本文介紹了 T 分佈隨機近鄰嵌入算法,即一種十分強大的高維數據降維方法。我們將先簡介該算法的基本概念與直觀性理解,再從詳細分析與實現該降維方法,最後我們會介紹使用該算法執行可視化的結果。
T 分佈隨機近鄰嵌入(T-Distribution Stochastic Neighbour Embedding)是一種用於降維的機器學習方法,它能幫我們識別相關聯的模式。t-SNE 主要的優勢就是保持局部結構的能力。這意味着高維數據空間中距離相近的點投影到低維中仍然相近。t-SNE 同樣能生成漂亮的可視化。
當構建一個預測模型時,第一步一般都需要理解數據。雖然搜索原始數據並計算一些基本的統計學數字特徵有助於理解它,但沒有什麼是可以和圖表可視化展示更爲直觀的。然而將高維數據擬合到一張簡單的圖表(降維)通常是非常困難的,這就正是 t-SNE 發揮作用的地方。
在本文中,我們將探討 t-SNE 的原理,以及 t-SNE 將如何有助於我們可視化數據。
t-SNE 算法概念
這篇文章主要是介紹如何使用 t-SNE 進行可視化。雖然我們可以跳過這一章節而生成出漂亮的可視化,但我們還是需要討論 t-SNE 算法的基本原理。
t-SNE 算法對每個數據點近鄰的分佈進行建模,其中近鄰是指相互靠近數據點的集合。在原始高維空間中,我們將高維空間建模爲高斯分佈,而在二維輸出空間中,我們可以將其建模爲 t 分佈。該過程的目標是找到將高維空間映射到二維空間的變換,並且最小化所有點在這兩個分佈之間的差距。與高斯分佈相比 t 分佈有較長的尾部,這有助於數據點在二維空間中更均勻地分佈。
控制擬合的主要參數爲困惑度(Perplexity)。困惑度大致等價於在匹配每個點的原始和擬合分佈時考慮的最近鄰數,較低的困惑度意味着我們在匹配原分佈並擬合每一個數據點到目標分佈時只考慮最近的幾個最近鄰,而較高的困惑度意味着擁有較大的「全局觀」。
因爲分佈是基於距離的,所以所有的數據必須是數值型。我們應該將類別變量通過二值編碼或相似的方法轉化爲數值型變量,並且歸一化數據也是也十分有效,因爲歸一化數據後就不會出現變量的取值範圍相差過大。
T 分佈隨機近鄰嵌入算法(t-SNE)
Jake Hoare 的博客並沒有詳細解釋 t-SNE 的具體原理和推導過程,因此下面我們將基於 Geoffrey Hinton 在 2008 年提出的論文和 liam schoneveld 的推導與實現詳細介紹 t-SNE 算法。如果讀者對這一章節不感興趣,也可以直接閱讀下一章節 Jake Hoare 在實踐中使用 t-SNE 進行數據可視化。
liam schoneveld 推導與實現地址:https://nlml.github.io/in-raw-numpy/in-raw-numpy-t-sne/
論文地址:http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
因爲 t-SNE 是基於隨機近鄰嵌入而實現的,所以首先我們需要理解隨機近鄰嵌入算法。
隨機近鄰嵌入(SNE)
假設我們有數據集 X,它共有 N 個數據點。每一個數據點 x_i 的維度爲 D,我們希望降低爲 d 維。在一般用於可視化的條件下,d 的取值爲 2,即在平面上表示出所有數據。
SNE 通過將數據點間的歐幾里德距離轉化爲條件概率而表徵相似性(下文用 p_j|i 表示):
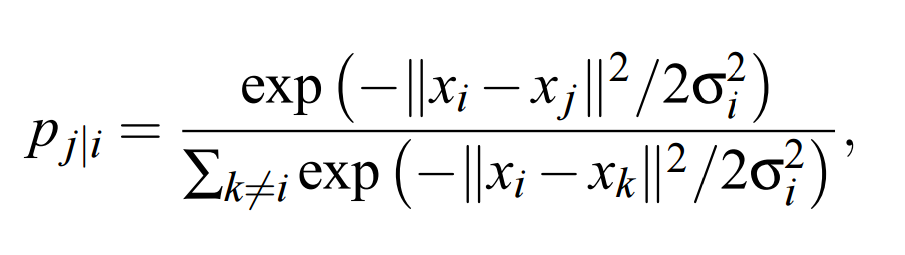
