
對開發者來說,目前有一系列的機器學習模型可供選擇。雷鋒網(公衆號:雷鋒網)瞭解,可以用線性迴歸模型預測具體的數值,用邏輯迴歸模型對不同的運算結果進行歸類,以及用神經網絡模型處理非線性的問題等等。
不論哪一種,當模型選定之後,下一步就是利用大量的現有數據對相關的機器學習算法進行訓練,探究既定的輸入數據和預想的輸出結果之間的內在關係。但這時可能會出現一種情況:訓練結果能夠成功應用於原始輸入和輸出,可一旦有新的數據輸入就不行了。
或者說得更直白一點,應該怎樣評估一個機器學習模型是否真的行之有效呢?雷鋒網從偏差、方差、正確率和查全率等四個方面對這一問題展開了探討,並給出五條改進措施。
高偏差或高方差(High Bias or High Variance)
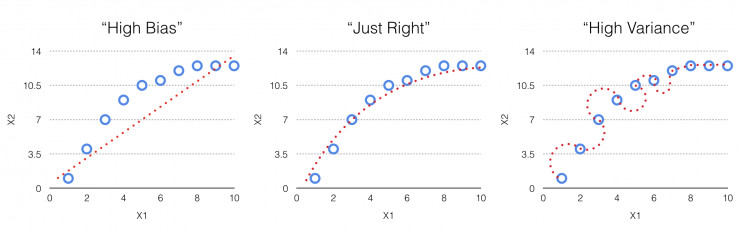
當我們評估一個機器學習模型時,首先要做的一件事就是:搞清楚這個模型的偏差和方差是否太大。
高偏差:如上圖1所示,所謂高偏差就是指在取樣點上模型的實際輸出和預想輸出不匹配,而且相差很遠。出現這一問題的原因是模型並沒有準確表徵既定輸入和預想輸出之間的關係,從而造成輸出結果的高錯誤率。
高方差:這種情況與高偏差的情況正好相反。在這一場景中,所有的取樣點結果都與預期結果完全相符。看起來模型的工作狀態完全正常,但其實隱藏着問題。這樣的情況往往容易被忽視,就好像上文提到的,模型能夠成功應用於原始輸入和輸出,但一旦輸入新數據,結果就會漏洞百出。
那麼問題來了,如何排查一個模型是否具有高偏差或者高方差呢?
一個最直接的辦法就是對數據進行交叉驗證。常見的交叉驗證方法有很多,例如10折交叉驗證、Holdout驗證和留一驗證等。但總體思路是一樣的:拿出大部分的數據(例如70%)進行建模,留一小部分(例如30%)的數據作爲樣本,用剛剛建立的模型進行測試,並評估測試結果。持續進行這一過程,直到所有的樣本數據都恰好被預測了一次爲止。
經過交叉驗證,就可以很方便地排查一個模型的偏差和方差情況。當建模數據和測試數據的輸出結果都出現與預期結果的不匹配時,那就說明模型的偏差較大。反之,如果建模數據表現正常,而測試數據存在不匹配,那就說明模型的方差較大。同時,如果建模數據和測試數據的輸出結果都與預期結果相匹配,那麼就證明這一模型順利通過了交叉驗證,在偏差和方差之間找到了一個很好的平衡點。
不過,即使偏差和方差都表現正常,一個機器學習模型也不一定就能正常工作,因爲還可能受到其他因素的影響,例如正確率和查全率。
低正確率或低查全率(Low Precision or Low Recall)
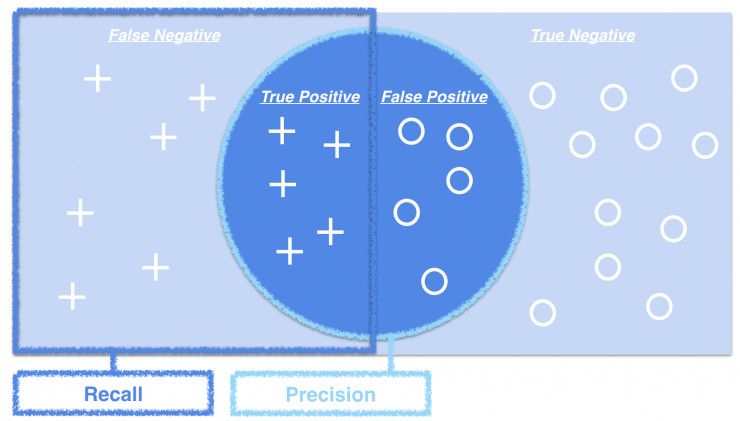
這裏可以用垃圾郵件篩選的例子來說明什麼是正確率和查全率。在一般情況下,我們收到的大約99%的郵件都是正常郵件,而只有1%是垃圾郵件(這裏不妨稱「垃圾郵件」爲正向判斷,而「正常郵件」爲反向判斷,後續會用到)。而如果一個機器學習模型被以類似這樣分佈的數據進行訓練,那麼其訓練結果很可能是:機器的判定結果有99%都是正確的,雖然正確率很高,但其中也一定漏掉了那1%的垃圾郵件(這顯然不是我們想要的結果)。
