雷鋒網(公衆號:雷鋒網)AI科技評論按:近期Yann LeCun的新作《Hierarchical loss for classification》已經放在了arXiv上,聯合作者爲Facebook人工智能研究院的Cinna Wu和 Mark Tygert。

在這篇文章中,作者認爲在分類任務中,一般的神經網絡模型(例如LeCun, Bengio 和 Hinton等人2015年中的模型,其他研究的模型也大多基於此展開的)很少會考慮到類型之間的親疏關係,例如這些模型的分類學習過程中並沒有考慮牧羊犬事實上比摩天大樓更像哈巴狗。在文章中,作者通過「超度規類樹」構造了一種新的損失函數,稱爲「層級損失函數」。這種損失函數因爲內含了類型樹中不同類之間的親疏關係,預期中應當能夠增強分類學習的效果。不過經過六組實驗的對比,作者發現結果並沒有顯著的改進。作者認爲,不管怎麼着吧,至少這表明層級損失函數能用。
雷鋒網認爲,它不僅能用,還極具潛力,因爲LeCun只是用了最簡單的「超度規類樹」來闡述這種思想,相信在選用更合適的超度規樹後,分類學習會得到一個更好的結果。下面我們來看具體內容。
一、構建層級損失/獲得函數
注:由於獲得函數(Win Function)與損失函數是同一個內容的相反表示,訓練過程其實就是在尋找最小的損失函數或者最大的獲得函數。所以接下來只考慮層級獲得函數的構建。
構建層級獲得函數,首先需要一個類樹,也即將待分的所有類按照親疏關係放到一顆關係樹中,每一個類都是類樹中的「樹葉」。對於一個輸入,分類器會映射到類樹每個樹葉上一個概率值,也即一個概率分佈(圖中P1-P7)。類樹中每個節點處,文章中規定,其對應的概率值爲其下所有樹葉概率值的和,如圖中所示。顯然在不考慮計算機的浮點誤差的情況下,「根部」的概率應該爲1。
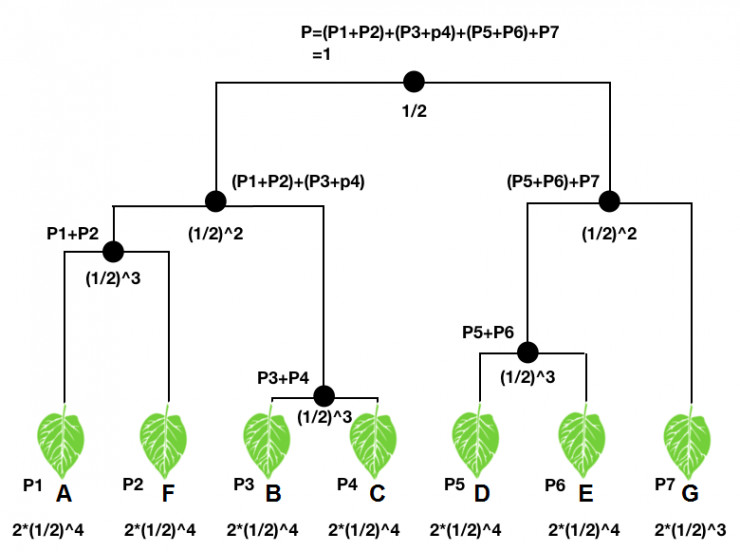
另一方面,對每個「節點」和「樹葉」都賦予一個權重。文章中規定,「根部」的權重爲1/2,隨後每經過一個「節點」,權重乘以1/2,直到樹葉;樹葉的權重由於是「樹」的末端,所以其權重要雙倍,如圖所示。
如果我們輸入一張A的圖片,那麼我們可以計算其層級獲得函數W:
