按:本文來自斯坦福大學博士生 Andrey Kurenkov 在 The Gradient 上發表的文章。
在本文中,我們將討論人工智能的一個核心領域——強化學習——的侷限性。
在這個過程中,起初我們將通過一個有趣的例子提出我們要討論的問題,然後向大家介紹一套方法引入深度學習相關的先驗知識和說明,最終得出一個重要結論。
現在讓我們進入第一部分,你將瞭解到什麼是強化學習,以及爲什麼說強化學習(或者至少說我們稱之爲「純強化學習」的版本,我們將在接下來的文章中定義「純強化學習」的概念)從根本上說是有缺陷的。這個部分可能包含一些人工智能從業者已經十分熟悉的解釋,他們可以直接跳過該部分。但是請一定要重視最近關於「非純強化學習」的研究進展,我們認爲這代表着對純強化學習的根本缺陷的改進。但是現在,讓我們一起來看看一個有趣的例子。
案例:棋盤遊戲
想象一下,你的朋友正邀請你參與一個你從未玩過的棋盤遊戲。假設在你至今爲止的歲月中,你還沒接觸過這種棋盤遊戲,也從未玩過任何類型的遊戲。你的朋友向你介紹了規則,說明了什麼是「有效移動」。但是沒有說明它們的意義是什麼,或者如何才能得分。所以,你在不能問更多的問題,也無法獲得更多的解釋的情況下開始玩這個遊戲。可想而知,一開始,你輸掉了遊戲。接着,你開始了屢戰屢敗的嘗試,一次一次玩這個遊戲,一次一次地輸掉…… 然而,幸運的是,你漸漸地在失敗中領悟到了一些有用的模式;此時,儘管你仍然會輸掉遊戲,但是並不會那麼快地被秒殺,能多掙扎一會…… 接着,你越挫越勇,在經歷了長達數週的遊戲時間後,你甚至能勉強獲勝了!
這個故事看上去有些傻,是吧?你會問:爲什麼你不直接問朋友遊戲的目標是什麼?正確的遊戲方法是什麼?然而,上面這一段的故事實際上描述瞭如今大多數強化學習方法仍舊是如何工作的。
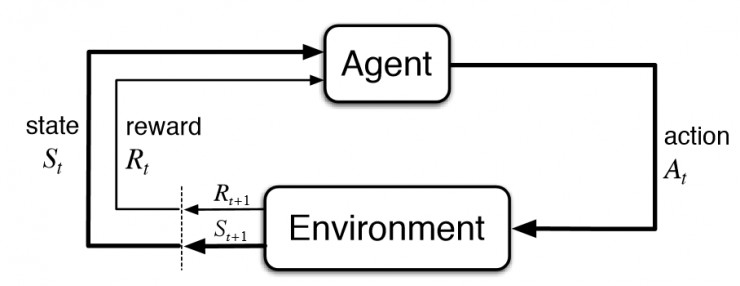
強化學習(reinforcement learning)是人工智能的子領域之一。在強化學習框架中,一個智能體(agent)與環境(environment)進行交互,從而學習到它(智能體)在任意給定的環境中的狀態(state)下需要選擇怎樣的動作(action)才能最大化它的長期獎勵(reward)。在棋盤遊戲的例子中,這意味着你(智能體)需要與棋盤(環境)進行交互,從而學習到你(智能體)在每一輪棋盤(環境)的遊戲配置(狀態)中需要採取什麼樣的移動策略(動作)才能夠最大化你最終的得分(獎勵)。
在深度學習的經典模型中,智能體一開始只知道那些動作是可以採取的。他對所處的世界中的先驗知識一無所知,只能通過與環境交互來學習這種技能,並在每次採用動作之後得到獎勵。缺乏先驗知識意味着智能體需要從頭開始學習,我們將這種從頭開始學習的方法稱爲「純強化學習」。純強化學習如今主要被用於解決雙陸棋和圍棋這樣的遊戲問題,以及機器人和其他領域的各種各樣的問題。

在棋盤遊戲的例子中,一「節」代表一個完整的遊戲過程。在這個例子以及許多的強化學習問題中,只有最終的狀態有一個非零的獎勵。
近年來,深度學習給強化學習的研究注入了新的活力,但最基本的模型並沒有發生太大的變化;畢竟,這種從頭開始學習的方法可以追溯到強化學習作爲一個研究領域被創建的伊始,並且通過其最基本的方程(貝爾曼方程)進行編碼。
那麼,一個基本的問題來了:如果純強化學習乍一看並沒有這麼大的意義,那麼設計一個基於純強化學習的人工智能模型是否合理呢?如果讓一個人通過純強化學習的方式學習一個新的棋盤遊戲是如此荒謬的話,難道我們不應該想想,這對於人工智能體來說不是一種存在缺陷的學習框架嗎?在既沒有先驗的經驗又沒有更高層次的指導的情況下,僅僅基於獎勵信號就開始學習新的技能真的有意義嗎?