在這種情況下,最適於利用正確率和查全率來評估一個模型是否真的行之有效。
如圖所示,所謂正確率是指所有正向判斷中,最終判斷正確的比例。計算方法是用正向判斷中正確的次數除以所有正向判斷的次數。而查全率是指正向判斷中正確的次數,佔實際正向結果的比例。計算方法是用正向判斷中正確的次數,除以正向判斷中正確的次數與反向判斷中錯誤的次數之和。
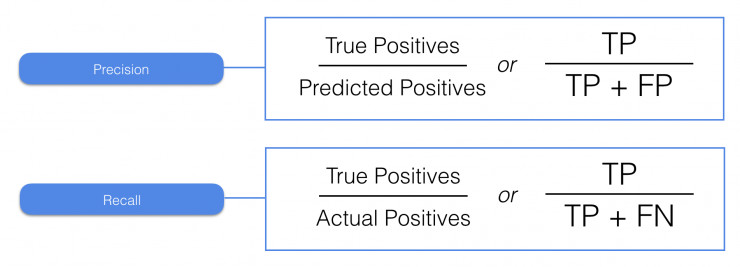
乍一看似乎有點拗口,這裏用具體的數字解釋一下。例如一個模型一共做了2次正向判斷,其中1次是正確的,10次反向判斷,其中8次是正確的。如果用郵件的例子來看,也就意味着系統一共收到了12封郵件,其中9封是正常郵件,3封是垃圾郵件。那麼其正確率就是1/2=50%,而查全率就是1/3=33%。
可以看到,正確率反應了一個模型的預測準確度,而查全率反應了一個模型的實際應用效果。一個機器學習模型的設計目標應該是在正確率和查全率中找到一種平衡,一方面努力增加正向判斷中正確的次數,一方面減小反向判斷中錯誤的次數。
五條改進措施
根據以上內容,在面對偏差和方差,正確率和查全率的相關問題時,有以下5點意見可供參考。
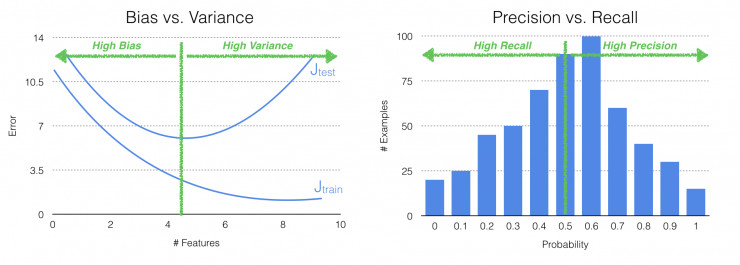
當模型出現高偏差時,嘗試增加輸入特徵的個數。如上文討論的,當建模數據和測試數據的輸出結果都出現與預期結果的不匹配時,那就說明模型的偏差較大。根據一般的模型輸入特徵和預測錯誤之間的關係圖表可以看出(如上圖所示),隨着輸入特徵的增加,偏差會顯著減小。
反之,當模型出現高方差時(也即出現了過耦合),這時可以嘗試減少輸入特徵的個數。從圖表中也可以看出,當輸入特徵進一步增加時,雖然建模數據的錯誤會越來越少,但測試數據的錯誤會越來越多。因此,輸入特徵並不能無限制地增加,在高方差的情況下嘗試減少輸入特徵的個數,可以找到二者之間的平衡。
另外,通過增加訓練用例的個數也可以顯著減少高方差的出現。因爲隨着測試用例的增加,模型的通用性也就越好,能應對更多變的數據,也即方差越小。
當正確率較低時,嘗試增加概率閾值。如上圖所示,劃分正向判斷和反向判斷的概率閾值與正確率和查全率之間關係密切。隨着閾值的增加,模型對正向的判斷也就越保守,正確率也就越高。
反之,當出現較低的查全率時,可以嘗試減小概率閾值。因爲概率閾值的減小意味着模型會做出更多的正向判斷,正向判斷的次數多了,查全率就會跟着提升。
總之,經歷的迭代和調試越多,就越可能找到偏差和方差、正確率和查全率之間的平衡,也就越可能找到一個行之有效的機器學習模型。
來源:kdnuggets ,由雷鋒網編譯
【兼職召集令!】
如果你對未來充滿憧憬,喜歡探索改變世界的科技進展,look no further!
我們需要這樣的你:
精通英語,對技術與產品感興趣,關注人工智能學術動態的蘿莉&萌妹子&技術宅;
文字不求妙筆生花,但希望通俗易懂;
在這裏,你會收穫:
一羣來自天南地北、志同道合的小夥伴;
前沿學術科技動態,每天爲自己充充電;
更高的生活品質,翻翻文章就能掙到零花錢;
有意向的小夥伴們把個人介紹/簡歷發至 guoyixin@leiphone.com,如有作品,歡迎一併附上。
