選自Medium
參與:路雪、黃小天
如今,正在興起一項有關手機應用和深度學習的新動向。
2017 年 4 月:谷歌發佈 MobileNets,一個可在計算資源有限的環境中使用的輕量級神經網絡。
2017 年 6 月:蘋果推出 Core ML,允許機器學習模型在移動設備上運行。
此外,最新的高端移動設備已內置 GPU,它們在運行機器學習計算時比我的 Mac Book Pro 還要快。
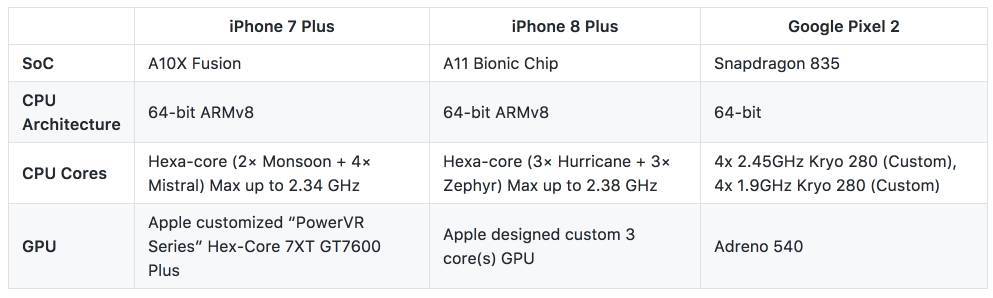
表 1. 不同手機設備處理單元對比
深度學習在邊緣設備上的應用正在擴展。
在本文中,我將介紹其實際應用情況,展示其工作效率。
MobileNets 應用
最近我們開發了一個叫作 MobileUNet 的新型深度神經網絡,可用於解決語義分割問題。本文將不詳述 MobileUNet 的細節,但是會提及它的一個非常棒的簡潔設計。顧名思義,它是在 U-Net 上運行 MobileNets(圖 1),更多信息請參見:https://github.com/akirasosa/mobile-semantic-segmentation。現在只需簡單記住以下幾點:
它包含編碼器部分和解碼器部分,具備用於語義分割的深度神經網絡的跳躍連接(skip)。
編碼器部分正是 MobileNets,它沒有用於分類的全連接層。
解碼器部分使用卷積轉置進行上採樣。
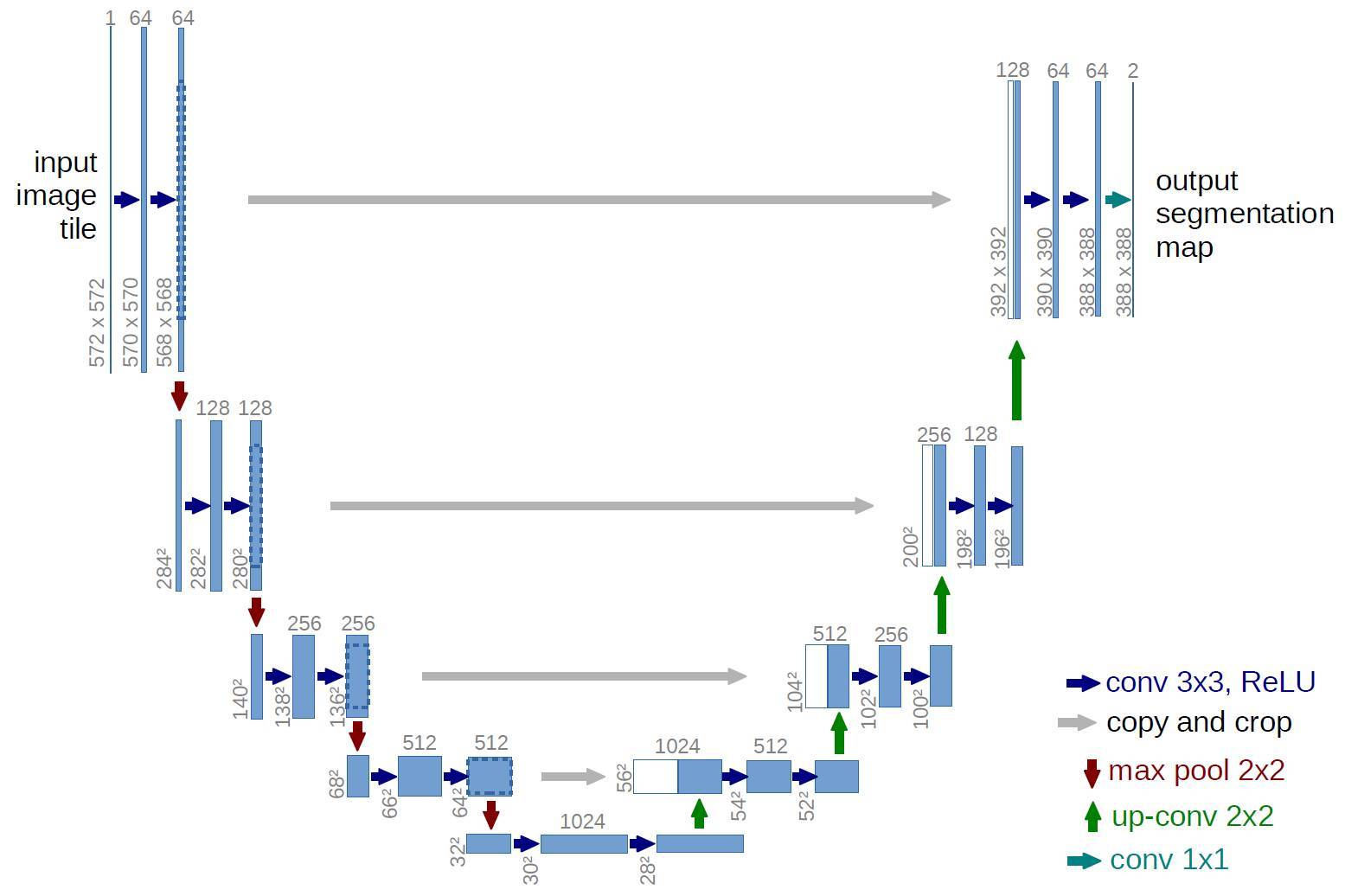
圖 1. U-Net 架構
當開始開發時,我們的主要擔憂是推斷速度。我們知道深度神經網絡藉助 GPU 只是稍快了一些,那麼在手機端運行時又會怎樣呢?
這就是我們採用 MobileNets 的原因。下面是 MobileNets 的 3 個關鍵點:
它引入了深度卷積模塊來加速推斷。
它展示了準確率與推斷速度之間的高比率。
它具備一些控制準確率與速度之間權衡的參數。
我們可以獲得相當滿意的結果,下面是一個實例:
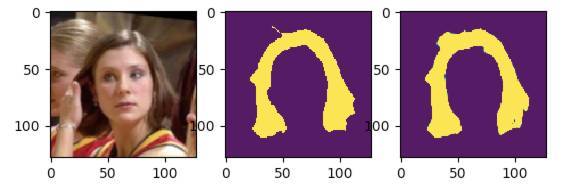
圖 2. MobileUNet 的預測結果。從左到右依次是輸入圖像、真值和預測結果。
手機端速度 vs 準確率
在討論網絡性能之前,我首先介紹一些背景信息。
每個卷積,比如 Conv2D、DepthwiseConv2D 和 Conv2DTranspose,在不同處理器上有着相似的速度趨勢嗎?
