要想實現足夠聰明的人工智能,算法必須學會如何學習。很多研究者們曾對此提出過不同的解決方案,其中包括 UC Berkeley 的研究人員提出的與模型無關的元學習(MAML)方法。本文將以 MAML 爲例對目前的元學習方向進行簡要介紹。
對我而言,第一次聽到元學習的預述時,是一個極其興奮的過程:建立不僅能夠進行學習,還能學會如何進行學習的機器項目。元學習試圖開發出可以根據性能信號做出響應,從而對結構基礎層次以及參數空間進行修改的算法,這些算法在新環境中可以利用之前積累的經驗。簡言之:當未來主義者們編織通用 AI 的夢想時,這些算法是實現夢想必不可少的組成部分。
本文的目的在於將這個問題的高度降低,從我們想得到的、自我修正算法做得到的事情出發,到這個領域現在的發展狀況:算法取得的成就、侷限性,以及我們離強大的多任務智能有多遠。
爲什麼人類可以做到這些事?
具體地講:在許多強化學習任務中,和人類花費的時間相比,算法需要花費驚人的時間對任務進行學習;在玩 Atari 遊戲時,機器需要 83 小時(或 1800 萬幀)纔能有人類幾小時就能有的表現。
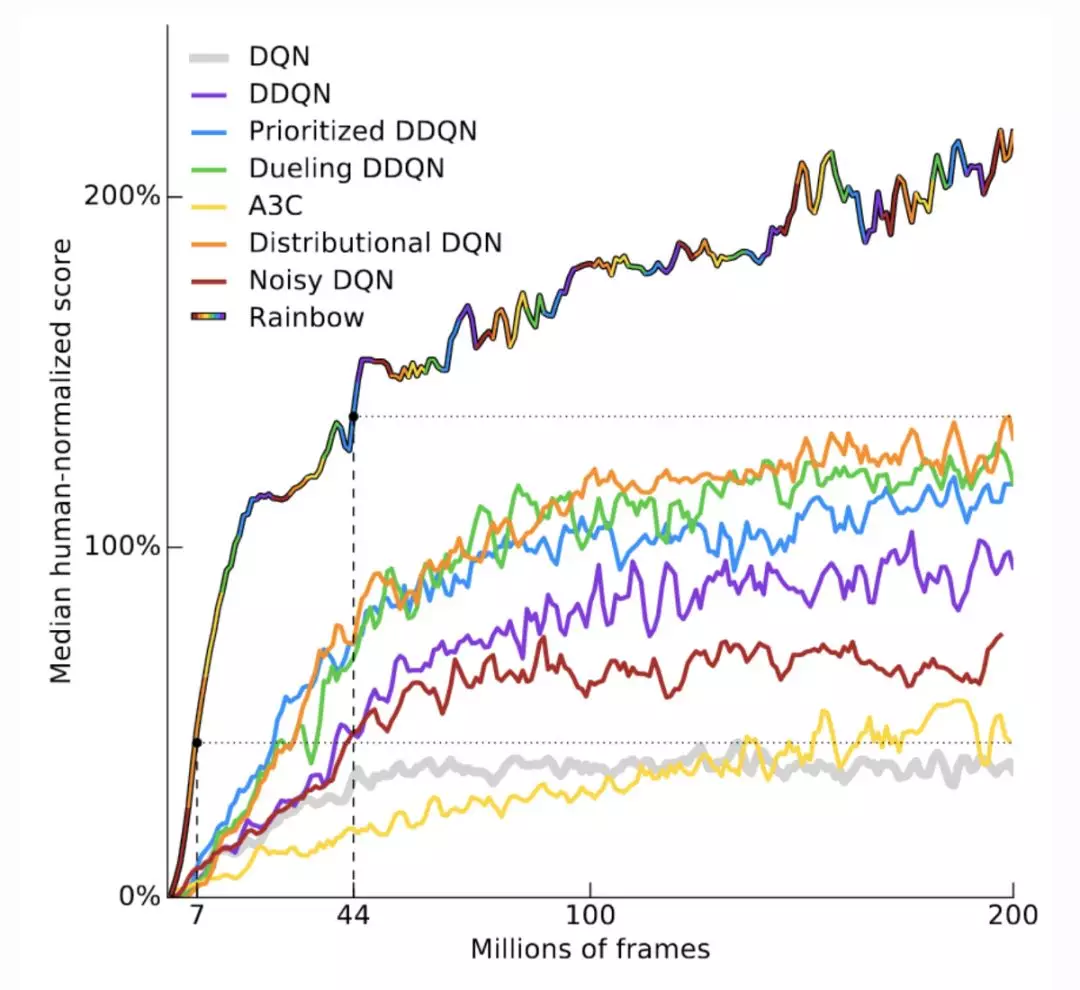
來自近期 Rainbow RL 論文中的圖片
這種差異導致機器學習研究人員將問題設計爲:人類大腦中針對這項任務使用的工具和能力是什麼,以及我們如何用統計和信息理論的方法轉化這些工具。針對該問題,元學習研究人員提出了兩種主要理論,這兩種理論大致與這些工具相關。
學習的先驗:人類可以很快地學會新任務是因爲我們可以利用在過去的任務中學到的信息,比如物體在空間裏移動的直觀的物理知識,或者是在遊戲中掉血得到的獎勵會比較低這樣的元知識。
學習的策略:在我們的生活中(也許是從進化時間上講的),我們收集的不僅是關於這個世界對象級的信息,還生成了一種神經結構,這種神經結構在將輸入轉化爲輸出或策略的問題上的效率更高,即使是在新環境中也不例外。
顯然,這兩個想法並非互相排斥,在這兩個想法間也沒有嚴格的界限:一些與現在的世界交互的硬編碼策略可能是基於這個世界的深度先驗的,例如(至少就本文而言)這個世界是有因果結構的。也就是說,我認爲這個世界上的事情都可以用這兩個標籤分開,而且可以將這兩個標籤看作相關軸的極點。
不要丟棄我的(單)樣本
在深入探討元學習之前,瞭解單樣本學習相關領域的一些概念是很有用的。元學習的問題在於「我該如何建立一個可以很快學習新任務的模型」,而單樣本學習的問題在於「我該如何建立一個在看過一類的一個樣本後,就能學會該如何將這一類分出來的模型」。
