 ...
...
長短期記憶網絡,通常稱為「LSTM」(Long Short Term Memory network,由Schmidhuber和Hochreiterfa提出)。它已經被廣泛用於語音識別,語言建模,情感分析和文本預測。在深入研究LSTM之前,我們首先應該了解LSTM的要求,它可以用實際使用遞歸神經網絡(RNN)的缺點來解釋。所以,我們要從RNN講起。
遞歸神經網絡(RNN)
對於人類來說,當我們看電影時,我們在理解任何事件時不會每次都要從頭開始思考。我們依靠電影中最近的經歷並向他們學習。但是,傳統的神經網絡無法從之前的事件中學習,因為信息不會從一個時間步傳遞到另一個時間步。而RNN從前一步學習信息。
例如,電影中如果有某人在籃球場上的場景。我們將在未來的框架中即興創造籃球運動:一個跑或者跳的人的形象可能被貼上「打籃球」的標籤,而一個坐著看的人的形象可能被打上「觀眾」的標籤。
 ...
...
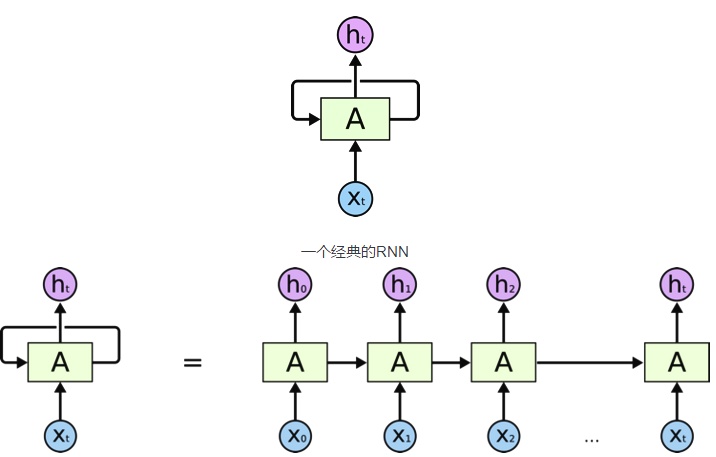
一個典型的RNN如上圖所示 – 其中X(t)代表輸入,h(t)是輸出,而A代表從循環中的前一步獲得信息的神經網絡。一個單元的輸出進入下一個單元並且傳遞信息。
但是,有時我們並不需要我們的網絡僅僅通過過去的信息來學習。假設我們想要預測文中的空白字「大衛,一個36歲,住在舊金山的老男人。他有一個女性朋友瑪麗亞。瑪麗亞在紐約一家著名的餐廳當廚師,最近他在學校的校友會上碰面。瑪麗亞告訴他,她總是對_________充滿熱情。」在這裡,我們希望我們的網絡從依賴「廚師」中學習以預測空白詞為「烹飪」。我們想要預測的東西和我們想要它去得到預測的位置之間的間隙,被稱為長期依賴。我們假設,任何大於三個單詞的東西都屬於長期依賴。可惜,RNN在這種情況下無法發揮作用。
為什麼RNN在這裡不起作用
在RNN訓練期間,信息不斷地循環往復,神經網絡模型權重的更新非常大。因為在更新過程中累積了錯誤梯度,會導致網絡不穩定。極端情況下,權重的值可能變得大到溢出並導致NaN值。爆炸通過擁有大於1的值的網絡層反覆累積梯度導致指數增長產生,如果值小於1就會出現消失。
長短期記憶網絡
RNN的上述缺點促使科學家開發了一種新的RNN模型變體,名為長短期記憶網絡(Long Short Term Memory)。由於LSTM使用門來控制記憶過程,它可以解決這個問題。
下面讓我們了解一下LSTM的架構,並將其與RNN的架構進行比較:
 ...
...