答案是否定的。如果處理器不同,一些運算可以非常快,另一些則很慢。CPU 和 GPU 之間的區別很明顯,甚至在 GPU 中,它們被優化的方式也各不相同。
圖 3 展示了一般卷積模塊和深度卷積模塊的速度,Gist 地址:https://gist.github.com/akirasosa/b31c3096d9cc1959cbbd8af40993c92d。
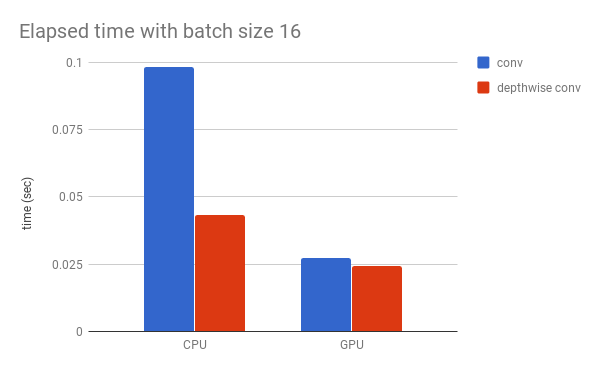
圖 3. 不同處理單元條件下,卷積模塊和深度卷積模塊的性能對比。
和理論一樣,CPU 條件下深度卷積塊的速度比卷積塊要快得多,但是這種區別在 GPU 條件下沒有這麼明顯。
那麼,如果你想在移動設備中使用深度學習發佈應用,強烈推薦使用多種主流設備評估速度。下面,我將分享 MobileUNet 的評估結果。
我在以下幾種設備上進行了評估。
iPhone 6 plus
iPhone 7 plus
iPhone 8 plus
Sony Xperia XZ(驍龍 820)
如上所述,MobileNet 有一個參數,叫作 alpha,可以控制速度和準確率之間的權衡(trade-off)。它可以輕鬆應用到 MobileUNet。我選擇了四種 alpha 值(1、0.75、0.5 和 0.25)和 4 種圖像大小(224、192、160、128)。
以下是每種條件下的整體速度。
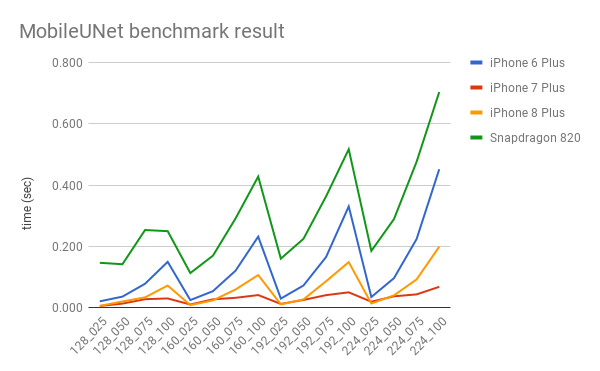
令人驚訝的是,iPhone 7 plus 獲勝了。iPhone 7 plus 真的很快,它在任何條件下對於實時應用都沒有問題。但是 iPhone 6 plus 和驍龍 820 沒有那麼快,尤其是當 alpha 值比較大的時候。因此,我們在選擇最佳條件時必須認真地考慮準確率。
以下是每種條件下的準確率。
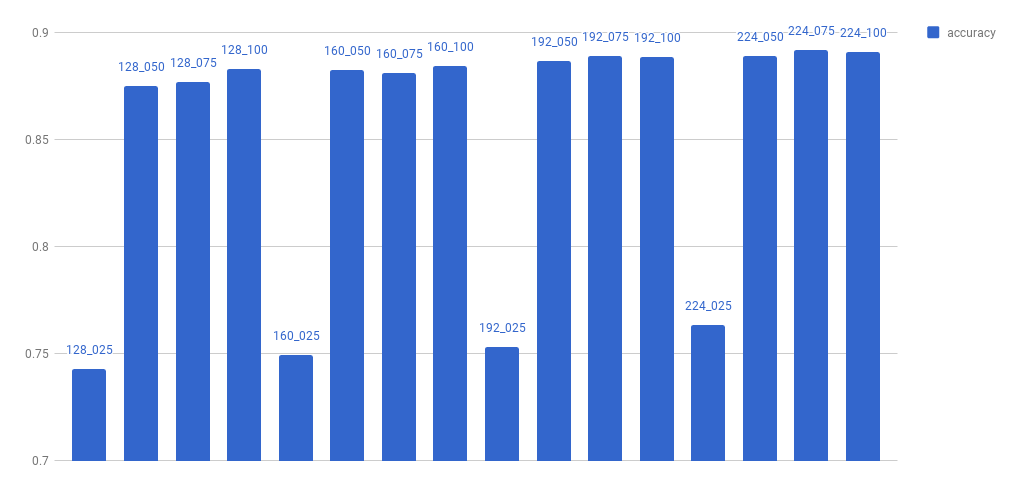
圖 5. MobileUNet 在不同條件下的準確率。
alpha 爲 0.25 時,準確率顯著下降。在其他條件下,準確率根據大小和 alpha 逐漸下降。因此,alpha 0.25 被排除。
下圖展示了驍龍 820 上模型的速度 vs 準確率。
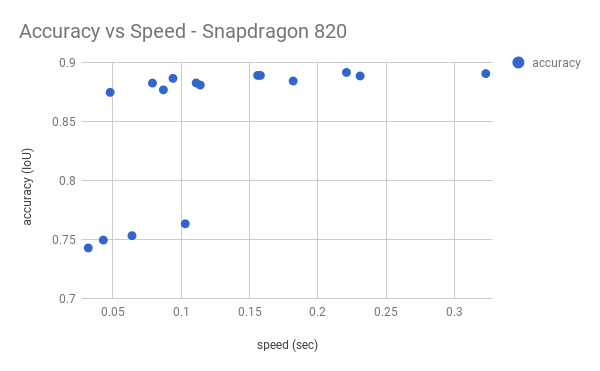
圖 6. MobileUNet 準確率 vs 速度(驍龍 820)
