作者:葉錦棉等
優秀的 ResNet 和 DenseNet 等 CNN 架構試圖繞過巨大而繁瑣的全連接層,但改進 RNN 全連接式的線性變換仍然只有有限的研究。這篇電子科技大學提交 CVPR 2018 的論文正提出了一種稀疏性的張量表徵,它相對於傳統的 LSTM 不僅減少了多個數量級的參數,同時還實現了更好的收斂率與訓練速度,我們對該論文做出了簡要地介紹。
循環神經網絡(RNN)最爲擅長序列到序列的學習,它是神經網絡架構(帶有反饋連接)的一種,被設計用來捕獲數據的動態時序行爲。一般的全連接 RNN 通過反饋循環記憶先前信息,同時當梯度隨着時間步成指數消失時,它不能很好地處理長序列 [14, 2]。與通過直接矩陣-向量乘法在層之間傳遞信息的一般 RNN 不同,長短期記憶(LSTM)引入了大量的門,並通過逐元素操作 [15] 傳遞信息。這一提升極大地緩解了梯度消失問題,因此 LSTM 及其變體,比如門控循環單元(GRU)[6] 在不同的計算機視覺任務 [3, 23, 40] 中被廣泛用於建模序列中的長期關聯性。
但是,LSTM 當前的參數過多,使其非常難以訓練並容易出現過擬合。LSTM 可由下述等式描述:
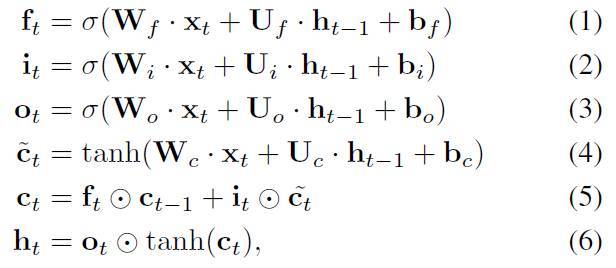
其中⊙表示對應元素間的乘積,σ(·) 表示 sigmoid 函數,tanh(·) 表示雙正切函數。權重矩陣 W_*和 U_*分別將輸入 x_t 和隱藏狀態 h_t-1 轉換爲單元更新 c_t tilde 和三個門:f_t、i_t 和 o_t。請注意,給定一個卷積神經網絡(CNN)中的圖像特徵向量 x_t,它的形狀將達到 I = 4096,和 I = 14 × 14 × 512(分別對於 vgg16 [36] 和 Inception v4 [38])。如果隱藏狀態數字爲 J=256,參數的總數量是 W_*的四倍,就是 4 × I × J,即會分別達到 4.1 × 106 和 1.0 × 108。所以,巨型矩陣向量乘法,即 W_∗ · x_t 是導致低效率的主要原因——當前的參數密集型設計不僅使模型難以訓練,而且會導致高計算複雜度和存儲佔用。
此外,每個 W_∗ · x_t 實際上代表一個全連接操作或線性變換,將輸入向量 x_t 轉換爲隱藏狀態向量。然而,人們對於 CNN 的大量研究已證明:密集連接在提取圖像中自然空間局部結構和局部相關性方面是非常低效的 [21,11]。近期的主要 CNN 結構如 DenseNet[16]、ResNet [12] 和 Inception v4 [38] 也在試圖繞過巨大而繁瑣的密集層 [39]。然而,有關改進 RNN 中密集連接的研究仍然非常有限 [29,33]。尋找更有效的設計來取代 W_* x_t 是非常有必要的。