讓我們從概念上思考一下:是什麼讓單樣本學習變得困難?如果我們僅用相關類別的一個樣本試着訓練一個原始模型,這個模型幾乎肯定會過擬合。如果一個模型只看過一幅圖,比如數字 3,這個模型就無法理解一張圖經過什麼樣的像素變化,仍然保持 3 的基本特徵。例如,如果這個模型只顯示了下面這列數字的前三個樣本,它怎麼會知道第二個 3 是同一類的一個樣本呢?理論上講,在網絡學習中,我們想要的類別標籤有可能與字母的粗細程度有關嗎?對我們而言做出這樣的推斷這很傻,但是在只有一個「3」的樣本的情況下,想讓神經網絡能做出這樣的推理就很困難了。
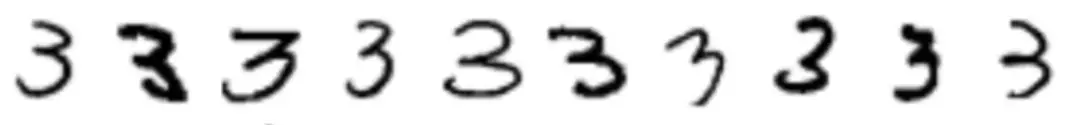
有更多樣本會有助於解決這一問題,因爲我們可以學習一張圖中什麼樣的特徵可以定義其主要特徵——兩個凸的形狀,大部分是垂直的方向,以及無關緊要的改變——線的粗細、還有角度。爲了成功實現單樣本學習,我們不得不激勵網絡,在沒有給出每一個數字間差別的情況下,學習什麼樣的表徵可以將一個數字從其他數字中區別出來。
單樣本學習的常用技術是學習一個嵌入空間,在這個空間中計算出兩個樣本表徵間的歐幾里德相似性,這能很好地計算出這兩個樣本是否屬於同一類。直觀地講,這需要學習分佈中類別間差異的內部維度(在我的樣本中,分佈在數字中),並學習如何將輸入壓縮和轉換成那些最相關的維度。
我發現記住這個問題是一個很有用的基礎,儘管不是學習如何總結存在於類別分佈中的碎片化信息和模式,而是學習存在於任務中的類的分佈規律,每一類都有自己的內部結構或目標。
如果要從最抽象開始,構造一個神經網絡元參數的等級,會有點像這樣:
通過使用超參數梯度下降,網絡從任務的全部分佈中學習到有用的表徵。MAML 和 Reptile 是有關於此的直接的好例子,分享層級結構的元學習是一種有趣的方法,這種方法可以通過主策略的控制學習到清晰的子策略作爲表徵。
網絡學習要優化梯度下降的參數。這些參數就像是學習率、動量以及權重之於自適應學習率算法。我們在此沿着修改學習算法本身的軌道修改參數,但是有侷限性。這就是 Learning to Learn By Gradient Descent by Gradient Descent 所做的。是的,這就是這篇文章真正的標題。