如果以數據點在 x_i 爲中心的高斯分佈所佔的概率密度爲標準選擇近鄰,那麼 p_j|i 就代表 x_i 將選擇 x_j 作爲它的近鄰。對於相近的數據點,條件概率 p_j|i 是相對較高的,然而對於分離的數據點,p_j|i 幾乎是無窮小量(若高斯分佈的方差σ_i 選擇合理)。
其中σ_i 是以數據點 x_i 爲均值的高斯分佈標準差,決定σ_i 值的方法將在本章後一部分討論。因爲我們只對成對相似性的建模感興趣,所以可以令 p_i|i 的值爲零。
現在引入矩陣 Y,Y 是 N*2 階矩陣,即輸入矩陣 X 的 2 維表徵。基於矩陣 Y,我們可以構建一個分佈 q,其形式與 p 類似。
對於高維數據點 x_i 和 x_j 在低維空間中的映射點 y_i 和 y_j,計算一個相似的條件概率 q_j|i 是可以實現的。我們將計算條件概率 q_i|j 中用到的高斯分佈的方差設置爲 1/2。因此我們可以對映射的低維數據點 y_j 和 y_i 之間的相似度進行建模:
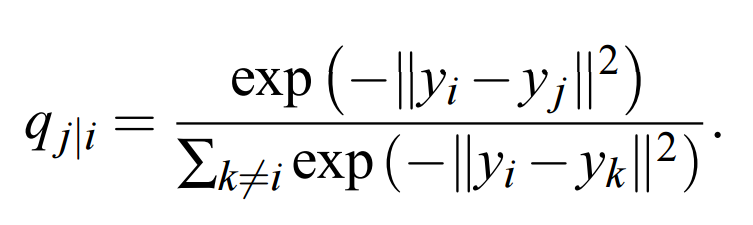
我們的總體目標是選擇 Y 中的一個數據點,然後其令條件概率分佈 q 近似於 p。這一步可以通過最小化兩個分佈之間的 KL 散度(損失函數)而實現,這一過程可以定義爲:
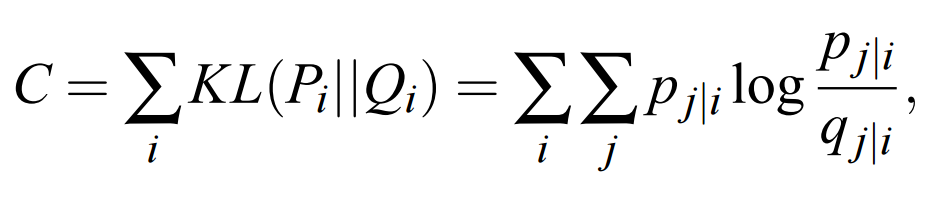
因爲我們希望能最小化該損失函數,所以我們可以使用梯度下降進行迭代更新,我們可能對如何迭代感興趣,但我們會在後文討論與實現。
使用 NumPy 構建歐幾里德距離矩陣
計算 p_i|j 和 q_i|j 的公式都存在負的歐幾里德距離平方,即-||x_i - x_j||^2,下面可以使用代碼實現這一部分:
defneg_squared_euc_dists(X):
"""Compute matrix containing negative squared euclidean
distance for all pairs of points in input matrix X
# Arguments:
X: matrix of size NxD
# Returns:
NxN matrix D, with entry D_ij = negative squared
euclidean distance between rows X_i and X_j
"""
# Math? See https://stackoverflow.com/questions/37009647
sum_X =np.sum(np.square(X),1)
D =np.add(np.add(-2*np.dot(X,X.T),sum_X).T,sum_X)
return-D
爲了更高的計算效率,該函數使用矩陣運算的方式定義,該函數將返回一個 N 階方陣,其中第 i 行第 j 列個元素爲輸入點 x_i 和 x_j 之間的負歐幾里德距離平方。
使用過神經網絡的讀者可能熟悉 exp(⋅)/∑exp(⋅) 這樣的表達形式,它是一種 softmax 函數,所以我們定義一個 softmax 函數:
defsoftmax(X,diag_zero=True):
"""Take softmax of each row of matrix X."""
# Subtract max for numerical stability
e_x =np.exp(X -np.max(X,axis=1).reshape([-1,1]))
# We usually want diagonal probailities to be 0.
ifdiag_zero:
np.fill_diagonal(e_x,0.)
