
最近在 Kaggle 上有一場關於網絡流量預測的比賽落下帷幕,作爲領域裏最具挑戰性的問題之一,這場比賽得到了廣泛關注。比賽的目標是預測 14 萬多篇維基百科的未來網絡流量,分兩個階段進行,首先是訓練階段,此階段的結果是基於歷史數據的驗證集結果,接下來的階段則是真正的預測階段,對未來網絡流量的預測。
來自莫斯科的 Arthur Suilin 在這場比賽中奪冠,他在 github 上分享了自己的模型,我們把 Arthur Suilin 的經驗分享編譯如下。
核心思路
簡單來說,Arthur Suilin 採用了 seq2seq 模型,使用一些調優方法在數據體現年份和四季帶來的波動。模型的主要依靠的信息源有兩類:局部特徵和全局特徵。
1. 局部特徵
自迴歸模型 —— 當發現一種趨勢出現時,期望它能持續出現
滑動平均模型 —— 當發現流量高峯出現時,隨後會出現持續性地衰退
季節性模型 —— 當發現某些假日的流量高時,期望以後的假日的流量都會高
2. 全局特徵
注意看下面的自相關圖,會發現按年、按月都有很強的自相關性。
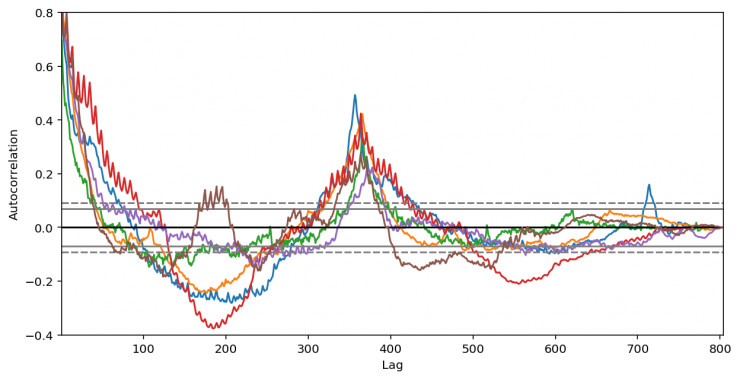
一個好的模型應該完美結合全局特徵和局部特徵。
Arthur 解釋了他爲什麼採用 RNN seq2seq 模型來預測網絡流量:
ARIMA 模型已經發展成熟,而 RNN 是在 ARIMA 模型基礎上延深的算法,更爲靈活、可表達性強。
RNN 屬於非參數算法,簡化了模型的學習過程。
RNN 模型能輕易識別一些異常特徵(數字類的或分類的,時間相關的或序列相關的)。
Seq2seq 算法擅長處理時序問題:基於過去值和過去值的預測值來預測未來值。使用過去值的預測值能使模型更加穩定,這也是 Seq2seq 模型較爲謹慎的地方。訓練過程中每一步的錯誤都會累積,當某一步出現了極端錯誤,可能就會毀壞其後面所有時步的預測質量。
深度學習算法已經被過度使用。
特徵工程
在這一步,Arthur 選擇了簡化處理,因爲 RNN 本身在特徵提取上已足夠強大,以下爲模型提取的特徵:
pageviews,由於這次比賽是基於網頁的流量預測,在此使用了頁面點擊率(hits),原值通過lop1p() 轉換。
agent,county,site – 這些特徵都是從頁面 url 和 one-hot 編碼中提取的。
day of week – 用於學習按周的季節性
year-to-year autocorrelation, quarter-to-quarter autocorrelation,用於學習按年和按季的季節性長度
page popularity,高流量和低流量頁面有不同的流量變化模式,這一特徵用於學習流量規模,流量規模信息在 pageviews 特徵中丟失了,因爲 pageviews 序列正則化成均值爲零、單位方差。
lagged pageviews,隨後會解釋這一特徵
特徵預處理
所有特徵(包括 one-hot 編碼的特徵) 都正則化成均值爲零、單位方差的數據,每一個 pageviews 序列都是單獨正則化的。
與時間無關的特徵(autocorrelations,country 等)都被「拉伸」到與時間序列相同的長度,也就是說每天都會同樣地重複。