一個學習內部優化器的網絡,內部優化器本身就是一個網絡。也就是說,使用梯度下降更新神經優化器網絡參數使得網絡在整個項目中獲得很好的表現,但是在網絡中每個項目從輸入數據到輸出預測結果的映射都是由網絡指導的。這就是 RL² 和 A Simple Neural Attentive Meta Learner 起作用的原因。
爲了使這篇文章更簡明,我將主要敘述 1 和 3,以說明這個問題的兩個概念性的結局。
其他名稱的任務
另一個簡短的問題——我保證是最後一個——我希望澄清一個可能會造成困惑的話題。一般而言,在元學習的討論中,你會看到「任務分佈」的提法。你可能會注意到這個概念定義不明,而你的注意是對的。對於一個問題是一個任務還是多個任務中的一個分佈,人們似乎還沒有明確的標準。例如,我們應該將 ImageNet 視爲一個任務——目標識別——還是許多任務——識別狗是一個任務而識別貓是另一個任務呢?爲什麼將玩 Atari 遊戲視爲一個任務,而不是將遊戲的每一個等級作爲一個獨立任務的幾個任務?
我能得到的有:
「任務」的概念是用已經建立的數據集進行卷積,從而可以自然地將在一個數據集上進行學習認爲是單個任務
對於任何給定分佈的任務,這些任務之間的不同之處都是非常顯著的(例如,每一個學習振幅不同的正弦曲線的任務和每一個在玩不同 Atari 遊戲的任務之間的差別)
所以,這不僅僅是說「啊,這個方法可以推廣到這個任務分配的例子上,所以這是一個很好的指標,這個指標可以在任務中一些任意且不同的分佈上表現良好」。從方法角度上講,這當然不是方法有效的不好的證據,但我們確實需要用批判性思維考慮這種網絡要表現出多大的靈活性才能在所有任務中都能表現出色。
那些令人費解的動物命名的方法
在 2017 年早些時候,Chelsea Finn 及其來自 UC Berkeley 的團隊就有了叫做 MAML的方法。
MAML(Model Agnostic Meta Learning,與模型無關的元學習)參見:與模型無關的元學習,UC Berkeley 提出一種可推廣到各類任務的元學習方法。

如果你有心想要了解一下,請轉向本文的「MAML 的種類」部分。
在學習策略和學習先驗之間,這種方法更傾向於後者。這種網絡的目標在於訓練一個模型,給新任務一步梯度更新,就可以很好地歸納該任務。就像是僞代碼算法。
1. 初始化網絡參數 θ。
2. 在分佈任務 T 中選擇一些任務 t。從訓練集中取出 k 個樣本,在當前參數集所在位置執行一步梯度步驟,最終得到一組參數。