# Add a tiny constant for stability of log we take later
e_x =e_x +1e-8# numerical stability
returne_x /e_x.sum(axis=1).reshape([-1,1])
注意我們需要考慮 p_i|i=0 這個條件,所以我們可以替換指數負距離矩陣的對角元素爲 0,即使用 np.fill_diagonal(e_x, 0.) 方法將 e_x 的對角線填充爲 0。
將這兩個函數放在一起後,我們能構建一個函數給出矩陣 P,且元素 P(i,j) 爲上式定義的 p_i|j:
defcalc_prob_matrix(distances,sigmas=None):
"""Convert a distances matrix to a matrix of probabilities."""
ifsigmas isnotNone:
two_sig_sq =2.*np.square(sigmas.reshape((-1,1)))
returnsoftmax(distances /two_sig_sq)
else:
returnsoftmax(distances)
困惑度
在上面的代碼段中,Sigmas 參數必須是長度爲 N 的向量,且包含了每一個σ_i 的值,那麼我們如何取得這些σ_i 呢?這就是困惑度(perplexity)在 SNE 中的作用。條件概率矩陣 P 任意行的困惑度可以定義爲:
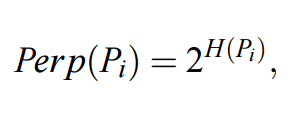
其中 H(P_i) 爲 P_i 的香農熵,即表達式如下:
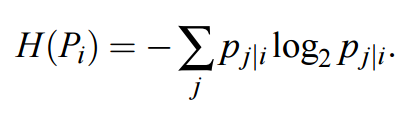
在 SNE 和 t-SNE 中,困惑度是我們設置的參數(通常爲 5 到 50 間)。我們可以爲矩陣 P 的每行設置一個σ_i,而該行的困惑度就等於我們設置的這個參數。直觀來說,如果概率分佈的熵較大,那麼其分佈的形狀就相對平坦,該分佈中每個元素的概率就更相近一些。
困惑度隨着熵增而變大,因此如果我們希望有更高的困惑度,那麼所有的 p_j|i(對於給定的 i)就會彼此更相近一些。換而言之,如果我們希望概率分佈 P_i 更加平坦,那麼我們就可以增大σ_i。我們配置的σ_i 越大,概率分佈中所有元素的出現概率就越接近於 1/N。實際上增大σ_i 會增加每個點的近鄰數,這就是爲什麼我們常將困惑度參數大致等同於所需要的近鄰數量。
搜索σ_i
爲了確保矩陣 P 每一行的困惑度 Perp(P_i) 就等於我們所希望的值,我們可以簡單地執行一個二元搜索以確定σ_i 能得到我們所希望的困惑度。這一搜索十分簡單,因爲困惑度 Perp(P_i) 是隨σ_i 增加而遞增的函數,下面是基本的二元搜索函數:
defbinary_search(eval_fn,target,tol=1e-10,max_iter=10000,
lower=1e-20,upper=1000.):
"""Perform a binary search over input values to eval_fn.
# Arguments
eval_fn: Function that we are optimising over.
target: Target value we want the function to output.
tol: Float, once our guess is this close to target, stop.
max_iter: Integer, maximum num. iterations to search for.
lower: Float, lower bound of search range.
upper: Float, upper bound of search range.
# Returns:
Float, best input value to function found during search.
"""
fori inrange(max_iter):
guess =(lower +upper)/2.
val =eval_fn(guess)
ifval >target:
upper =guess
else:
lower =guess
ifnp.abs(val -target)<=tol:
break
returnguess
爲了找到期望的σ_i,我們需要將 eval_fn 傳遞到 binary_search 函數,並且將σ_i 作爲它的參數而返回 P_i 的困惑度。
以下的 find_optimal_sigmas 函數確實是這樣做的以搜索所有的σ_i,該函數需要採用負歐幾里德距離矩陣和目標困惑度作爲輸入。距離矩陣的每一行對所有可能的σ_i 都會執行一個二元搜索以找到能產生目標困惑度的最優σ。該函數最後將返回包含所有最優σ_i 的 NumPy 向量。
defcalc_perplexity(prob_matrix):
"""Calculate the perplexity of each row
of a matrix of probabilities."""
entropy =-np.sum(prob_matrix *np.log2(prob_matrix),1)
perplexity =2**entropy
returnperplexity
defperplexity(distances,sigmas):
"""Wrapper function for quick calculation of
perplexity over a distance matrix."""