模型從原始時間序列上隨機抽取固定長度的樣本進行訓練。例如,如果原始時間序列的長度爲 600 天,那麼把訓練樣本的長度設爲200天,就可以有400種不同的起始點。
這種採樣方法相當於一種有效的數據增強機制,在每一步訓練中,訓練程序都會隨機選擇時序的開始點,相當於生成了無限長的、幾乎不重複的訓練數據。
模型的核心
模型有兩個主要部分:encoder 和decoder
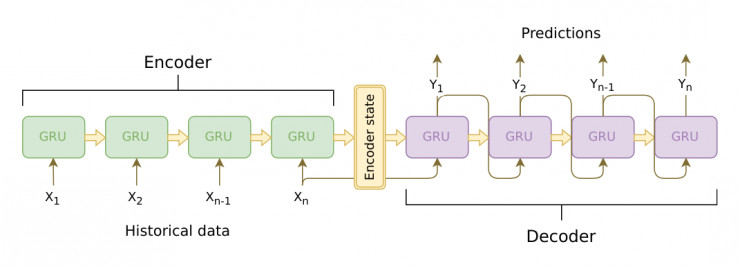
在這裏,encoder 是一個 cuDNN GRU。 cuDNN 比傳統的 Tensorflow RNNCell 要快 5 到 10 倍,但 cuDNN 不容易上手,而且相關文檔也不全面。
decoder 是 一個 TF GRUBlockCell,包含在 tf.while_loop() 函數裏。循環函數裏的代碼獲取過去步的預測值,並將其作爲當前步的輸入。
處理長時序
LSTM/GRU 擅長處理最多 100-300 個項目的短序列。雖然它也能在更長的序列上工作,但它會逐漸忘記以前的信息。本次比賽中的時間序列長達 700 天,所以 Arthur 使用了一些其他的方法來增強 GRU 的記憶力。
作者選擇的第一種方法是注意力機制 ( attention )。 Attention 可以記住「久遠」的信息,針對這次比賽的任務,最簡單有效的 attention 方法是固定權重的滑動窗口 attention(fixed-weight sliding-window attention)。對於季節性長的時間序列, 有兩個數據點是非常重要的:year ago、 quarter ago。
作者從 current_day - 365 和 current_day - 90 時間點取 encoder 的輸出, 經過一層 FC 層來降維,然後將結果傳送到 decoder 作爲輸入。這種簡單的方法能極大地降低預測錯誤。
接下來爲了減少噪音數據和不均勻間隔(閏年、月份長度不同等)的影響,模型使用這些重要數據點和其鄰近幾個數據點的平均值作爲這些數據點的值。
attn_365 = 0.25 * day_364 + 0.5 * day_365 + 0.25 * day_366
0.25, 0.5, 0.25 都是在一維的卷積內核上(長度爲3),想要讀出過去的重要數據點,則需要應用更大的內核。
最終形成的 attention 機制有些奇怪,如同提取了每一個時間序列的「指紋」(由小型卷積層形成),這些「指紋」決定了哪一個數據點會被選入更大的卷積內核並生成權重。這個大的卷積內核會應用到 decoder 的輸出,爲每一個待預測的天生成 attention 特徵。這個模型可以在源碼中找到。
注:模型沒有使用傳統的 attention 機制(Bahdanau or Luong attention),因爲傳統 attention 在每一步都需要從頭計算,並且用上所有歷史數據點。這對於這次比賽的數據 —— 長達 2 年的時間序列來說不太適用,會耗費很長時間。所以模型採用了另一種 attention 方法,對所有的數據點應用同一層卷積層,在預測時使用相同的 attention 權重,這樣的模型計算起來更快。