3. 用最後一組參數在測試集中測試評估模型性能。
4. 然後,取初始參數θ作爲任務 t 測試集性能的梯度。然後根據這一梯度更新參數。回到第一步,使用剛剛更新過的θ作爲這一步的初始θ值。
這是在做什麼?從抽象層面上講,這是在尋找參數空間中的一個點,就分佈任務中的許多任務而言,這個點是最接近好的泛化點的。你也可以認爲這迫使模型在探索參數空間時保留了一些不確定性和謹慎性。簡單說,一個認爲梯度能完全表示母體分佈的網絡,可能會進入一個損失特別低的區域,MAML 會做出更多激勵行爲來找到一個靠近多個峯頂端的區域,這些峯每一個的損失都很低。正是這種謹慎的激勵使 MAML 不會像一般通過少量來自新任務的樣本訓練的模型一樣過擬合。
2018 年的早些時候文獻中提出了一種叫做 Reptile 的更新方法。正如你可能從它的名字中猜出來的那樣——從更早的 MAML 中猜——Reptile 來自 MAML 的預述,但是找到了一種計算循環更新初始化參數的方法,這種方法的計算效率會更高。MAML 明確取出與初始化參數 θ 相關的測試集損失的梯度,Reptile 僅在每項任務中執行了 SGD 更新的幾步,然後用更新結束時的權重和初始權重的差異,作爲更新初始權重的梯度。
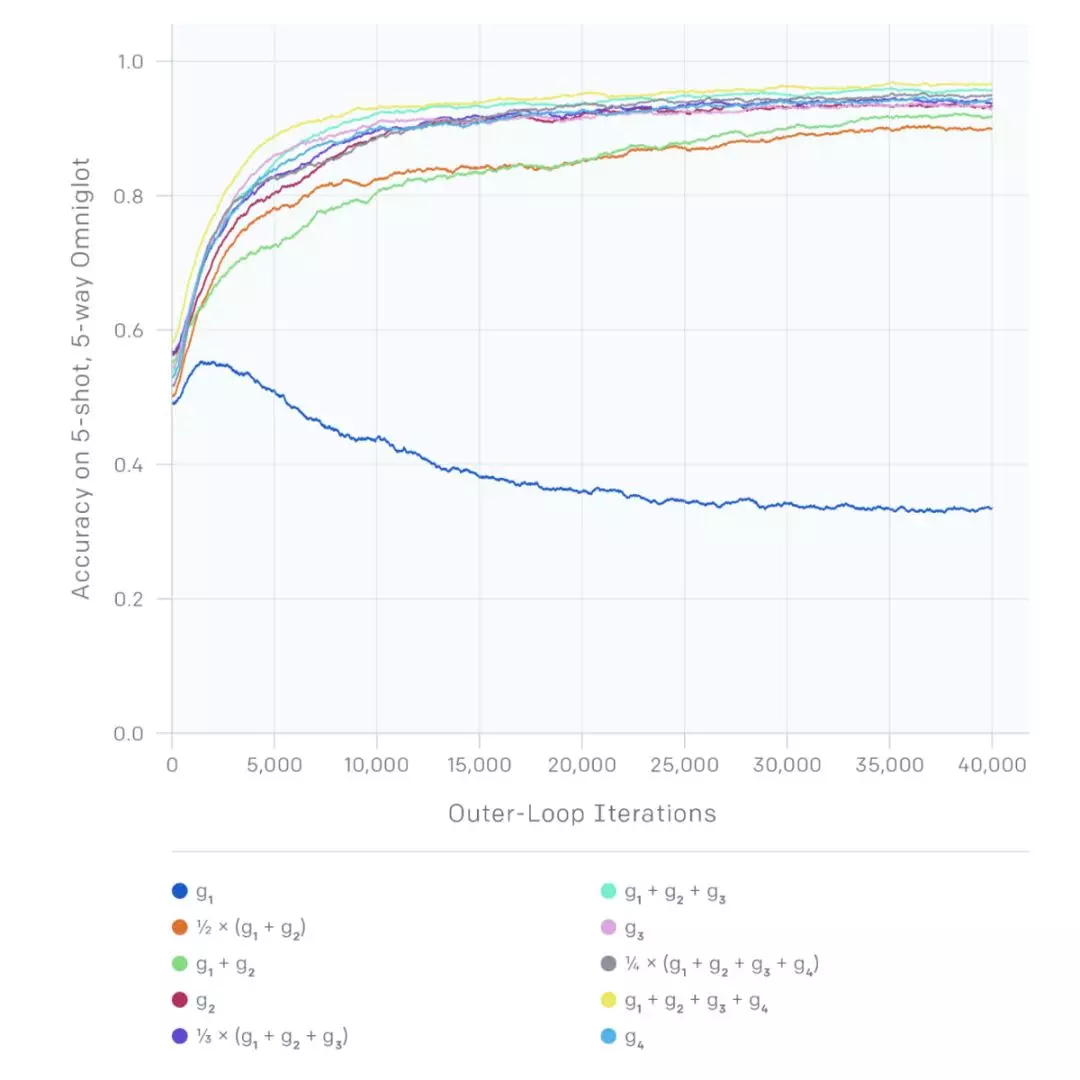
g_1 在此表示每個任務只執行一次梯度下降步驟得到的更新後的梯度。
這項工作從根本上講有一些奇怪——這看起來和將所有任務合併爲一個任務對模型進行訓練沒有任何不同。然而,作者提出,由於對每項任務都使用了 SGD 的多個步驟,每個任務損失函數的二次導數則被賦予影響力。爲了做到這一點,他們將更新分爲兩部分:
1. 任務會得到「聯合訓練損失」的結果,也就是說,你會得到用合併的任務作爲數據集訓練出來的結果。
2. SGD 小批次梯度都是接近的:也就是說,在通過小批次後,梯度下降的程度很低。
我選擇 MAML/Reptile 組作爲「學習先驗」的代表,因爲從理論上講,這個網絡通過對內部表徵進行學習,不僅有助於對任務的全部分佈進行分類,還可以使表徵與參數空間接近,從而使表徵得到廣泛應用。
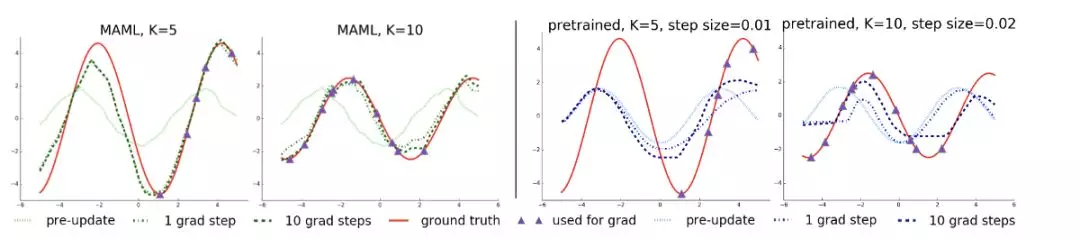