returncalc_perplexity(calc_prob_matrix(distances,sigmas))
deffind_optimal_sigmas(distances,target_perplexity):
"""For each row of distances matrix, find sigma that results
in target perplexity for that role."""
sigmas =[]
# For each row of the matrix (each point in our dataset)
fori inrange(distances.shape[0]):
# Make fn that returns perplexity of this row given sigma
eval_fn =lambdasigma:
perplexity(distances[i:i+1,:],np.array(sigma))
# Binary search over sigmas to achieve target perplexity
correct_sigma =binary_search(eval_fn,target_perplexity)
# Append the resulting sigma to our output array
sigmas.append(correct_sigma)
returnnp.array(sigmas)
對稱 SNE
現在估計 SNE 的所有條件都已經聲明瞭,我們能通過降低成本 C 對 Y 的梯度而收斂到一個良好的二維表徵 Y。因爲 SNE 的梯度實現起來比較難,所以我們可以使用對稱 SNE,對稱 SNE 是 t-SNE 論文中一種替代方法。
在對稱 SNE 中,我們最小化 p_ij 和 q_ij 的聯合概率分佈與 p_i|j 和 q_i|j 的條件概率之間的 KL 散度,我們定義的聯合概率分佈 q_ij 爲:
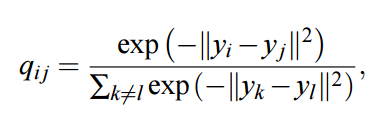
該表達式就如同我們前面定義的 softmax 函數,只不過分母中的求和是對整個矩陣進行的,而不是當前的行。爲了避免涉及到 x 點的異常值,我們不是令 p_ij 服從相似的分佈,而是簡單地令 p_ij=(p_i|j+p_j|i)/2N。
我們可以簡單地編寫這些聯合概率分佈 q 和 p:
defq_joint(Y):
"""Given low-dimensional representations Y, compute
matrix of joint probabilities with entries q_ij."""
# Get the distances from every point to every other
distances =neg_squared_euc_dists(Y)
# Take the elementwise exponent
exp_distances =np.exp(distances)
# Fill diagonal with zeroes so q_ii = 0
np.fill_diagonal(exp_distances,0.)
# Divide by the sum of the entire exponentiated matrix
returnexp_distances /np.sum(exp_distances),None
defp_conditional_to_joint(P):
"""Given conditional probabilities matrix P, return
approximation of joint distribution probabilities."""
return(P +P.T)/(2.*P.shape[0])
同樣可以定義 p_joint 函數輸入數據矩陣 X 並返回聯合概率 P 的矩陣,此外我們還能一同估計要求的σ_i 和條件概率矩陣:
defp_joint(X,target_perplexity):
"""Given a data matrix X, gives joint probabilities matrix.
# Arguments
X: Input data matrix.
# Returns:
P: Matrix with entries p_ij = joint probabilities.
"""
# Get the negative euclidian distances matrix for our data
distances =neg_squared_euc_dists(X)
# Find optimal sigma for each row of this distances matrix
sigmas =find_optimal_sigmas(distances,target_perplexity)
# Calculate the probabilities based on these optimal sigmas
p_conditional =calc_prob_matrix(distances,sigmas)
# Go from conditional to joint probabilities matrix
P =p_conditional_to_joint(p_conditional)
returnP
所以現在已經定義了聯合概率分佈 p 與 q,若我們計算了這兩個聯合分佈,那麼我們能使用以下梯度更新低維表徵 Y 的第 i 行:
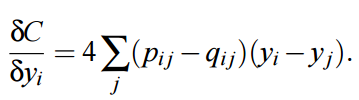
在 Python 中,我們能使用以下函數估計梯度,即給定聯合概率矩陣 P、Q 和當前低維表徵 Y 估計梯度:
defsymmetric_sne_grad(P,Q,Y,_):
"""Estimate the gradient of the cost with respect to Y"""
pq_diff =P -Q # NxN matrix
pq_expanded =np.expand_dims(pq_diff,2)#NxNx1
y_diffs =np.expand_dims(Y,1)-np.expand_dims(Y,0)#NxNx2
grad =4.*(pq_expanded *y_diffs).sum(1)#Nx2
returngrad
爲了向量化變量,np.expand_dims 方法將十分有用,該函數最後返回的 grad 爲 N*2 階矩陣,其中第 i 行爲 dC/dy_i。一旦我們計算完梯度,那麼我們就能利用它執行梯度下降,即通過梯度下降迭代式更新 y_i。
估計對稱 SNE
前面已經定義了所有的估計對稱 SNE 所需要的函數,下面的訓練函數將使用梯度下降算法迭代地計算與更新權重。
defestimate_sne(X,y,P,rng,num_iters,q_fn,grad_fn,learning_rate,
momentum,plot):
"""Estimates a SNE model.