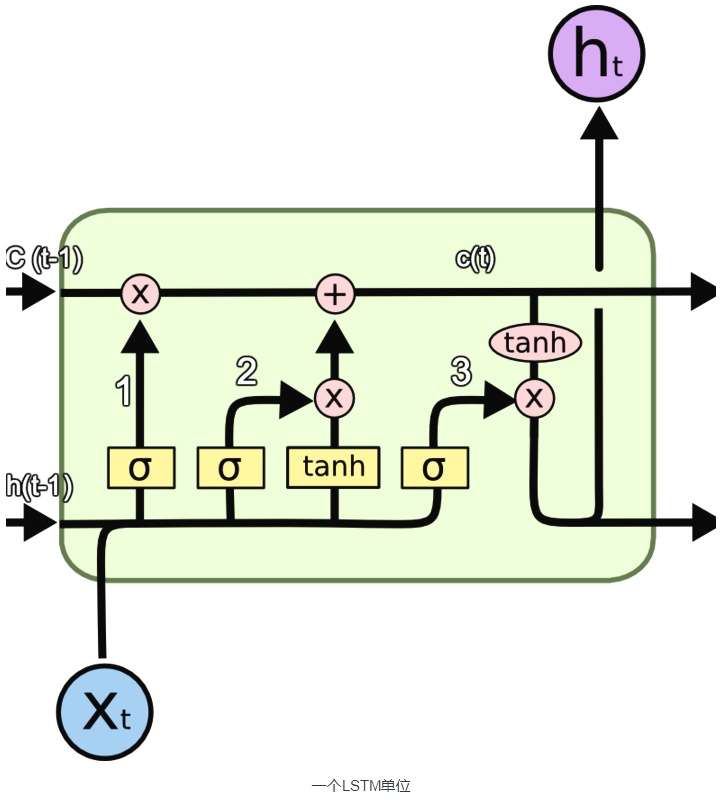
這裡使用的符號具有以下含義:
a)X:縮放的信息
b)+:添加的信息
c)σ:Sigmoid層
d)tanh:tanh層
e)h(t-1):上一個LSTM單元的輸出
f)c(t-1):上一個LSTM單元的記憶
g)X(t):輸入
h)c(t):最新的記憶
i)h(t):輸出
為什麼使用tanh?
為了克服梯度消失問題,我們需要一個二階導數在趨近零點之前能維持很長距離的函數。tanh是具有這種屬性的合適的函數。
為什麼要使用Sigmoid?
由於Sigmoid函數可以輸出0或1,它可以用來決定忘記或記住信息。
信息通過很多這樣的LSTM單元。圖中標記的LSTM單元有三個主要部分:
- LSTM有一個特殊的架構,它可以讓它忘記不必要的信息。Sigmoid層取得輸入X(t)和h(t-1),並決定從舊輸出中刪除哪些部分(通過輸出0實現)。在我們的例子中,當輸入是「他有一個女性朋友瑪麗亞」時,「大衛」的性別可以被遺忘,因為主題已經變成了瑪麗亞。這個門被稱為遺忘門f(t)。這個門的輸出是f(t)* c(t-1)。
- 下一步是決定並存儲記憶單元新輸入X(t)的信息。Sigmoid層決定應該更新或忽略哪些新信息。tanh層根據新的輸入創建所有可能的值的向量。將它們相乘以更新這個新的記憶單元。然後將這個新的記憶添加到舊記憶c(t-1)中,以給出c(t)。在我們的例子中,對於新的輸入,他有一個女性朋友瑪麗亞,瑪麗亞的性別將被更新。當輸入的信息是,「瑪麗亞在紐約一家著名的餐館當廚師,最近他們在學校的校友會上碰面。」時,像「著名」、「校友會」這樣的詞可以忽略,像「廚師」、「餐廳」和「紐約」這樣的詞將被更新。
- 最後,我們需要決定我們要輸出的內容。Sigmoid層決定我們要輸出的記憶單元的哪些部分。然後,我們把記憶單元通過tanh生成所有可能的值乘以Sigmoid門的輸出,以便我們只輸出我們決定的部分。在我們的例子中,我們想要預測空白的單詞,我們的模型知道它是一個與它記憶中的「廚師」相關的名詞,它可以很容易的回答為「烹飪」。我們的模型沒有從直接依賴中學習這個答案,而是從長期依賴中學習它。
我們剛剛看到經典RNN和LSTM的架構存在很大差異。在LSTM中,我們的模型學習要在長期記憶中存儲哪些信息以及要忽略哪些信息。
使用LSTM快速實現情感分析
在這裡,我使用基於keras的LSTM對Yelp開放數據集的評論數據進行情感分析。
下面是我的數據集。
 ...
...
