近日,針對泛化能力強大的深度神經網絡(DNN)無法解釋其具體決策的問題,深度學習殿堂級人物 Geoffrey Hinton 等人發表 arXiv 論文提出「軟決策樹」(Soft Decision Tree)。相較於從訓練數據中直接學習的決策樹,軟決策樹的泛化能力更強;並且通過層級決策模型把 DNN 所習得的知識表達出來,具體決策解釋容易很多。這最終緩解了泛化能力與可解釋性之間的張力。
深度神經網絡優秀的泛化能力依賴於其隱藏層中對分佈式表徵的使用 [LeCun et al., 2015],但是這些表徵難以理解。對於第一個隱藏層我們明白是什麼激活了單元,對於最後一個隱藏層我們也明白激活一個單元產生的影響;但是對於其他隱藏層來說,理解有意義變量(比如輸入和輸出變量)的特徵激活的原因和影響就困難重重。由於其邊際效應取決於同一層其他單元的影響,使得獨立地理解任何特定的特徵激活變得舉步維艱。
相比之下,很容易解釋決策樹是如何做出特定分類的,因爲它依賴於一個相對短的決策序列,直接基於輸入數據做出每個決策。但是決策樹並不像深度神經網絡一樣可以很好地泛化。與神經網絡中的隱藏單元不同,決策樹較低級別的典型節點僅被一小部分訓練數據所使用,所以決策樹的較低部分傾向於過擬合,除非相對於樹的深度,訓練集是指數量級的規模。
在這篇論文中,我們提出了一種新的方法,以緩解泛化能力和可解釋性之間的張力。與其嘗試理解深度神經網絡如何決策,我們使用深度神經網絡去訓練一個決策樹以模仿神經網絡發現的「輸入-輸出「函數,但是是以一種完全不同的方式工作。如果存在大量的無標籤數據,該神經網絡可以創建一個大得多的標記數據集去訓練一個決策樹,從而克服決策樹的統計低效問題。即使無標籤數據是不可用的,或許可以使用生成式建模中的最新研究進展(Goodfellow et al., 2014, Kingma and Welling, 2013)以從一個類似於數據分佈的分佈中生成合成無標籤數據。即使沒有使用無標籤數據,仍然有可能通過使用一種稱爲蒸餾法(distillation,Hinton et al., 2015, Buciluˇa et al., 2006)的技術和一種執行軟決策的決策樹,將神經網絡的泛化能力遷移到決策樹上。
在測試過程中,我們使用決策樹作爲我們的模型。該模型的性能可能會略微低於神經網絡,但速度快得多,並且該模型的決策是可解釋的。
爲了簡單起見,我們從一類特殊的決策樹開始討論,使深度神經網絡的知識能更容易地被提取/蒸餾然後導入決策樹中。
2 專家的層次化混合
我們使用小批量梯度下降法訓練軟二元決策樹,其中每一個內部節點(inner node)i 有一個學習到的過濾器 w_i 和一個偏置 b_i,每一個葉節點(leaf node)l 有一個學習到的分佈 Q_l。在每一個內部節點處,選擇最右邊的分支的概率爲:
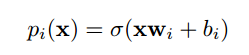
其中 x 是模型的輸入,σ是 sigmoid logistic 函數。
這個模型是專家的層次化混合(hierarchical mixture of experts,Jordan and Jacobs, 1994),但每個專家實際上都是一個「偏執者(bigot)」,即在訓練之後,無論輸入是什麼都會生成相同的分佈。該模型學習到了一個過濾器的分層體系,用於爲每個樣本分配一個特定的專家以及相關的特定路徑概率,並且每個偏執者都學習到了一個簡單的、靜態的關於所有可能輸出類 k 的分佈。
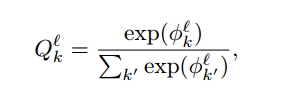
其中 Q^l. 表示在第 l 葉的概率分佈,Φ^l. 是第 l 葉的學習參數。
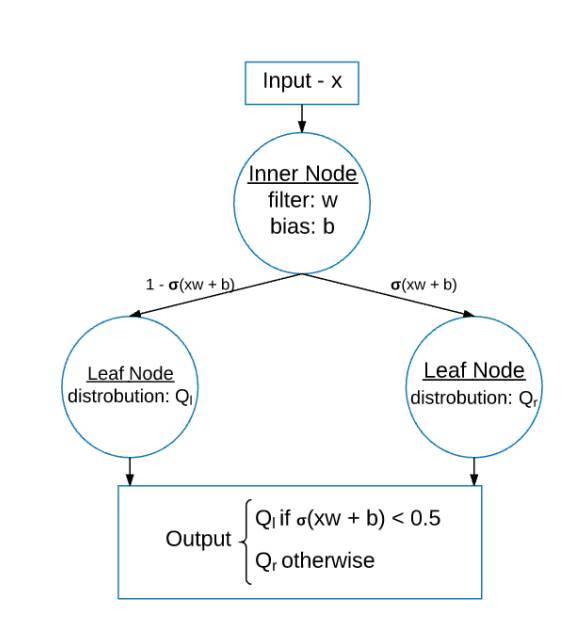
圖 1:這個示意圖展示了一個有單個內部節點和兩個葉節點的軟二元決策樹。
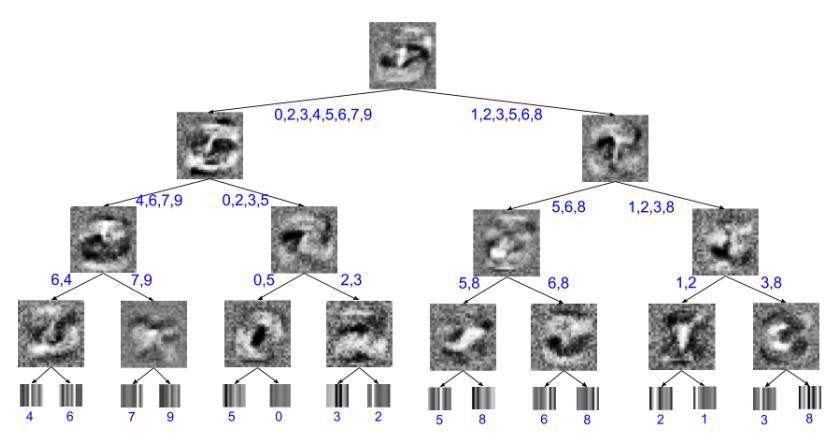
圖 2:一個在 MNIST 上訓練的 4 層軟決策樹的可視化。
內部節點中的圖像是學習到的過濾器,葉節點中的圖像是學習到的類概率分佈的可視化。圖中標註了每一葉的最終的最大可能分類,以及每一個邊的可能分類。以最右邊的內部節點爲例,可以看到在決策樹的當前層次下可能的分類只有 3 和 8,因此該學習到的卷積核只需要簡單地學習區分這兩個數字就可以了。

圖 3:在 Connect4 數據集上訓練的軟決策樹前 2 層的可視化示例。
通過檢查已學習的過濾器,我們可以看到遊戲可以分爲兩種截然不同的子類型:一種是玩家將棋子放在棋盤的邊緣,另一種是玩家將棋子放在棋盤中央。
論文:Distilling a Neural Network Into a Soft Decision Tree

論文地址:https://arxiv.org/abs/1711.09784
摘要:深度神經網絡已經在分類任務上證明了其有效性;當輸入數據是高維度,輸入與輸出之間的關係很複雜,已標註的訓練實例數量較大時,深度神經網絡的表現更爲突出。由於它們對分佈式層級表徵的依賴,很難解釋爲什麼一個已學習的網絡能夠在特定的測試中做出特定的分類決策。如果我們能夠獲取神經網絡習得的知識,並藉助依賴於層級決策的模型表達出來,那麼解釋一個特定的決策將會容易很多。我們描述了一種使用已訓練的神經網絡創建軟決策樹的方法,它比直接從訓練數據中學習的決策樹有着更優的泛化能力。