# Arguments
X: Input data matrix.
y: Class labels for that matrix.
P: Matrix of joint probabilities.
rng: np.random.RandomState().
num_iters: Iterations to train for.
q_fn: Function that takes Y and gives Q prob matrix.
plot: How many times to plot during training.
# Returns:
Y: Matrix, low-dimensional representation of X.
"""
# Initialise our 2D representation
Y =rng.normal(0.,0.0001,[X.shape[0],2])
# Initialise past values (used for momentum)
ifmomentum:
Y_m2 =Y.copy()
Y_m1 =Y.copy()
# Start gradient descent loop
fori inrange(num_iters):
# Get Q and distances (distances only used for t-SNE)
Q,distances =q_fn(Y)
# Estimate gradients with respect to Y
grads =grad_fn(P,Q,Y,distances)
# Update Y
Y =Y -learning_rate *grads
ifmomentum:# Add momentum
Y +=momentum *(Y_m1 -Y_m2)
# Update previous Y's for momentum
Y_m2 =Y_m1.copy()
Y_m1 =Y.copy()
# Plot sometimes
ifplot andi %(num_iters /plot)==0:
categorical_scatter_2d(Y,y,alpha=1.0,ms=6,
show=True,figsize=(9,6))
returnY
爲了簡化表達,我們將使用 MNIST 數據集中標籤爲 0、1 和 8 的 200 個數據點,該過程定義在 main() 函數中:
# Set global parameters
NUM_POINTS =200# Number of samples from MNIST
CLASSES_TO_USE =[0,1,8]# MNIST classes to use
PERPLEXITY =20
SEED =1# Random seed
MOMENTUM =0.9
LEARNING_RATE =10.
NUM_ITERS =500# Num iterations to train for
TSNE =False# If False, Symmetric SNE
NUM_PLOTS =5# Num. times to plot in training
defmain():
# numpy RandomState for reproducibility
rng =np.random.RandomState(SEED)
# Load the first NUM_POINTS 0's, 1's and 8's from MNIST
X,y =load_mnist('datasets/',
digits_to_keep=CLASSES_TO_USE,
N=NUM_POINTS)
# Obtain matrix of joint probabilities p_ij
P =p_joint(X,PERPLEXITY)
# Fit SNE or t-SNE
Y =estimate_sne(X,y,P,rng,
num_iters=NUM_ITERS,
q_fn=q_tsne ifTSNE elseq_joint,
grad_fn=tsne_grad ifTSNE elsesymmetric_sne_grad,
learning_rate=LEARNING_RATE,
momentum=MOMENTUM,
plot=NUM_PLOTS)
構建 t-SNE
前面我們已經分析了很多關於隨機近鄰嵌入的方法與概念,並推導出了對稱 SNE,不過幸運的是對稱 SNE 擴展到 t-SNE 是非常簡單的。真正的區別僅僅是我們定義聯合概率分佈矩陣 Q 的方式,在 t-SNE 中,我們 q_ij 的定義方法可以變化爲:
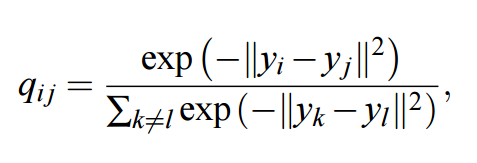
上式通過假設 q_ij 服從自由度爲 1 的學生 T 分佈(Student t-distribution)而推導出來。Van der Maaten 和 Hinton 注意到該分佈有非常好的一個屬性,即計數器(numerator)對於較大距離在低維空間中具有反平方變化規律。本質上,這意味着該算法對於低維映射的一般尺度具有不變性。因此,最優化對於相距較遠的點和相距較近的點都有相同的執行方式。
這就解決了所謂的「擁擠問題」,即當我們試圖將一個高維數據集表徵爲 2 或 3 個維度時,很難將鄰近的數據點與中等距離的數據點區分開來,因爲這些數據點都聚集在一塊區域。
我們能使用以下函數計算新的 q_ij:
defq_tsne(Y):
"""t-SNE: Given low-dimensional representations Y, compute
matrix of joint probabilities with entries q_ij."""