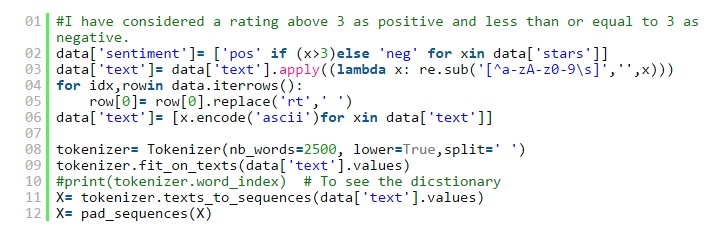
我使用Tokenizer對文本進行了矢量化處理,並在限制tokenizer僅使用最常見的2500個單詞後將其轉換為整數序列。我使用pad_sequences將序列轉換為二維numpy數組。
 ...
...
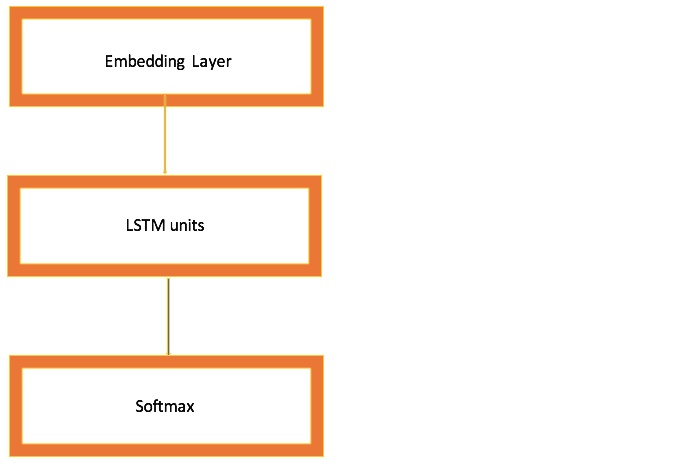
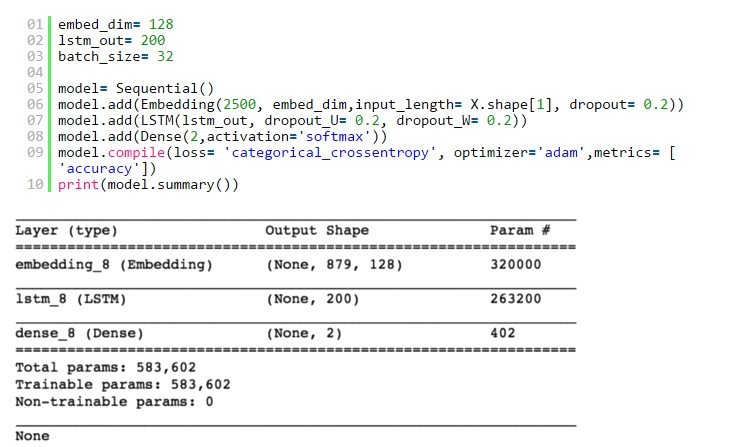
然後,我構建自己的LSTM網絡。幾個超參數如下:
- embed_dim:嵌入層將輸入序列編碼為維度為embed_dim的密集向量序列。
- lstm_out:LSTM將矢量序列轉換為大小為lstm_out的單個矢量,其中包含有關整個序列的信息。
其他超參數,如dropout,batch_size與CNN中類似。
我使用softmax作為激活函數。
 ...
...  ...
...
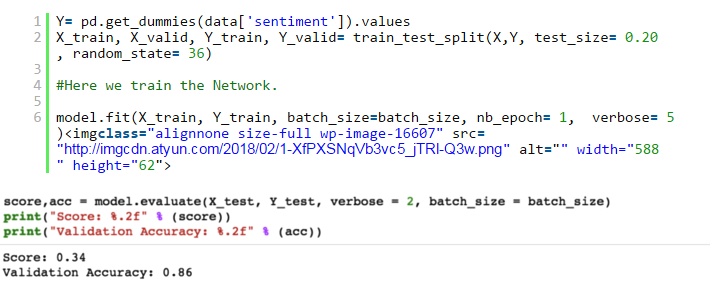
現在,我將我的模型放在訓練集上,並檢查驗證集的準確性。
 ...
...
在一個包含所有業務的小數據集上運行時,我在僅僅疊代一次就獲得了86%的驗證精度。
未來的改進方向:
- 我們可以篩選餐館等特定業務,然後使用LSTM進行情感分析。
- 我們可以使用具有更大的數據集進行更多次的疊代來提高準確性。
- 可以使用更多隱藏的密集層來提高準確性。也可以調整其他超參數。
結論
當我們希望我們的模型從長期依賴中學習時,LSTM要強於其他模型。LSTM遺忘,記憶和更新信息的能力使其比經典的RNN更為先進。