要在整個對話中記住一些重要信息,比如一個跟蹤號碼。信息提取方法(或者從對話歷史中提取重要實體的時隙填充策略)與基於表徵的神經模型的結合將有潛力解決這一問題。直觀講,對話歷史中只有非常少的關鍵詞在聊天機器人要講什麼上有非常大的指導意義。基於關鍵詞的信息提取模型首先提取這些關鍵詞,接着將其整合進語境神經模型之中,從而爲較大歷史語境中的信息利用提供更多靈活性。
邏輯學與語用學
考慮以下兩個正在進行的對話語境:
A:你要去參加聚會嗎?B:我明天有考試。從這一語境中,我們知道說話者 B 由於要準備即將到來的考試而無法參加聚會,由此後面的對話才順理成章。這需要一系列的推理步驟,即,明天有一個考試 ->不得不準備這一考試->時間被佔用->無法參加這次聚會。對人來講這直截了當,但是對當前的機器學習來講卻異常困難,尤其是在開放域中:手動標註所有的推理鏈是不切實際的。因此我們需要一個邏輯演繹模型,從大量訓練數據中自動學習這些隱含的推理鏈,並整合進對話生成之中。
背景與先驗知識
人類對話通常發生在特定語境或背景之中。它可以小到對話發生的具體位置(比如一個咖啡廳或者一個劇院)或者大到發生在戰爭或和平時期。背景對會話的展開有巨大影響。語境同樣也包括用戶信息、個人特徵,甚或說話人對對方的整體感覺。例如對方是否負責任或誠實。處理背景問題的挑戰來自兩個方面:(1) 在訓練數據上,收集對話發生於其中的背景的綜合信息比較困難。正如在先前章節所討論的,最大規模的可用數據集來自社交媒體推特、在線論壇 reddit 或者電影劇本等,以上通常缺乏關於背景的詳細描述,比如蒐集推特中參與討論的說話者的個人角色信息就是不可能的。
你也許會想到第 4 章節的個人角色模型,它基於先前生成的對話構建說話者信息/人物簡介。但是隻使用數百或數千的對話表明,僅僅通過用戶發表在推特上的內容還不足以瞭解他們。(2) 一個特定語境對其中對話的暗示需要大量的先驗常識。當人類對話時,這些常識很少被提及或描述,因爲對話參與者認爲這是理所當然。這意味着即使我們有了關於對話的具體語境信息,也無法清楚知道爲什麼該對話會發生在該語境中,因爲說話者忽略掉了大量常識信息。這對基於模仿的機器學習系統(比如 SEQ2SEQ 模型)帶來了巨大挑戰,因爲這樣的模型只是通過訓練集一味模仿而不知其原因並不是理解人類交流的最優路徑。
我希望該論文在對話理解與生成的研究上有所貢獻,推動解決上述問題的研究進展。