distances =neg_squared_euc_dists(Y)
inv_distances =np.power(1.-distances,-1)
np.fill_diagonal(inv_distances,0.)
returninv_distances /np.sum(inv_distances),inv_distances
注意我們使用 1. - distances 代替 1. + distances,該距離函數將返回一個負的距離。現在剩下的就是重新估計損失函數對 Y 的梯度,t-SNE 論文中推導該梯度的表達式爲:
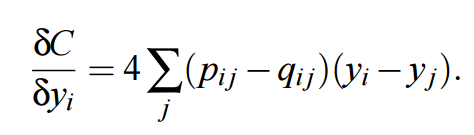
同樣,我們很容易按照計算對稱 SNE 梯度的方式構建 t-SNE 的梯度計算方式:
deftsne_grad(P,Q,Y,inv_distances):
"""Estimate the gradient of t-SNE cost with respect to Y."""
pq_diff =P -Q
pq_expanded =np.expand_dims(pq_diff,2)
y_diffs =np.expand_dims(Y,1)-np.expand_dims(Y,0)
# Expand our inv_distances matrix so can multiply by y_diffs
distances_expanded =np.expand_dims(inv_distances,2)
# Multiply this by inverse distances matrix
y_diffs_wt =y_diffs *distances_expanded
# Multiply then sum over j's
grad =4.*(pq_expanded *y_diffs_wt).sum(1)
returngrad
以上我們就完成了 t-SNE 的具體理解與實現,那麼該算法在具體數據集中的可視化效果是怎樣的呢?Jake Hoare 給出了實現可視化的效果與對比。
t-SNE 可視化