先驗經驗和高層次的指導在用於形式化定義強化學習的經典的方程式中均沒有得到體現,而且無論是隱式還是顯式地改變這些方程,都可能對我們用來訓練用於所有的強化學習的人工智能算法都有很大的影響(這些算法已經遠遠超出了棋盤遊戲的範疇,從機器人技術到資源分配問題)。換句話說,這是一個很大的問題,爲了得到這個問題的答案,你需要閱讀下面兩篇文章:
1. 在第一部分(本文)中,我們首先將指出,純深度學習的主要成果並不像他們看上去那麼令人印象深刻。接着,我們將進一步說明,在純強化學習框架下不太可能實現更復雜的成果,這是因爲它對人工智能體強加了諸多限制。
2. 在第二部分中,我們將概述人工智能技術中能夠解決這種限制的不同方法(主要是元學習和零樣本學習)。最後,我們將調查到目前爲止,基於這些方法的具有里程碑意義的工作,並且總結出這項工作對強化學習和整個人工智能研究領域意味着什麼。
幾乎人人認同純強化學習是強化學習的基本形式。但他們真的應該這麼認爲嗎?
純強化學習有意義嗎?
對於這個問題,許多人下意識的反應大概是:「當然,使用純強化學習還是很有意義的——人工智能體並不是人類,所以並不需要像我們一樣學習,況且純強化學習已經被證明可以解決各種各樣複雜的問題。 」
我不同意以上觀點。根據定義,人工智能研究涉及到使機器能夠做一些目前只有人類和動物才能做到的事情。因此,將人工智能與人類智能進行比較是合適的。至於那些目前使用純強化學習解決的問題,有人給出了一些重要的忠告,但是往往被人忽視:這些問題其實往往並不像看上去那麼複雜。
也許,對於很多人來說,這種說法是非常令人驚訝的,因爲解決這些問題是目前人工智能最廣爲人知的成就。說實話,儘管這些成就確實是很偉大的,但我仍然認爲這些涉及到的問題並不想他們看上去那麼複雜。在討論爲什麼我們這麼說之前,我們不妨列舉一下這些成就,並指出爲什麼這些成就是完全配得上這種讚揚的:
1. DQN(深度 Q 學習網絡):短短5 年前,DeepMind 的一項研究項目大大提升了人們對強化學習的興趣,該項目表明,將深度學習與純強化學習和一些新的創意相結合可以解決比以往任何時候都要更加複雜的問題。
毫不誇張地說,DQN 是一種以一己之力重新激發廣大研究人員對強化學習的興趣的模型。儘管它只包含了一些相對簡單的創新,但是這些創新被證明對於使深度強化學習更加實用非常重要。

儘管看起來很簡單,但是從遊戲畫面的像素輸入中學習如何玩這個遊戲在十年前還是不可想象的。