爲了對這個點進行分類,我們先看一下上圖。上圖對 MAML 和預訓練網絡進行比較,這兩個網絡都用一組由不同相位與振幅組成的正弦曲線迴歸任務訓練。在這個點上,兩者針對新的特定任務都進行了「微調」:紅色曲線所示。紫色三角代表少數梯度步驟中使用的數據點。與預訓練模型相比,MAML 學到了,正弦曲線具有周期性結構:在 K=5 時,它可以在沒有觀察到這一區域數據的情況下更快地將左邊的峯值移到正確的地方。儘管很難判斷我們的解釋是不是網絡的真正機制,但我們可以推斷 MAML 在算出兩個相關正弦曲線不同之處——相位和振幅——方面做得更好,那麼是如何從這些已給數據的表徵進行學習的呢?
網絡一路向下

對一些人來說,他們的想法是使用已知算法,例如梯度下降,來對全局先驗進行學習。但是誰說已經設計出來的算法就是最高效的呢?難道我們不能學到更好的方法嗎?
這就是 RL²(通過慢速強化學習進行快速強化學習)所採用的方法。這個模型的基礎結構式循環神經網絡(具體來說,是一個 LTSM 網絡)。因爲 RNN 可以儲存狀態信息,還可以給出不同輸出並將這些輸出作爲該狀態的函數,理論上講這就有可能學到任意可計算的算法:也就是說它們都具有圖靈完備的潛力。以此爲基礎,RL² 的作者構建了一個 RNN,每一個用於訓練 RNN 的「序列」都是一組具有特定 MDP(Markov Decision Process,馬爾科夫決策過程。從這個角度解釋,你只需將每次 MDP 看作環境中定義一系列可能行爲且通過這些行爲產生獎勵)的經驗集合。接着會在許多序列上訓練這個 RNN,像一般的 RNN 一樣,這是爲了對應多個不同的 MDP,可以對 RNN 的參數進行優化,可以使所有序列或試驗中產生的遺憾(regret)較低。遺憾(regret)是一個可以捕獲你一組事件中所有獎勵的指標,所以除了激勵網絡在試驗結束時得到更好的策略之外,它還可以激勵網絡更快地進行學習,因此會在低迴報政策中更少地使用探索性行爲。
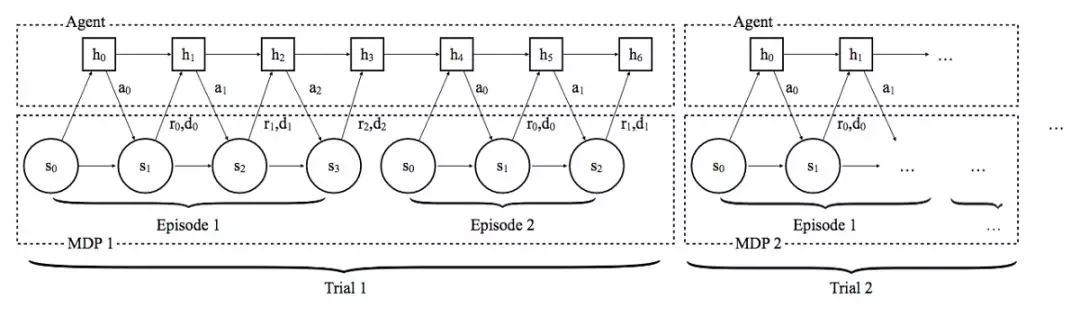
圖中顯示的是運行在多重試驗上的 RNN 的內部工作,對應多個不同的 MDP。
在試驗中的每一個點,網絡都會通過在多個任務和隱藏狀態的內容學習權重矩陣參數化函數,隱藏狀態的內容是作爲數據函數進行更新並充當一類動態參數集合。所以,RNN 學習的是如何更新隱藏狀態的權重。然後,在一個給定的任務中,隱藏狀態可以捕獲關於網絡確定性以及時間是用於探索還是利用的信息。作爲數據函數,它可以看得到特定任務。從這個意義上講,RNN 在學習一個可以決定如何能最好地探索空間、還可以更新其最好策略概念的算法,同時使該算法在任務的一組分佈上得到很好的效果。該作者對 RL² 的架構和對任務進行漸進優化的算法進行比較,RL² 的表現與其相當。