上圖提示了一些選項。如果對我們的應用來說速度比較重要,那就選擇左上:在大小 128、alpha 爲 0.5 的條件下它的準確率爲 0.875 IoU。如果準確率更重要,則選擇另一個可能的條件,如大小 192、alpha 爲 0.5。
每個設備也可以使用不同的模型,不過我不建議,因爲這樣複雜度太高。
最後,我們來看一下爲什麼 iPhone 7 plus 比 iPhone 8 plus 速度快。
如上所述,運行快慢取決於每個處理器,即 iPhone 7 plus 的 GPU 更加適合我們的網絡。爲了確定,我做了一個簡單的實驗。
我在編碼器和解碼器中配置 MobileUNet,然後評估 iPhone 7 plus 和 iPhone 8 plus 的性能。
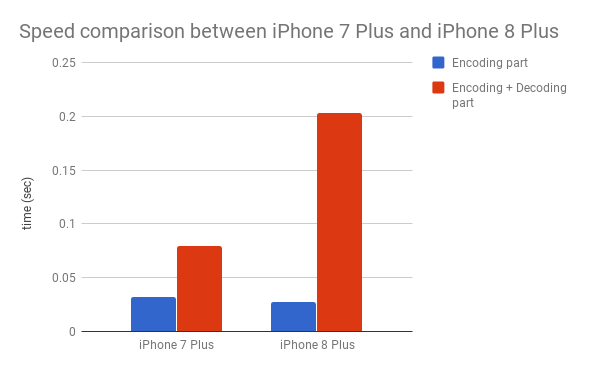
圖 7. iPhone 7 Plus 和 iPhone 8 Plus 上的速度對比。
很明顯,解碼器是 iPhone 8 Plus 的性能瓶頸,只使用了 Conv2DTranspose。因此,Conv2DTranspose 應該是造成速度差別的原因。iPhone 7 Plus 的 GPU 能夠優化 Conv2DTranspose,而 iPhone 8 Plus 的 GPU 不具備此功能。在這種情況下,其他上採樣方法可以作爲改善性能的方法,不過我還沒有試。
Gist 上有 Android 和 iOS 的基準腳本。
安卓中的基準 TensorFlow 模型(https://gist.github.com/akirasosa/812e81f14f300323df98e42ca5825604)
iOS 中的基準機器學習模型(https://gist.github.com/akirasosa/0fe78b4c173aeb49d96076db20aa9dd2)
結論
在移動設備中使用深度學習將得到廣泛應用。因此,在不久的將來深度學習將會變得更加便捷。
不過,並非所有設備都具備高性能 GPU,因此可能需要一些性能調整。使用真正的設備度量性能非常重要,因爲每個處理器具備不同的特性。只有 Multi-Add 的理論數字是不夠的。
性能度量本身並不是很難,無需訓練模型。你可以使用非訓練模型,輕鬆找到性能的瓶頸。
原文鏈接:https://medium.com/vitalify-asia/real-time-deep-learning-in-mobile-application-25cf601a8976