2. AlphaGo Zero 以及 AlphaZero:學習如何以超越所有人類的水平下圍棋、象棋和將棋的純強化學習模型。科普一下,AlphaGo Zero 是DeepMind 開發出的 AlphaGo 的繼任者(AlphaGo 是第一個擊敗人類圍棋冠軍的程序)。不同於原始的通過監督學習和強化學習的結合進行學習的AlphaGo,AlphaGo Zero 純粹通過強化學習和自我對弈進行學習。因此,它在整體上緊密地遵循純強化學習的方法(智能體從完全沒有任何先驗知識的情況開始,從獎勵信號中學習知識),儘管它也使用一個事先被提供的模型(遊戲規則),並且通過自我對弈以可靠的、可持續的方式不斷提升。我們先也有文章進行介紹「阿爾法狗」再進化!通用算法AlphaZero再攻克幾種棋又有何難!。
由於AlphaGo Zero 不再從人類的經驗中學習如何獲得成功,在許多人眼中,它比 AlphaGo 對這個遊戲的改變更大。接着,AlphaZero 應運而生,它是一個更加普適的版本,被證明不僅能夠處理圍棋任務,還能對象棋、將棋進行學習。這是人們第一次用同一個算法來攻破象棋和圍棋,而且它並沒有像「深藍」和原始的 AlphaGo 那樣專門爲某種遊戲對模型進行裁剪。基於上述原因,AlphaGo Zero 和 AlphaZero 無疑是具有里程碑意義的、令人激動的成就(DeepMind 的媒體宣傳也超讚)。

李世石敗給了Alpha,這是一個歷史性的時刻。
3. OpenAI 的 Dota 機器人:用深度強化學習訓練的人工智能體能在風靡全球而且非常複雜的多人對抗遊戲——Dota2 中擊敗人類玩家。2017 年,OpenAI 成功地在有限制的 1v1 版本的 Dota2 比賽中擊敗人類職業玩家(Dendi)就足以令人印象深刻了,但是與他們最近取得的成就相比,這根本算不了什麼,要知道,他們最近成功地在複雜得多的 5v5 版本的遊戲中戰勝了人類玩家組成的隊伍。它也是 AlphaGo Zero 的繼承者,因爲它也不需要任何人類知識,完全通過自我對弈進行訓練。
毫無疑問,能夠在這個以團隊合作爲基礎、極其複雜的遊戲中獲得出色的表現,遠遠比之前玩轉 Atari 遊戲和擊敗職業圍棋選手所取得的成就更加震撼。更重要的是,這是在沒有做出任何重大的算法改進的情況下完成的。這個工作之所以能取得成功,要歸功於其令人震驚的計算量,並且使用了一個已經十分成熟的純強化學習算法,以及深度學習技術。在人工智能社區中,人們普遍認爲這是一個令人印象深刻的成就,也是強化學習的一系列重要的里程碑中的一個重要進展。
正如你所看到的,純強化學習已經取得了很大的成就。但是,現在讓我們更仔細地研究一下,看看爲什麼說這些成就沒有他們看上去的那麼偉大。
強化學習近期成果的複雜度分析
讓我們從DQN 開始討論這個問題。