我們可以擴展這種方法嗎?
本文只是該領域一個非常簡要的介紹,我肯定遺漏了很多想法和概念。如果你需要更多(信息更加豐富)的看法,我高度推薦這篇 Chelsea Finn 的博客,此人也是 MAML 論文的第一作者。
在這幾周的過程中,我試着對這篇文章從概念上進行壓縮,並試着對這篇文章進行理解,在這一過程中我產生了一系列問題:
這些方法該如何應用於更多樣的任務?這些文章大多是在多樣性較低的任務分佈中從概念上進行了驗證:參數不同的正弦曲線、參數不同的躲避老虎機、不同語言的字符識別。對我而言,在這些任務上做得好不代表在複雜程度不同、模式不同的任務上也可以有很好的表現,例如圖像識別、問答和邏輯問題結合的任務。然而,人類的大腦確實從這些高度不同的任務集中形成了先驗性,可以在不同的任務中來回傳遞關於這個世界的信息。我的主要問題在於:這些方法在這些更多樣的任務中是否會像宣傳的一樣,只要你拋出更多單元進行計算就可以嗎?或在任務多樣性曲線上的一些點是否存在非線性效應,這樣在這些多樣性較低的任務中起作用的方法在高多樣性的任務中就不會起作用了。
這些方法依賴的計算量有多大?這些文章中的大部分都旨在小而簡單的數據集中進行操作的部分原因是,每當你訓練一次,這一次就包括一個內部循環,這個內部循環則包含(有效地)用元參數效果相關的數據點訓練模型,以及測試,這都是需要耗費相當大時間和計算量的。考慮到近期摩爾定律漸漸失效,在 Google 以外的地方對這些方法進行應用研究的可能性有多大?每個針對困難問題的內部循環迭代可能在 GPU 上運行數百個小時,在哪能有這樣的條件呢?
這些方法與尋找能清晰對這個世界的先驗進行編碼的想法相比又如何呢?在人類世界中一個價值極高的工具就是語言。從機器學習方面而言,是將高度壓縮的信息嵌入我們知道該如何轉換概念的空間中,然後我們纔可以將這些信息從一個人傳遞給另一個人。沒人可以僅從自己的經驗中就提取出這些信息,所以除非我們找出如何做出與學習算法相似的事,否則我懷疑我們是否真的可以通過整合這個世界上的知識建立模型,從而解決問題。

原文鏈接:https://towardsdatascience.com/learning-about-algorithms-that-learn-to-learn-9022f2fa3dd5