剛剛,谷歌開源了語義圖像分割模型 DeepLab-v3+,DeepLab-v3+結合了空間金字塔池化模塊和編碼器-解碼器結構的優勢,是自三年前的 DeepLab 以來的最新、性能最優的版本。
GitHub 地址:https://github.com/tensorflow/models/tree/master/research/deeplab
語義圖像分割任務是指將語義標籤(例如「道路」、「天空」、「人」、「狗」)分配給圖像中的每一個像素,這種技術有很多新應用,例如,Pixel 2 和 Pixel 2 XL 智能手機中肖像模式的合成淺景深效應,以及移動設備的實時語義分割等。分配這些語義標籤的時候需要精準定位目標的輪廓,因此相比其他的視覺實體識別任務(如圖像級分類或邊界框級檢測等),該任務需要更高的定位準確率。

今天,谷歌開源了其最新、性能最優的語義圖像分割模型 DeepLab-v3+ [1],該模型使用 TensorFlow 實現。DeepLab-v3+ 模型建立在一種強大的卷積神經網絡主幹架構上 [2,3],以得到最準確的結果,該模型適用於服務器端的部署。此外,谷歌還分享了他們的 TensorFlow 模型訓練和評估代碼,以及在 Pascal VOC 2012 和 Cityscapes 基準語義分割任務上預訓練的模型。
自三年前谷歌發佈第一個版本的 DeepLab 模型 [4] 以來,CNN 特徵提取器、目標尺度建模技術、語境信息處理、模型訓練流程、深度學習硬件和軟件的不斷改進和優化,促使該模型升級到了 DeepLab-v2 [5] 和 DeepLab-v3 [6]。谷歌通過添加一個簡單而有效的解碼器模塊以精煉分割結果(尤其是在目標邊界處),將 DeepLab-v3 擴展爲 DeepLab-v3+。他們還進一步將深度可分卷積(depthwise separable convolution)應用到金字塔型的空洞池化(Atrous Spatial Pyramid Pooling,ASPP)[5, 6] 和解碼器模塊上,以得到更快更強大的語義分割編碼器-解碼器網絡。
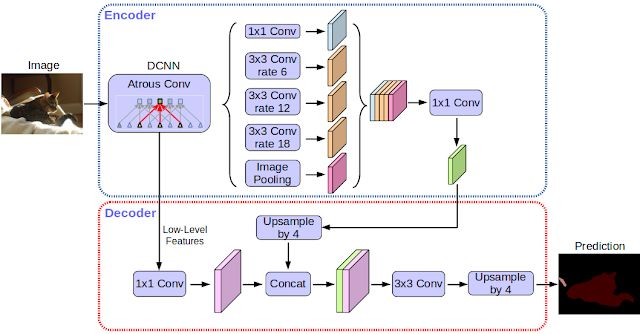
現代語義圖像分割系統都是建立在卷積神經網絡之上,並達到了五年前無法想象的準確率,這得歸功於方法、硬件和數據集的優化。谷歌希望通過和社區共享該系統,學界和業界能更容易地復現和提升當前最優系統,在新的數據集上訓練模型,以及爲該技術開發新的應用。
論文:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation

論文鏈接:https://arxiv.org/abs/1802.02611
摘要:深度神經網絡使用空間金字塔池化模塊或編碼器-解碼器結構執行語義分割任務。前者通過在多個 rate、多個有效視野上用濾波器探測輸入特徵或執行池化操作,來編碼多尺度的上下文信息;後者通過逐漸恢復空間信息來捕捉更加精細的目標邊界。在這項研究中,我們將二者的優勢結合起來。具體來說,我們通過添加一個簡單有效的解碼器模塊以精煉分割結果(尤其是目標邊界),將 DeepLab-v3 擴展爲本文提出的新模型 DeepLab-v3+。我們進一步探索了 Xception 模型,並將深度可分卷積應用到金字塔型的空洞池化(ASPP)和解碼器模塊上,以得到更快更強大的編碼器-解碼器網絡。我們在 PASCAL VOC 2012 語義圖像分割數據集上證明了該模型的有效性,在沒有任何後處理的情況下該模型達到了 89% 的準確率。
參考閱讀:
資源 | 從全連接層到大型卷積核:深度學習語義分割全指南
原文鏈接:https://research.googleblog.com/2018/03/semantic-image-segmentation-with.html