DQN 可以在許多 Atari 遊戲中達到超乎常人的遊戲水平,但遠非所有遊戲。一般來說,它只能在不需要推理和記憶的條件反射類的遊戲中取得好的表現。即使在5 年後,也沒有一種純強化學習算法能夠攻破需要推理和記憶的遊戲。相反,凡是能夠在這些任務上表現優秀的模型,要麼使用了先驗信息指導(https://arxiv.org/abs/1704.05539 )要麼使用了演示(https://blog.openai.com/learning-montezumas-revenge-from-a-single-demonstration/ ),就像我們在之前的棋盤遊戲的例子中提到的那樣起作用。
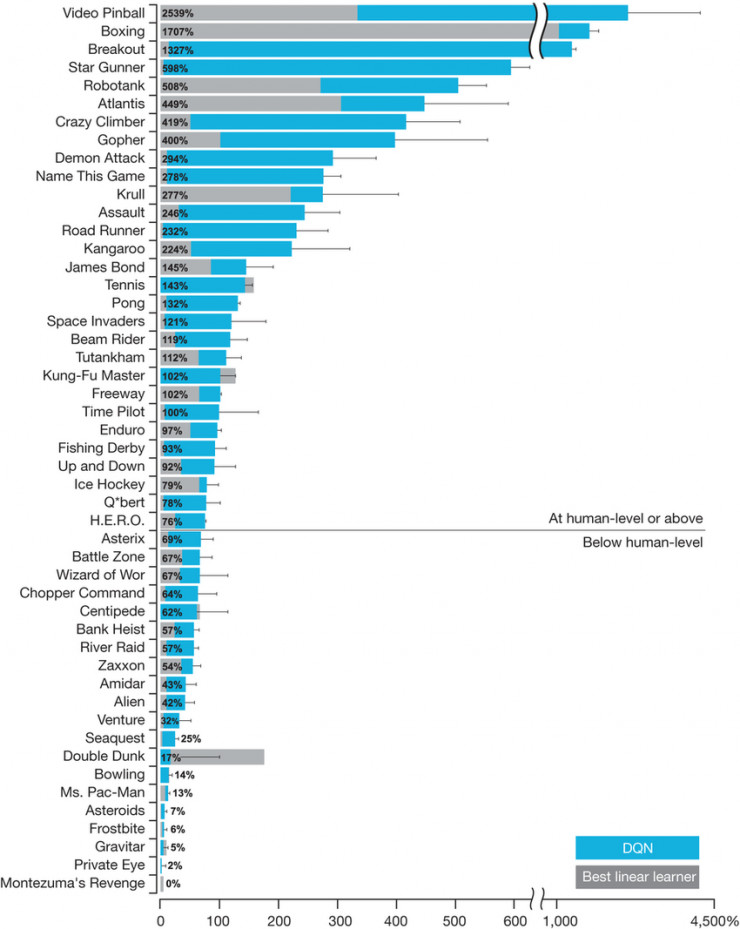
雖然 DQN 在打磚塊這樣的遊戲中性能不俗,但是它仍然不能處理相對簡單的遊戲,比如蒙特祖瑪的復仇。
即使在那些 DQN 可以取得極其優秀的性能的遊戲中,與人類相比,它還是需要大量的時間和經驗去進行學習。
建造像人一樣學習和思考的機器
AlphaGo Zero 和 AlphaZero 也存在同樣的侷限性。你知道,我們已經爲圍棋任務提供了最簡單的人工智能問題的環境,使其維持在目前這種難度級別上。也就是說,圍棋問題具備一些讓學習任務變得簡單的特性:即圍棋任務具有確定性、離散型、靜態性,而且是完全可觀察的、信息完全可知的單智能體任務,可以被分成一節一節,開銷較小、易於模擬、易於計分…… 而圍棋問題唯一的挑戰就是:巨大的分支空間。
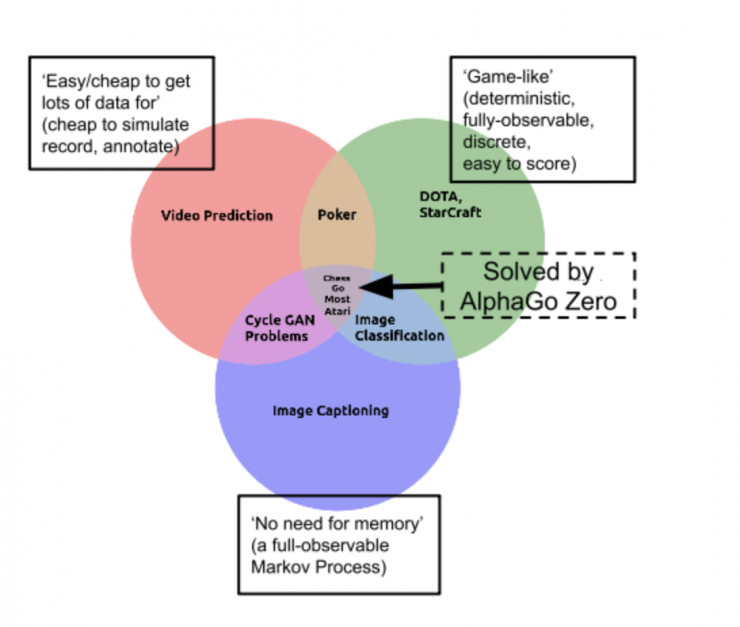
一個用於簡單說明圍棋任務類別的 Venn 圖
因此,圍棋可能是最困難(搜索空間巨大)的簡單(限制較多)問題,但歸根到底它還是一個簡單問題。而且,那些僅僅根據 AlphaGo 的成功就預測說通用人工智能(AGI)的實現近在咫尺的言論可以被直接忽略掉!由於所有上面提到的原因,更多的研究人員意識到:現實世界遠比圍棋這樣的簡單遊戲複雜得多。儘管 AlphaGo 的成功令人印象深刻,但其所有的變體(AlphaGo Zero,AlphaZero等)基本上仍然是類似於深藍的程序:這是一個開銷巨大的系統,經過了多年的設計和製造,投入了數百萬美元的資金,而這一切都純粹是爲了玩一個抽象的棋盤遊戲——除此之外別無其它意義。
至於 Dota 嘛。確實,這是一個遠比圍棋更加複雜的遊戲,而且並不像圍棋那樣有很多可以限制它、使其變得簡單的屬性。Dota 遊戲的過程不是離散的、靜態的,遊戲的局勢並不是完全可觀察的,智能體不是單一的,遊戲過程也不能被氛圍一個個回合,這確實是一類非常具有挑戰性的問題。但從本質上說,Dota 仍然可以被視爲一個通過易用的 API 控制的簡單模擬遊戲,它完全消除了對與感知和運動控制的需求。