在這項工作中,我們提出設計一個稀疏連接的張量表徵,即 BTD(Block-Term decomposition)[8],以替代 LSTM 中冗餘和密集連接的操作。BTD 是一種低秩逼近的方法,可以把高階張量分解爲多個 Tucker 分解模型 [42] 的總和。具體講,我們把四個權重矩陣(即 W_∗)和輸入數據 x_t 表徵到不同階的張量之中。在 RNN 訓練的過程中,BTD 層自動學習參數間的關聯性,以隱式剪枝掉來自 W·x 的冗餘密集連接。通過將新的 BTD 層插入到當前的 RNN 表達式,我們提出了一種新型 BT-RNN 模型,其表徵能力相似,但是參數卻少了若干個數量級。圖 1 展示了帶有 Block-term 表徵的改進 LSTM 模型。
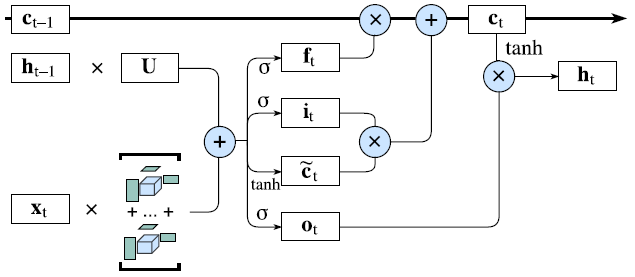
圖 1:BT-LSTM 架構。輸入與隱藏態之間的冗餘密集連接被低秩 BT 表徵所替代。
BT-RNN 的主要優點如下:
低秩 BTD 在輸入到隱藏的變換中可以壓縮密集連接,同時依然保持 LSTM 當前的設計理念。通過減少若干個數量級的模型參數,BTLSTM 相較於傳統 LSTM 架構可以實現更好的收斂率,這顯著加快了訓練速度。
輸入數據中的每個維度可與作爲核心張量(core tensors)存在的所有其它維度共享權重,因此 BT 在不同維度之間具有強連接,這提升了捕捉充足局部關聯性的能力。實證結果表明,相較於張量訓練模型 [32],BT 模型在模型參數相同的情況下有着更好的表徵能力。
多 Tucker 分解模型的設計可以顯著減少對噪音輸入數據的敏感性,並增加網絡的寬度,從而得到一個更加魯棒的 RNN 模型。與基於張量訓練的張量方法 [48, 31] 相反,BT 模型不存在選擇張量秩的困難,免除了研究者選擇超參數的乏味工作。
爲了證明 BTLSTM 模型的表現,我們設計了三個挑戰性的計算機視覺任務(視頻中的動作識別、看圖說話、圖像生成),並在對比基線 LSTM 和其它低秩變體(比如 Tensor Train LSTM/TT-LSTM)的情況下從量與質兩個方面評估 BT-LSTM。實驗結果表徵 BT-LSTM 模型的表現很有前途。
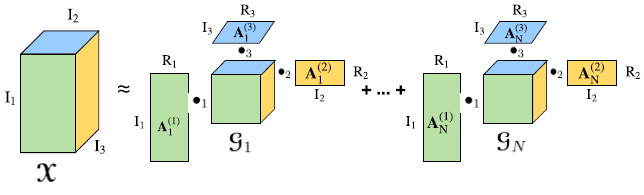
圖 2. 對三階張量進行塊分解。一個三階張量的階 X ∈ R^( I_1×I_2×I_3) 可以被近似爲 N 個 Tucker 分解。我們將 N 稱爲 CP 秩,R1、R2、R3 稱爲 Tucker 秩,d 爲核心階。

