隨着深度學習模型自身的學習和表達能力的提高,越來越多的研究員已經把注意力轉向瞭如何讓 AI 和人類更好地互動。這就是一批難得多的問題了,之前也報道過 Facebook AI 研究院在基於圖像的對話系統方面的研究進展。

近期的 NIPS 2017 上,IBM AI 研究院和伊利諾伊大學厄巴納-香檳分校(UIUC)共同組成的團隊也有一篇論文被收錄爲口頭報告論文(錄取率僅爲1.2%),其中提出了一種新的監督學習算法,用來解決 AI 領域廣爲人知的場景認知(textual grounding)問題,同時撰寫了一篇博文簡單介紹了論文成果。我們把這篇博文編譯如下。
想象這樣一種情況,你想讓別人遞一件東西給你。你可能會說:「幫我拿一下你左邊那張桌子上的藍色鋼筆吧。」人和人之間就是這樣溝通的,用自然語言描述場景和目標物體。然而,想要教會人工智能系統執行這樣的指令從來都是一件非常困難的事情。AI 可能可以識別「藍色的鋼筆」以及「桌子」這樣的物體,但是如果有一張以上的桌子,就不一定知道是哪一張桌子了。這裏欠缺的就是如何教會系統把給定圖像、給定場景中的東西和輸入的文本準確地聯繫起來。AI 系統的視野裏往往會有許許多多的其它物體,而想要找的目標只是在某一個特定的小區域裏而已。
如今的智能系統已經可以搭載各種各樣的傳感器,輕鬆地通過圖像(甚至視頻)和聲音的形式捕捉周圍環境的細節信息。但是如果想要弄懂這些記錄的信息,然後基於它們跟人類進行互動的話,智能系統就需要在人類的話語和圖像之間建立聯繫。場景認知要解決的就是把文本詞組(比如語音識別引擎識別得到的話語)和圖像中的區域連接起來的問題。換句話說,對於話語中提到的每一個物體(比如「藍色的鋼筆」和「你左邊的桌子」),都要在圖像中找到包含它的區域(這樣系統就知道去那裏幫你取了)。
很容易想到,場景認知有許多可能的應用領域,上面提到的這個人和 AI 互動的例子就是一種簡單的情況。
IBM 和 UIUC 聯合開發的算法在兩個廣泛使用的數據集中都刷新了當前的最好成績:在 Flickr 30K 實體數據集上達到了 53.97% 準確率,超過此前最佳的 50.89%;然後在 ReferItGame 數據集上獲得了 34.7% 的準確率,超過此前最佳的 26.93%。算法的輸出如下圖所示。

兩位戴着插花帽子的女士正在擺pose
在 IBM 和 UIUC 的研究人員們看來,這項成果的最大意義並不僅僅在於數據集上的準確率數字的提升(當然這確實也是一項重要的指標),更重要的是所提出的方法也相當優雅。下面圖中就是所提方法的示意圖。
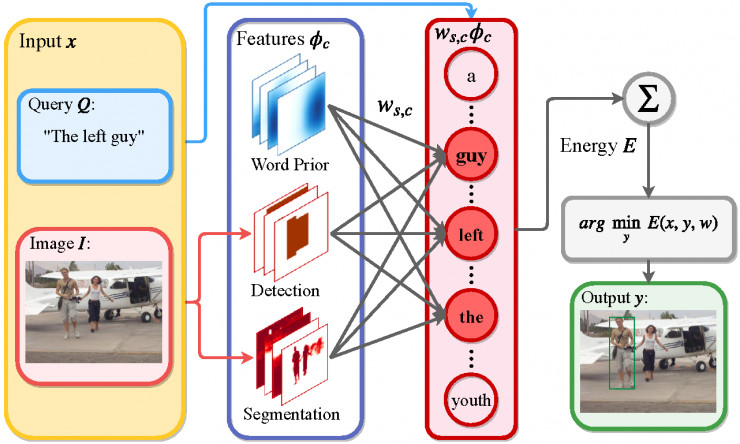
所提模型的總體結構
許多現有方法都是基於深度學習的,圖像中的特徵通過端到端的訓練方式進行提取,但這樣得到的特徵的含義就很難解釋。這篇論文中作者們提出的是一個混合型的方案,把一組顯式地提取出的特徵(文中稱作「分數表」score maps)和一個構建出的 SVM 模型結合在一起。特徵的分數表是可以拓展的,所以算法可以輕鬆地包含任何新的特徵。論文中選擇了一些容易獲得的特徵,比如從輸入問句中得到的單詞先驗知識、區域幾何偏好,以及其它一些語意分割、目標檢測、位姿估計這樣的依靠深度神經網絡得到的「圖像概念」。
在多數現有模型中,對於給定的一組候選區域,推理過程中都做的是相對簡單直接的矩陣向量相乘操作。而對於論文中的混合模型,推理過程中要求解一個最小能量問題,它會搜索所有可能的邊界框,找到最匹配程度最高的那個。
爲了能夠解出這個最小能量問題,作者們使用了一個帶有分支定界 (branch and bound) 的子窗口搜索算算法,使得這個混合模型的端到端訓練具有計算可行性(因爲訓練的時候需要多次求解最小能量問題)。作者們還對目標函數定義了一個帶有可以輕鬆算出邊界的恰當能量函數,以便高效地求解問題,並且可以去掉目前多數場景認知模型都用到的提出候選區域這個過程。
測試中,這個模型在場景認知的質量和可解釋性兩個方面都帶來了巨大的提升。可解釋性的一種體現是單詞嵌入,比如詢問語句的表徵;對於這個模型,每個嵌入元素都可以和顯式提取出的特徵分數表(或者圖像概念)產生直接的關聯。當計算兩個單詞向量的餘弦相似度的時候,這種嵌入的好處就可以得到明顯的體現,同時也說明了比較接近的語句之間在語義上也有關聯性(而且可以據此進行分組)。比如,「茶杯」、「飲料」、「咖啡」三個單詞在語義上比較接近,在單詞嵌入空間中它們的相似度也就遠高於和其它不相關的單詞之間的相似度。
研究員們未來的研究計劃包括,把圖像特徵和輸入詞句連接起來以提升可解釋性,以及把結構化信息顯式地加入到模型中任何可能的位置上(比如這項研究中就有結構化輸出)。作者們也意識到,從他們初次發表這項研究到現在,場景認知方面又有了許多新的論文、新的研究結果,所以他們也會向着「讓人類和計算機之間更好地互動」的目標繼續進行場景認知研究。
論文地址:papers.nips.cc/paper/6787/textual-grounding
via IBM Research
相關文章:
Facebook 開始新一輪實習生招募計劃,本科學歷、瞭解Python、熟悉深度學習框架……
能看圖回答問題的AI離我們還有多遠?Facebook向視覺對話進發
NIPS 2017現場:8000人蔘會,最佳論文公佈,算法壓倒深度學習 | NIPS 2017
德撲 AI 不完全信息博弈論文領銜,NIPS 2017最佳論文 3 + 1 已經揭曉