這樣一來,與我們每天在現實世界中通過學習去解決問題的真實複雜度相比,這樣的遊戲最終還是很簡單的。而且,Dota 機器人仍然和 AlphaGo 一樣,需要大量的投資和許多工程師的參與才能得出一種使用巨量時間和經驗解決問題的算法(需要長達數千年的遊戲體驗時間進行訓練,並且需要使用多達 256 個的GPU 和 128,000 個CPU 核心)。
因此,儘管我們已經取得了巨大的成就,我們對於它們還是要有一個清醒的認識。
僅僅因爲純強化學習讓我們取得了現在的成果就認爲它是完美無缺的是不對的!儘管如此,我們必須思考——純強化學習是第一個能夠實現這些成就的方法,但它是最好的方法嗎?
純強化學習的根本缺陷——從頭開始學習
是否有更好的方法讓人工智能體學會下圍棋和玩 Dota 呢?事實上,「AlphaGo Zero」這個名字指的就是模型從頭開始學習下圍棋的意思。現在,我們不妨回想一下棋盤遊戲的例子。在沒有任何解釋的情況下試圖從頭學習棋盤遊戲是很荒謬的,對嗎?那麼,爲什麼要藉助人工智能技術努力實現這個目標呢?
事實上,如果你試圖學習的棋盤遊戲是圍棋,你將如何開始學習它呢?首先,你需要閱讀規則,學習一些高層次的策略,回想一下你在過去如何玩類似的遊戲,想辦法得到一些建議…是嗎?確實如此,至少有一部分原因正是由於 AlphaGo Zero 和 OpenAI 的 Dota 機器人需要從頭開始訓練的限制使得它們與人類的學習相比並沒有那麼令人印象深刻:它們依賴於比人類多觀察好幾個數量級的遊戲,並且使用遠遠比任何人類更多的純粹計算能力。

AlphaGo Zero 的圍棋水平提升的過程。請注意,它花費了一整天的訓練時間、也就是相當於一個人數千輩子的遊戲時間達到了埃洛等級分爲 0 的水準(即使是最弱的人類玩家也能輕易得到這個分數)。圖片來自 DeepMind 的 AlphaGo Zero 博客的文章。
公平地說,純強化學習技術對於一些「範圍較窄」的任務來說是有效的,例如:連續控制(https://arxiv.org/pdf/1806.09460.pdf )或更近期的 Dota 和星際爭霸這樣的遊戲。然而,隨着深度學習大獲成功,人工智能研究社區作爲一個整體正在試圖解決更加複雜的任務,這些任務必須處理真實世界中沒有限制的、開放的複雜問題(例如,駕駛汽車或進行對話)。對於這些範圍並不那麼窄的任務(即大多數人工智能需要解決的問題),同時也爲了整個人工智能社區在未來的發展,對超越純強化學習的方法進行研究是十分必要的。
所以,讓我們繼續討論我們提到過的問題:純強化學習,以及從通常意義上來說從頭學習的思路,對範圍不窄/複雜的任務來說是否是正確的解決方法?