圖 3. 在三階張量情況下的張量化(Tensorization)操作。(a)將形狀爲 I = I_1 · I_2 · I_3 的向量張量化爲形狀等於 I_1 × I_2 × I_3 的張量;(b)形狀爲 I_1 ×(I_2 · I_3) 的化矩張量化爲形狀爲 I_1 ×I_2 ×I_3 的張量。
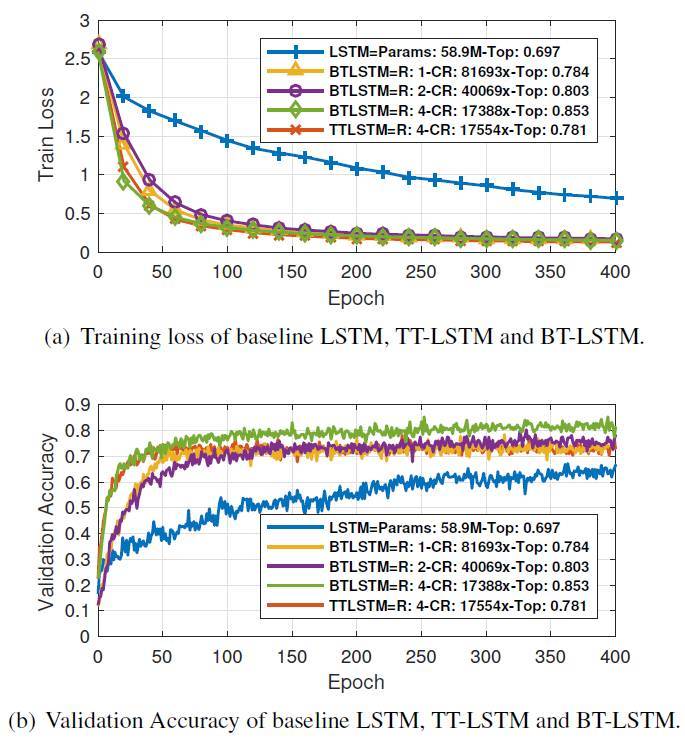
圖 6. 在 UCF11 數據集上不同 RNN 模型的動作識別任務表現。CR 表示壓縮率;R 表示 Tucker-rank,Top 表示訓練中觀察到的最高驗證準確率。雖然 BT-LSTM 要比常規 LSTM 的參數數量(5890 萬)要少 17,388 倍,前者的準確率卻比後者要高 15.6%。同時,BT-LSTM 在與 TTLSTM 參數相近的情況下有額外 7.2% 的性能提升。
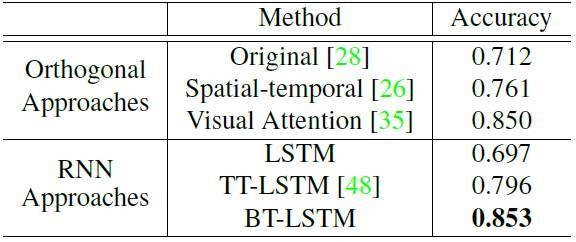
表 2. 目前 UCF11 數據集上的最佳成績與電子科技大學研究中最佳結果的對比。

圖 8. 在 MSCOCO 數據集上訓練圖像描述任務的結果。
論文:Learning Compact Recurrent Neural Networks with Block-Term Tensor Decomposition
undefined

論文鏈接:https://arxiv.org/abs/1712.05134
循環神經網絡(RNN)是一種強大的序列建模工具。然而,在處理高維輸入時,RNN 的訓練會因爲大量模型參數而變得非常耗費計算資源。這會讓 RNN 難以處理很多重要的計算機視覺任務(如視頻中的動作識別和圖像字幕)。爲了解決這一問題,我們提出了一種緊湊而靈活的新結構,它被稱爲 Block-Term 張量分解,它極大地減少了 RNN 的參數,並提高了訓練效率。與其他低秩逼近方法,如 tensor-train RNN(TT-RNN)等相比,我們的方法(BT-RNN)不僅更加簡潔(在同秩時),而且能以更少的參數獲得原始 RNN 的更好逼近。BT-RNN 在三個具有挑戰性的任務中,包括視頻中的動作識別、圖像字幕和圖像生成上的預測精度和收斂速度均超過了 TT-RNN 和標準 RNN。其中,在 UCF11 數據集上進行動作識別任務時,BT-LSTM 的參數數量要比常規 LSTM 少 17,388 倍,同時準確率提升了超過 15.6%。
第一作者:葉錦棉,電子科技大學
http://smilelab.uestc.edu.cn/members/yejinmian/
http://www.ay27.com/resume/
第二作者:Brown University 博士在讀,王林楠,此前就讀電子科技大學
https://linnanwang.github.io/