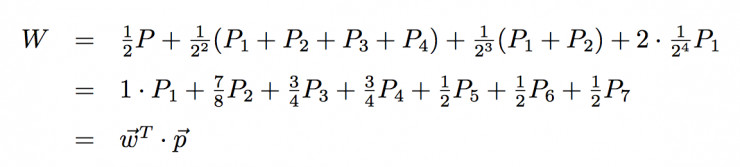
其中
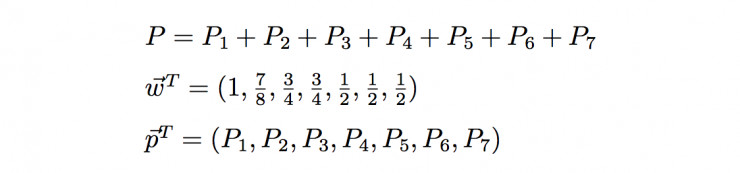
從上面可以看到,事實上層級獲得函數的構造非常簡單,就是一個結構權重向量和概率分佈向量的一個點乘。同樣可以看出,不管分類器給出什麼樣的概率分佈,層級獲得函數的範圍都在[1/2,1]區間內;當P1=1時,W最大,爲1;而當P5、P6、P7中的任意一個等於1時,W最小,爲1/2。在類樹中接近A的類的概率越大,層級獲得函數值就越大,所以層級獲得函數在某種程度上隱含了類之間親疏的關係,也構建了分類器準確度的一種度量。
二、一種改進:獲得函數的對數
有時候分類器給出的分佈可能不是概率,這時候爲了獲得一個正則的分佈,我們可以使用softmax函數的方法,也即將(x1, x2, x3, ……xn)的分佈序列轉換成
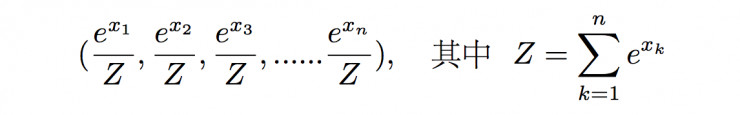
這樣的概率分佈,顯然滿足正則性,且分佈在(0,1)區間內。這種方法不僅可以對向量進行歸一化,更重要的是它能夠凸顯出其中最大的值並抑制遠低於最大值的其他分量。
當採用softmax函數的結果作爲概率分佈時,最好是使用層級獲得函數W的對數進行優化學習,而不是W本身。使用logW進行優化的好處之一就是,當輸入樣本爲多個獨立樣本時,它們的聯合概率將是它們概率的乘積;這時候對這些樣本的獲得函數W進行求平均就具有了意義(在特殊情況下logW的平均將等於聯合概率的對數)。
文章中對logW’ 的構建爲:舍掉W中「根部」的項,然後將剩下的部分乘以2,此時W’=(W-1/2)*2的範圍在[0,1]之間(其中0對應最錯誤的分類,1則對應完全正確的分類),相應的,logW’將在(-∞,0]之間。
這就會導致一個問題。當多個獨立樣本,求log W’的平均值時,只要有一個出現了最錯誤的判斷,那麼不管其他樣本的結果如何,log W’的平均值都會等於無窮大。所以這種方法對樣本及學習過程都有非常嚴格的要求。
三、實驗結果不理想
作者隨後用Joulin等人的fastTest文本分類監督學習模型對層級獲得函數進行了六組實驗(六個數據集)。結果如下:
說明:
(1)flat表示沒有分類的情況(沒有分類相當於類樹只有一個層級),raw表示用層級獲得函數進行訓練,log表示用負的層級獲得函數的對數進行訓練,course表示在層級中使用通常的交叉熵損失函數只分類到最粗糙類(聚合)。
(2)one-hot win via hierarchy 表示餵給層級獲得函數的概率分佈爲獨熱碼(只有一個爲1,其餘爲0)
(3)softmax win via hierarchy 表示餵給層級獲得函數的概率分佈爲softmax函數的結果;
(4)−log of win via hierarchy 表示(3)中層級獲得函數的負自然對數;
(5)cross entropy表示使用交叉熵損失函數計算的結果,這種情況相當於類樹只有一個層級;
(6)coarsest accuracy 表示最粗糙分類正確的比例結果;
(7)parents’ accuracy 表示父級分類正確的比例結果;
(8)finest accuracy 表示分類到最終每一個類中正確的比例結果。
(9)最後一行的「higher」和「lower」分別表示相應的列中「越大」和「越小」的值越好。
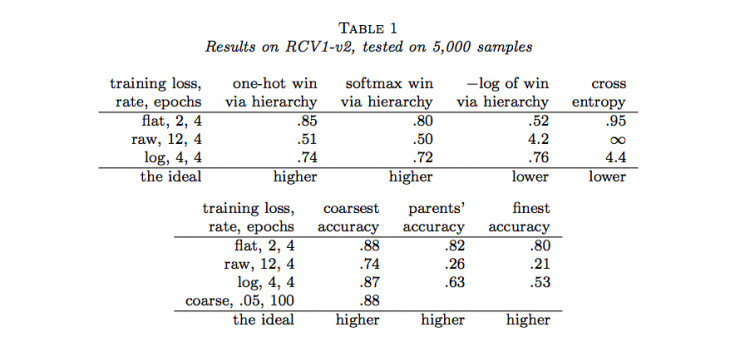
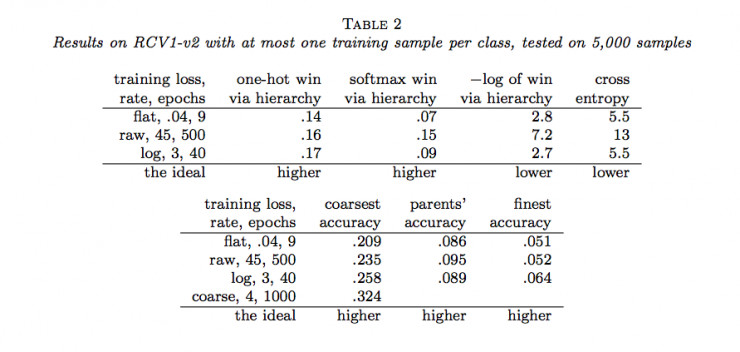
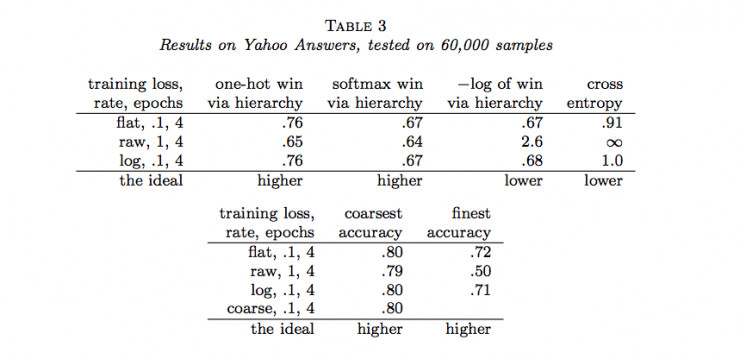
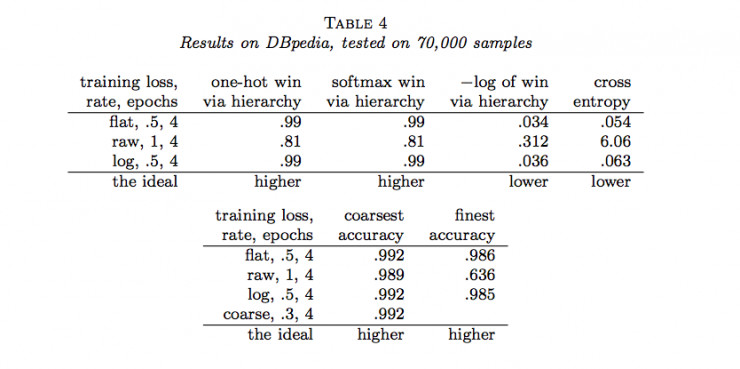
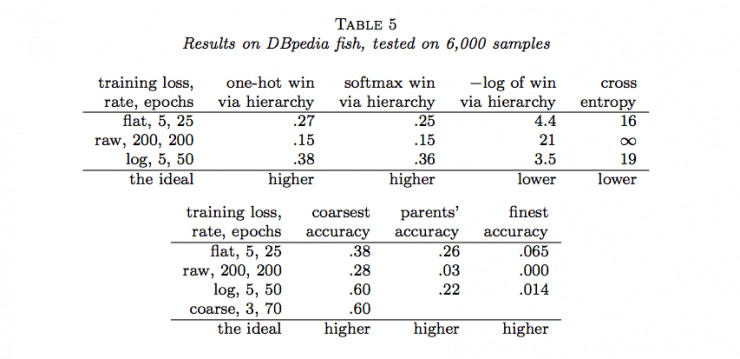
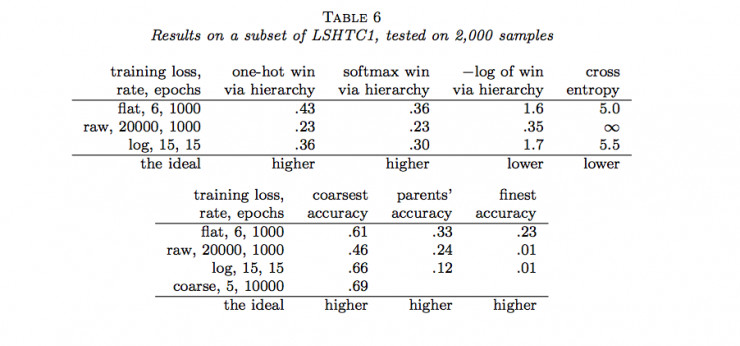
通過以上結果,我們可以看到很多時候,通過層級獲得函數優化的結果並沒有原來通過交叉熵損失函數優化的結果好。那麼,LeCun的這項工作白做了嗎?也並不是,至少它表明在一定程度上層級獲得函數能夠用做作爲分類準確度的度量,它暗示了一種可能:當有采用更合適的層級獲得函數時,效果可能會超過當前所常用的交叉熵損失函數等方法。
那麼機會來了,「更合適」有多種可能,就看你如何構造了!
雷鋒網注:原文鏈接 https://arxiv.org/pdf/1709.01062.pdf