結果喜人,由於新一代的英偉達 GPU 使用了 12 納米制程的圖靈架構和 Tensor Core,在深度學習圖像識別的訓練上至少能比同級上代產品提升 30% 的性能,如果是半精度訓練的話最多能到兩倍。看起來,如果用來做深度學習訓練的話,目前性價比最高的是 RTX 2080Ti 顯卡(除非你必須要 11G 以上的顯存)。
Lambda 藉助 TensorFlow 對以下 GPU 進行了測試:
Titan RTX
RTX 2080 Ti
Tesla V100 (32 GB)
GTX 1080 Ti
Titan Xp
Titan V
注意,作者只對單 GPU 對常見神經網絡的訓練速度進行了測試。
結果總結
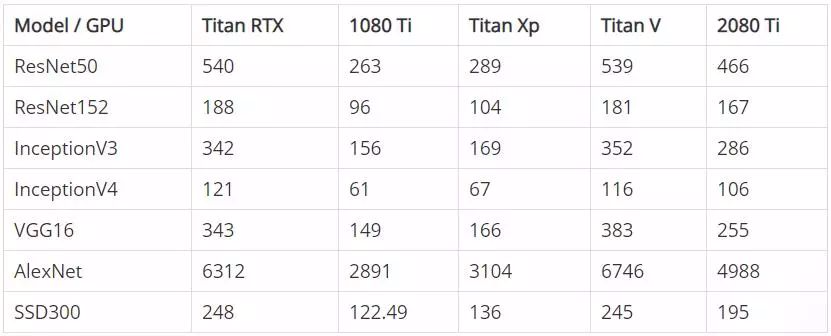
我們測試了在訓練神經網絡 ResNet50、ResNet152、Inception3、Inception4、VGG16、AlexNet 和 SSD 時,以下每個 GPU 每秒處理的圖像數量。
在 FP 32 單精度訓練上,Titan RTX 平均:
比 RTX 2080Ti 快 8%;
比 GTX 1080Ti 快 46.8%;
比 Titan Xp 快 31.4%;
比 Titan V 快 4%;
比 Tesla V100(32 GB)慢 13.7%。
在 FP 16 半精度訓練上,Titan RTX 平均:
比 RTX 2080 Ti 快 21.4%;
比 GTX 1080 Ti 快 209.7%;
比 Titan Xp 快 192.1%;
比 Titan V 慢 1.6%;t
和 v100(32 GB)的對比還有待調整。
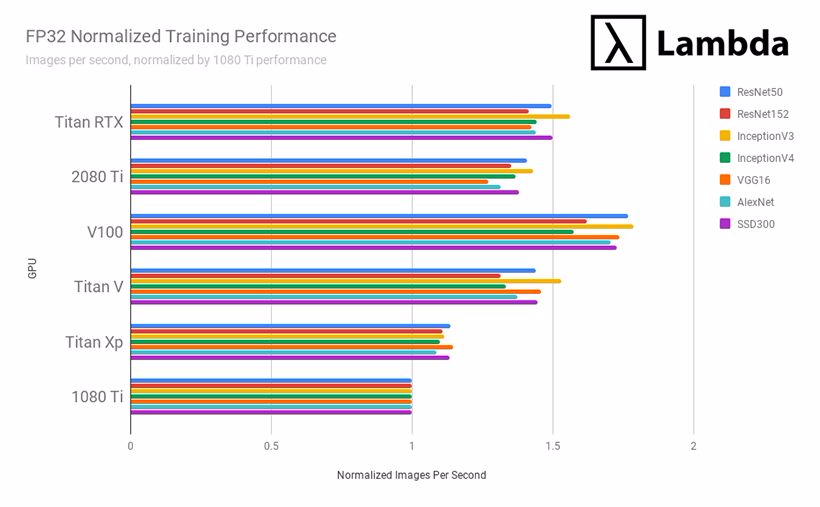
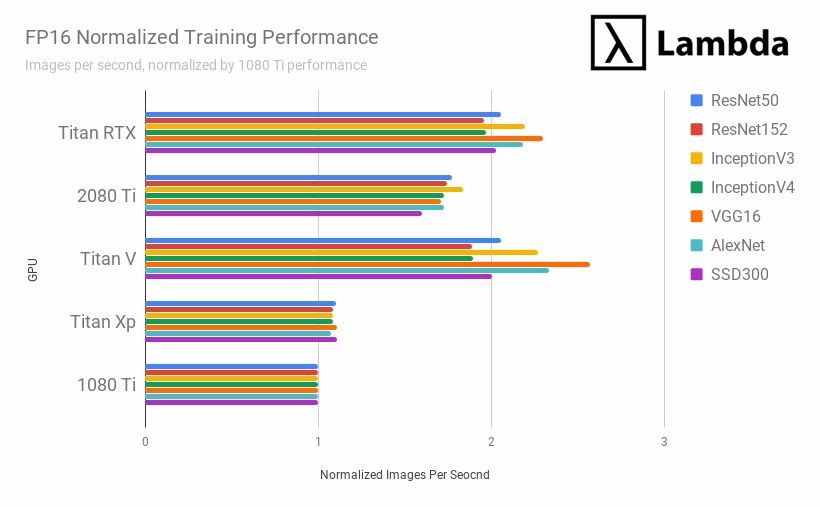
結論:2019 年最合適深度學習/機器學習的 GPU 是?