attention 機制太過複雜,Arthur 表示也嘗試過完全移除 attention,只留下過去的重要數據點,如年,半年,季前等數據點,把這些數據點作爲新增的特徵輸入到 encoder 和 decoder 裏。這種方法效果顯著,甚至略爲超過了目前使用 attention 的預測質量。Arthur 公佈的最好成績模型,只使用了滯後數據點作爲特徵,而沒有使用 attention 。
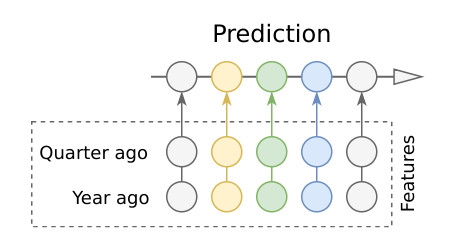
滯後的數據點還有一些好處: 模型可以使用更短的 encoder,不用擔心在訓練過程會丟失過去的信息。因爲這些信息已經完全包含在特徵裏了。即使是需要 60 - 90 天時間序列的 encoder 還是表現的不錯 , 而之前的模型需要 300 - 400 天的時間序列。encoder 更短意味着訓練更快,更少的信息丟失。
損失和正則化
本次比賽用 SMAPE 來評估結果,在模型中,由於零值點的鄰近數據點不穩定,SMAPE 無法直接使用。
Arthur 使用了平滑過的可微 SMAPE 變量,在真實的數據上表現良好:

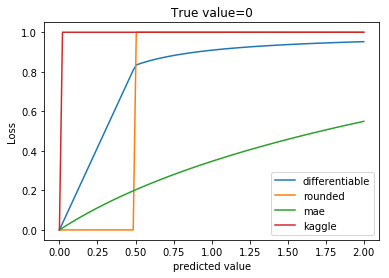
其他可選的方案: MAE ,使用 MAE 得到的結果每一處都很平滑,非常接近 SMAPE 的訓練目標。
最後的預測結果四捨五入爲最接近的整數值,所有負值記爲 0。
訓練和驗證
模型使用了 COCOB 優化器結合梯度裁剪,這個優化器方法可參見論文《Training Deep Networks without Learning Rates Through Coin Betting》。COCOB 嘗試在每一步預測最優學習率,所以在訓練過程中不需要調節學習率。它比傳統基於動量的優化器要收斂的快很多,尤其在第一個 epoch,這節省了很多時間。
劃分訓練集和驗證集的方法有兩種:
1. Walk-forward split
這種方法事實上不是真的在劃分數據,數據集的全集同時作爲訓練集和驗證集,但驗證集用了不同的時間表。相比訓練集的時間表,驗證集的時間表被調前了一個預測間隔期。
2. Side-by-side split
這是一種主流的劃分方式,將數據集切分爲獨立的不同子集,一部分完全用於訓練,另一部分完全用於驗證。
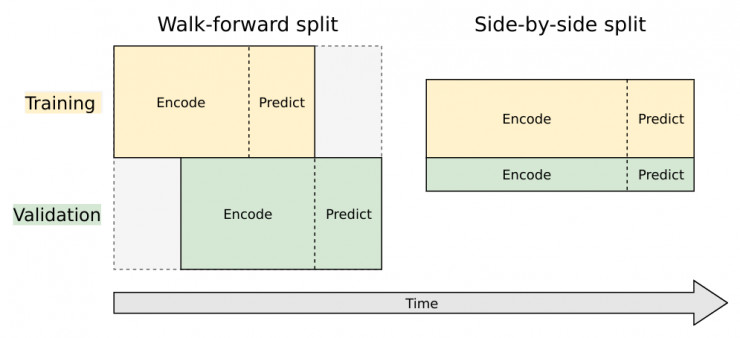
這兩種方法在模型中都有嘗試過。
Walk-forward 的結果更可觀,畢竟它比較符合比賽目標:用歷史值預測未來值。但這種切分方法有其弊端,因爲它需要在時間序列末端使用完全只用作預測的數據點,這樣在時間序列上訓練的數據點和預測的數據點間隔較長,想要準確預測未來的數據就會變得困難。
舉個例子,假如我們有 300 天的歷史數據,想要預測接下來的 100 天。如果我們選擇 Walk-forward 劃分方法,我們會使用第前 100 天作爲訓練數據,接下來 100 天作爲訓練過程中的預測數據(運行 decoder,計算損失),接下來 100 天的數據用作驗證集,最後 100 天用作預測未來的值。所以我們實際上用了 1/3 的數據點在訓練,在最後一次訓練數據點和第一次預測數據點之間有 200 天的間隔。這個間隔太大了,所以一旦我們離開訓練的場景,預測質量會成指數型下降。 如果只有 100 天的間隔,預測質量會有顯著提升。