下面,我們將要展示 t-SNE 可視化高維數據的結果,第一個數據集是基於物理特徵分類的 10 種不同葉片。這種情況下,t-SNE 需要使用 14 個數值變量作爲輸入,其中就包括葉片的生長率和長寬比等。下圖展示了 2 維可視化輸出,植物的種類(標籤)使用不同的顏色表達。
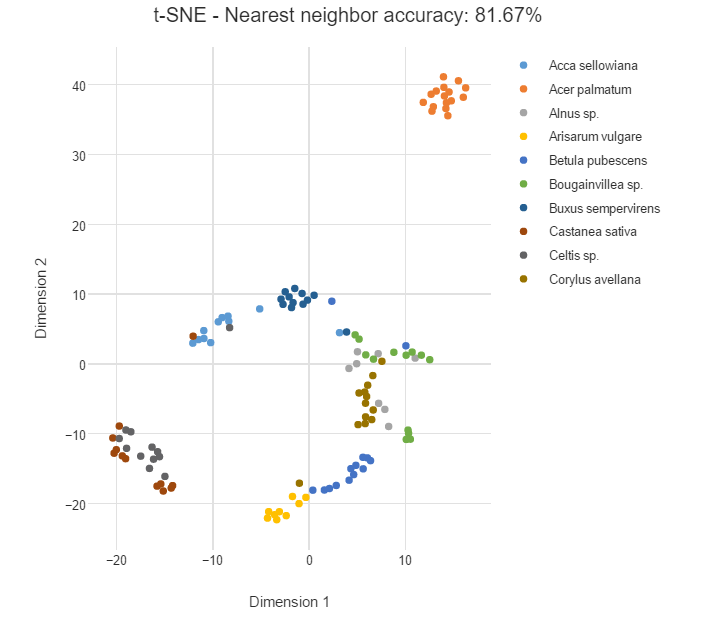
物種 Acer palmatum 的數據點在右上角形成了一個橙色集羣,這表明它的葉子和其他物種有很大的不同。該示例中類別通常會有很好的分組,相同物種的葉子(同一顏色的數據點)趨向於彼此靠緊聚集在一起。左下角有兩種顏色的數據點靠近在一起,說明這兩個物種的葉子形狀十分相似。
最近鄰準確度表明給定兩個隨機點,它們是相同物種的概率是多少。如果這些數據點完美地根據不同物種而分類,那麼準確度就會非常接近 100%,高準確度意味着數據能被幹淨地分爲不同的集羣。
調整困惑度
下面,我們對可樂品牌做了類似的分析。爲了演示困惑度(perplexity)的影響,我們首先需要將困惑度設置爲較低的值 2,每個數據點的映射只考慮最近鄰。如下,我們將看到許多離散的小集羣,並且每一個集羣只有少量的數據點。
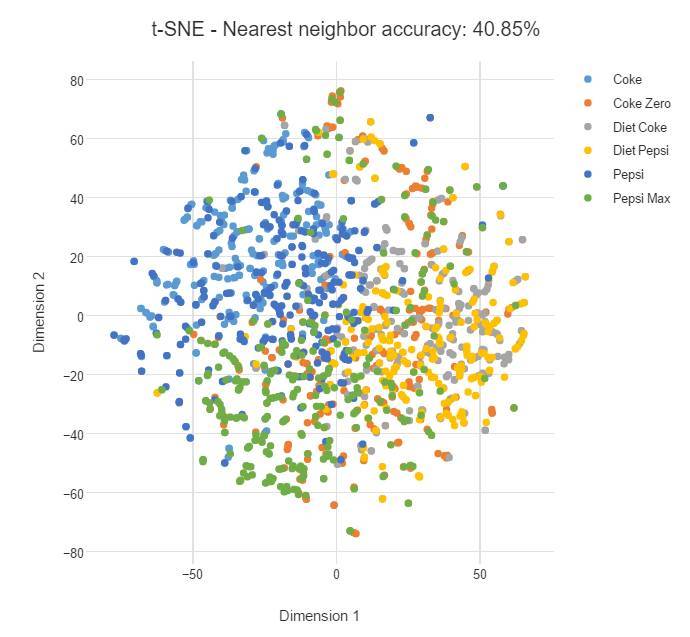
下面我們將 t-SNE 的困惑度設置爲 100,我們可以看到數據點變得更加擴散,並且同一類之間的聯繫變弱。
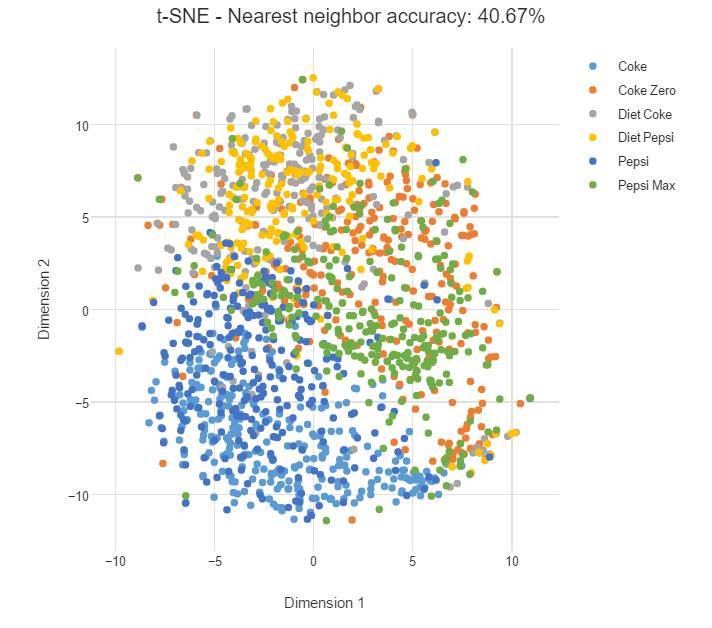
在該案例中,可樂本身就要比樹葉更難分割,即使一類數據點某個品牌要更集中一些,但仍然沒有明確的邊界。
在實踐中,困惑度並沒以一個絕對的標準,不過一般選擇 5 到 50 之間會有比較好的結果。並且在這個範圍內,t-SNE 一般是比較魯棒的。
預測的解釋
度量數據點之間的角度或距離並不能推斷出任何數據上的具體或定量的信息,所以 t-SNE 的預測更多的是用於可視化數據。
在模型搭建前期直觀地挖掘數據模式有助於指導數據科學下一步進程。如果 t-SNE 能很好地分割數據點,那麼機器學習同樣也能找到一種將未知新數據投影到相應類別的好方法。給定一種預測算法,我們就能實現很高的準確度。