我們應該堅持純強化學習嗎?
這個問題的一個答案可能是:「是的,除了像圍棋和Dota 這樣的任務,純強化學習也是解決其他問題的正確方法。雖然在棋類遊戲的環境下沒有意義,「從頭開始」學習也是非常具有普適的意義的。而且,除了人類所具有的靈感,從頭開始學習是有意義的,這樣智能體不會有任何先入爲主的知識,而且也能達到比人類更高的水平(就像AlphaGo Zero 一樣)。」
讓我從這段話最後的部分開始,「忽略人類的靈感,在通用的人工智能的背景下考慮從頭開始學習的好處。「從頭開始」進行學習的理由是」:事先假定的替代品——將人類的直覺硬編碼到模型中——可能通過不必要的限定限制了模型的準確率,或者甚至通過錯誤的直覺降低了模型的性能。隨着深度學習方法的成功,這種觀點已經成爲了主流,這些方法可以學習具有數以百萬計的參數的「端到端」模型,對數量驚人的數據進行訓練,而且只用到了很少的先驗知識(http://www.abigailsee.com/2018/02/21/deep-learning-structure-and-innate-priors.html )。
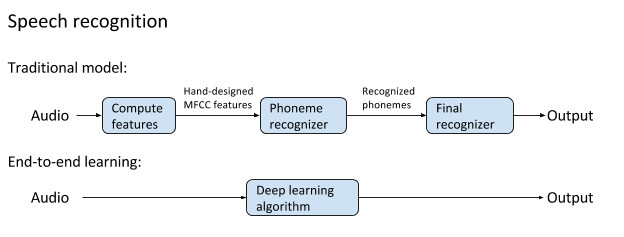
老式的傳統語音識別和端到端的深度學習方法的示意圖。後者的性能更好,而且成爲了目前最先進的語音識別的基礎。
事情是這樣的:引入先驗知識或指導並不一定需要在進行學習的智能體上強加許多給予人類直覺的限制結構。換句話說,可以告知學習的智能體或模型有關即將處理的任務的信息,而不限制它通過深度學習方式進行學習的能力(即主要通過數據傳遞信息,而不像深藍和之前的專家系統裏那樣人爲規定)。
在不久的將來,我們將看到能夠讓我們做到這一點的技術案例。但是重要的是,對於大多數的人工智能問題,不從頭開始學習並不一定會限制智能體可以以任何方式進行學習的能力。對於 AlphaGo Zero 這樣的算法,沒有明確的理由過分強調必須從頭開始學習,因爲它可能會被人類知識所引導(就像最初的 AlphaGo 一樣),或者事先從其它棋盤遊戲中學到知識,並且仍然能夠收斂到同樣的超乎常人的水平。我們應該很快就看到類似這樣的具體技術案例。
即使你不在乎這些,就是想要從頭開始訓練,那麼純強化學習是否就是最好的方法呢?給這個問題作答曾經可以不需要任何思考。在梯度無關的優化問題中,純強化學習是你可以選擇的最有條理的並且最值得信賴的方法。但最近的許多論文都對這種立場提出了嚴重的質疑,它們認爲相對簡單的(而且廣泛不受認可的)基於進化策略的方法似乎也同樣適用於純強化學習已經被經常用來測試的同類型的對比基準:
簡單的隨機搜索提供了一種對強化學習具有競爭力的方法(https://arxiv.org/abs/1803.07055 )
深度神經進化:遺傳算法是訓練用於強化學習的深度神經網絡的一種具有競爭力的選項(https://arxiv.org/abs/1712.06567 )

通過隨機搜索找到的在 Frostbite 中表現優異的智能體的例子。詳情請見對於該策略的變現的描述。它在該輪中的最終得分爲3,620,這比 DQN,A3C 和 ES 算法得到的分數都高,儘管並不像 GA(遺傳算法)得到的分數那麼高。圖片來源:https://arxiv.org/abs/1712.06567