Side-by-side split 在末端序列上不會單獨耗用數據點作爲預測的數據集,這一點很好,但模型在驗證集上的性能就會和訓練集的性能有很強的關聯性,卻與未來要預測的真實數據沒有任何相關性,換一句話說,這樣劃分數據沒有實質性作用,只是重複了在訓練集上觀察到的模型損失。
簡而言之,使用 walk-forward split 劃分的驗證集只是用來調優參數,最後的預測模型必然是在與訓練集和驗證集完全無相關的數據下運行的。
減少模型方差
由於噪音數據的存在,模型不可避免有很大的方差。事實上RNN能在這些噪音數據中完成學習過程已經很不錯了。
不同 seed 下訓練的模型性能也會不一樣,某些 seed 下的模型性能誤差很大。在訓練過程中,這種性能的波動是一直存在的,完全憑運氣贏得比賽是不行的,所以必須有一些措施來減少方差。
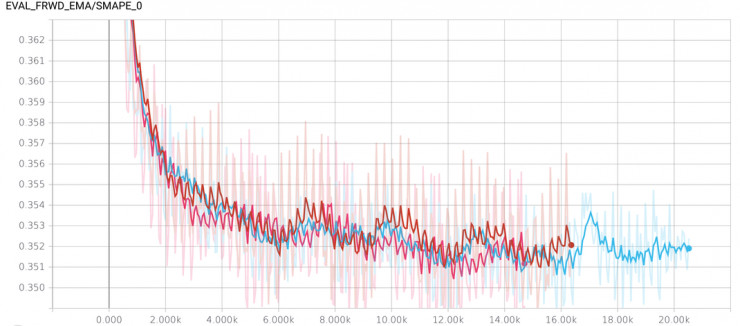
1. 我們不清楚模型訓練到哪一步是最適合用於預測未來值的(畢竟基於當前數據的驗證集和未來數據的關聯性很弱),所以不能過早停止訓練。但是防止模型過擬合的一個大概範圍可以推測,Arthur 把這個範圍邊界設爲 10500..11500, 這樣節省了 10 個 checkpoints。
2. Arthur 在不同的 seed 上訓練 了3 種模型,每一個模型都減少了 checkpoint ,最後總共有 30 個 checkpoints 。
3. 提供模型性能、減少方差的典型方法是 SGD averaging(ASGD),這種方法非常簡單,在 Tensorlow 上用起來也很順手。ASGD 要求在訓練過程中網絡權重使用滑動平均值。
以上三種方法結合起來效果很好,模型的 SMAPE 誤差幾乎快趕上排行榜上基於歷史數據的驗證集下的 SMAPE 誤差值了。
理論上,使用前兩種方法作爲集合的學習過程就可以了,第三種方法的使用主要是爲了減少誤差。
超參數調優
很多超參數的值會影響模型性能,例如網絡層的個數和深度,激勵函數,dropout 係數,因此超參數需要調優。手動調參既無趣又耗時,我們當然希望模型能自動調優,所以模型中使用了 SMAC3 來自動調優,SMAC3 是一種參數調優的搜索算法,它有以下幾點優點:
支持條件參數 (舉一個例子,同時調節網絡層個數和每層的 dropout 個數,當只有 n_layers >1 時,第二層的 drupout 才能被調節,我們說這裏存在條件參數)
顯示處理誤差 。SMAC 在不同 seed 上爲每個模型都訓練了幾個實例,只有這些實例在同一個 seed 上訓練時纔會相互對比。一個模型如果比其他所有同等 seed 上的模型性能都好的話,證明這個模型是成功的。
另外,Arthur 表示有一點沒有達到他的期待,超參數的搜索方法並沒有找出全局最優值,因爲目前最好的幾個模型雖然參數不同,性能都相差無幾。有可能 RNN 模型的可表達性太強,所以模型的表現更加依賴於數據的質量、噪音數據所佔的比例,而不是依賴於模型本身的架構了。
如果感興趣的話,在 hparams.py 中可以找到最優的參數設置。
Via: https://github.com/Arturus/
相關文章:
Kaggle機器學習大調查:中國從業者平均25歲,博士工資最高,最常使用Python
Kaggle亞馬遜比賽冠軍專訪:利用標籤相關性來處理分類問題
乾貨:圖像比賽的通用套路有哪些?Kaggle比賽金牌團隊爲你解答