上例中每一個類別都是孤立分類的,因此簡單的機器學習模型就能將該類別與其他類別分離開。但如果類別重疊,我們可能就要構建更精細的模型做出預測。如下所示,如果我們按照某個品牌的偏好從 1 到 5 進行分類,那麼類別可能更加離散、更難以預測,最近鄰精度也會相對較低。
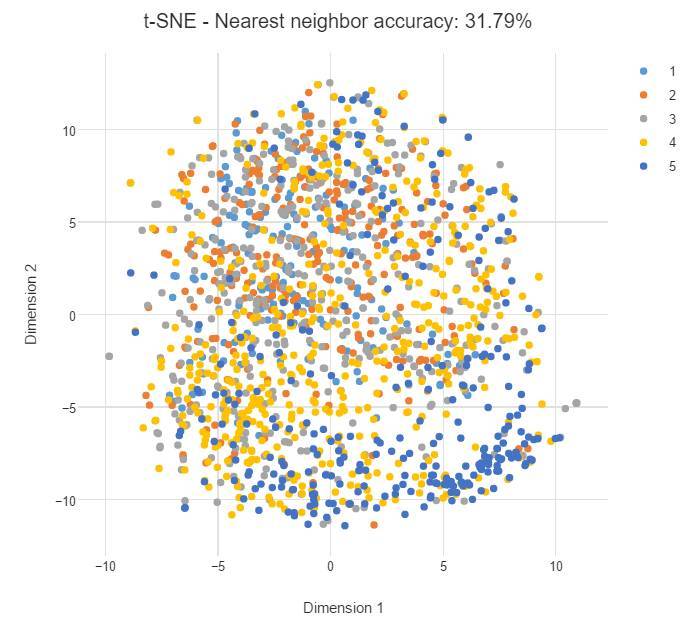
對比 PCA
很自然我們就希望將 t-SNE 和其他降維算法做比較。降維算法中比較流行的是主成分分析法(PCA),PCA 會尋找能儘可能保留數據方差的新維度。有較大的方差的數據保留的信息就越多,因爲彼此不同的數據可以提供不同的信息,所以我們最好是保留彼此分離的數據點,因爲它們提供了較大的方差。
下面是採用 PCA 算法對上文的樹葉類別進行降維的結果,我們看到雖然左側的橙色是分離的,但其它類別都有點混合在一起。這是因爲 PCA 並不關心局部的最近鄰關係,此外 PCA 是一種線性方法,所以它表徵非線性關係可能效果並不是很好。不過 PCA 算法在壓縮數據爲更小的特徵向量而投入到預測算法中有很好地表現,這一點它要比 t-SNE 效果更好。
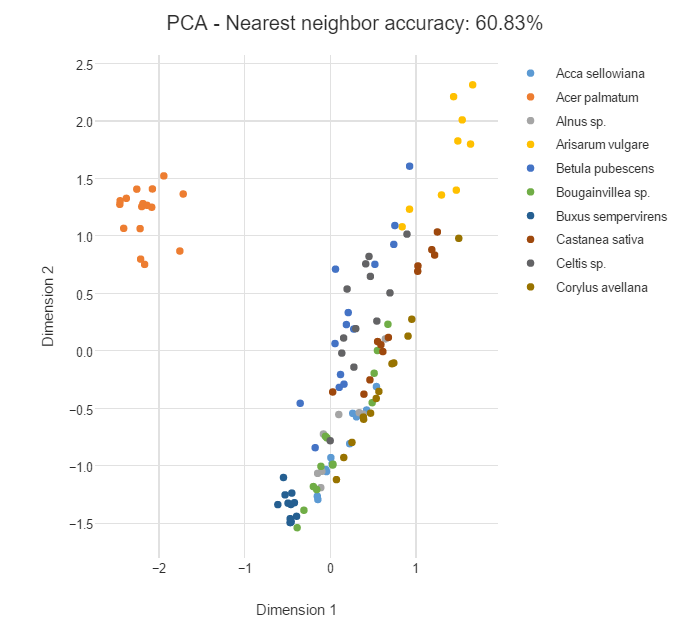
結語
t-SNE 是一種可視化高維數據的優秀算法,它經常要比其它降維算法生成更具特點的可視化結果。在數據分析中,獲得數據的先驗知識總是很重要的,正如華羅庚先生說過:數無形時少直覺,形少數時難入微,我們只有先理解了數據的大概分佈,然後再能選擇具體的算法對這些數據進一步分析。數形結合百般好,隔離分家萬事休,也許高維數據的可視化與機器學習算法的結合纔是數據分析的正確打開方式。
參考鏈接:
http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
https://www.displayr.com/using-t-sne-to-visualize-data-before-prediction/
https://nlml.github.io/in-raw-numpy/in-raw-numpy-t-sne/