如果 11 GB 的 GPU 內存足夠滿足你的訓練需求(能滿足大部分人),RTX 2080 Ti 是最適合做機器學習/深度學習的 GPU。因爲相比於 Titan RTX、Tesla V100、Titan V、GTX 1080 Ti 和 Titan Xp,2080Ti 有最高的性價比。
如果 11GB 的 GPU 內存滿足不了你的訓練需求,Titan RTX 是最適合做機器學習/深度學習的 GPU。但是,在下結論之前,試試在半精度(16 bit) 上的訓練速度。損失一定的訓練準確率,能有效地把 GPU 內存翻倍。如果在 FP16 半精度和 11GB 上的訓練還是不夠,那就選擇 Titan RTX,否則就選擇 RTX 2080 Ti。在半精度上,Titan RTX 能提供 48GB 的 GPU 內存。
如果不在乎價錢且需要用到 GPU 的所有內存,或者如果產品開發時間對你很重要,Tesla V100 是最適合做機器學習/深度學習的 GPU。
方法
所有模型都是在一個綜合數據集上訓練的,從而把 GPU 的表現與 CPU 預處理的表現隔離開,且降低僞 I/O 瓶頸的影響。
作者對每個 GPU/模型對進行了 10 組訓練實驗,然後取平均值。
每個 GPU 的「歸一化訓練表現」均爲在特定模型上每秒處理圖像數量的表現與 1080Ti 在同樣模型上每秒處理圖像數量表現的比值。
Titan RTX、2080Ti、Titan V 和 V100 基準測試用到了 Tensor Cores。
硬件平臺
測試中採用的硬件平臺爲 Lambda Dual 雙 Titan RTX 桌面平臺,包含英特爾 Core i9-7920X 處理器,64G 內存,看起來已經是最強臺式電腦配置了。在測試時,Lambda 僅更換 GPU 配置。
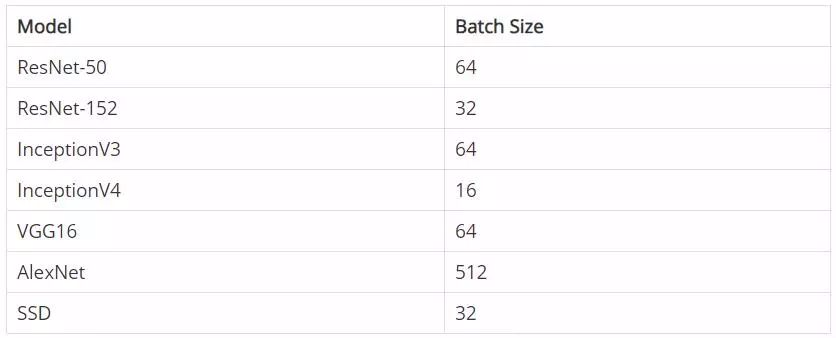
Batch-sizes
系統軟件環境
Ubuntu 18.04
TensorFlow: v1.11.0
CUDA: 10.0.130
cuDNN: 7.4.1
NVIDIA Driver: 415.25
初始結果
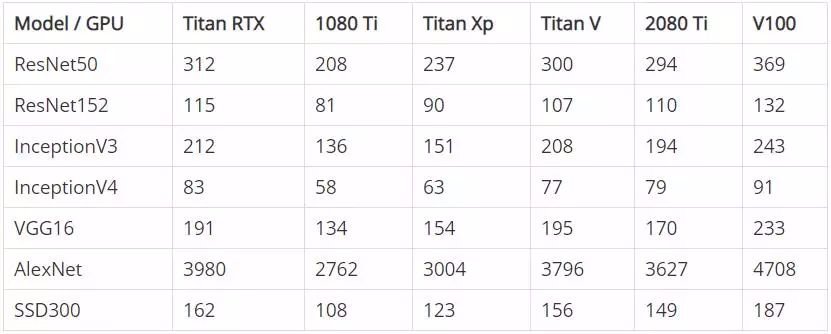
下表顯示了在 FP32 模式(單精度)和 FP16 模式(半精度)下訓練時每個 GPU 的初始性能。注意,數字表示的是每秒處理的圖片數量,對數量進行了四捨五入。
FP32 - 每秒鐘處理的圖像數量
FP16 - 每秒鐘處理的圖像數量
自己運行基準測試
目前,Lambda Lab 的 GitHub 庫中已經提供了所有基準測試的代碼,你可以測試自己的機器了。
第一步:克隆基準測試的 Repo
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive第二步:運行基準測試
輸入正確的 gpu_index (default 0) 和 num_iterations (default 10)
cd lambda-tensorflow-benchmark./benchmark.sh gpu_index num_iterations第三步:報告結果
選擇
- .logs(generated by benchmark.sh) 目錄; 使用同樣的 num_iterations 進行跑分和記錄。
./report.sh
-
.logs num_iterations
原文鏈接:https://lambdalabs.com/blog/titan-rtx-tensorflow-benchmarks/