進化策略作爲一種可伸縮的強化學習的替代品(https://arxiv.org/abs/1703.03864 )
實現連續控制的普適性和簡易性(https://arxiv.org/abs/1703.02660 )
理論和實踐優化算法的領軍研究者、論文「簡單的隨機搜索提供了一種對強化學習具有競爭力的方」的作者之一 Ben Recht 很好的總結了上述所有觀點(http://www.argmin.net/2018/03/20/mujocoloco/ ):
我們已經看到,隨機搜索在簡單的線性問題上效果很好,並且顯示出比策略梯度算法等強化學習算法更好的性能。但是隨機搜索是否會隨着我們開始處理更難的問題而崩潰呢?先說結論:並沒有!
所以,人們至今還不清楚純強化學習是否是從頭開始學習的正確方法。但是,讓我們回到人類從頭開始進行學習的問題上。人們有沒有在沒有給定任何信息(除了作爲技能的一部分可採取的動作)的情況下開始學習一項複雜的新技能(例如組裝新的宜家家居或甚至是開車)?沒有,不是嗎?
也許對於一些非常基礎和普遍的問題(比如年幼的嬰兒所面對的那些問題),從頭開始學習,進行純強化學習是很有意義的,因爲這些問題是如此廣泛。但是對於人工智能中的大多數問題來說,從頭開始學習並沒有明顯的好處:我們知道我們想要人工智能體學習到什麼,並且能夠爲其提供這種技能的演示或指導。事實上,從頭開始學習是許多廣泛被認同(https://www.wired.com/story/greedy-brittle-opaque-and-shallow-the-downsides-to-deep-learning/ )的目前人工智能和深度學習具有的限制的主要原因:
目前的人工智能非常缺乏數據(即樣本效率低下),在大多數情況下,需要大量的數據才能使最先進的人工智能方法變得有效。這對純強化學習來說尤其糟糕。回想一下,AlphaGo Zero 需要進行數以百萬次計的圍棋遊戲才能得到爲 0 的埃洛等級分,這是大多數人稍加努力就可以達到的分數。從定義上說,從頭學習可能是樣本效率最低的方法。
目前的人工智能系統是不透明的,在大多數情況下,我們對人工智能算法能學到什麼、它將如何工作只有高層次的直覺。對於大多數人工智能問題來說,我們希望算法是可預測、可解釋的。一個在只給定低層次的獎勵信號的、從頭開始學習想要的知識的大的神經網絡,或者一個環境模型(就像 AlphaGo Zero 那樣工作),可能是解釋性和可預測性最差的方法。
目前的人工智能應用的範圍很窄,在大多情況下,我們建立的人工智能模型只能完成一個很小的範圍內的任務,而且很容易就失效。從頭開始學習每一項技能限制了模型學習除了一個特定的任務之外的任意任務的能力。
目前的人工智能是脆弱的,大多數情況下,我們的人工智能模型只是通過大量的數據獲得了泛化到不可見的輸入上的能力。甚至在以後仍然是很容易失效的。
因此,我們更傾向於知道我們究竟想要人工智能體學習到什麼。如果人工智能體是一個人類,我們可以向他解釋這個任務,還可能提供一些提示。但是人工智能體終究不是人,那麼我們還能爲一個人工智能體做這些事嗎?事實證明,我們可以通過許多方法做到。欲知方法爲何,且聽下回分解(https://thegradient.pub/how-to-fix-rl/)。
via The Gradient,