作者:Slav Ivanov
參與:李澤南、路雪、劉曉坤
本文作者 slav Ivanov 在今年早些時候曾介紹過如何用 1700 美元預算搭建深度學習機器(參見:教程 | 從硬件配置、軟件安裝到基準測試,1700 美元深度學習機器構建指南)。最近,英偉達在消費級 GPU 領域又推出了 GTX 1070 Ti,如果現在想要組裝一臺深度學習機器,我們用哪塊 GPU 最好呢?本文將詳細解答這一問題。
即將進入 2018 年,隨着硬件的更新換代,越來越多的機器學習從業者又開始面臨選擇 GPU 的難題。正如我們所知,機器學習的成功與否很大程度上取決於硬件的承載能力。在今年 5 月,我在組裝自己的深度學習機器時對市面上的所有 GPU 進行了評測。而在本文中,我們將更加深入地探討:
爲什麼深度學習需要使用 GPU
GPU 的哪種性能指標最爲重要
選購 GPU 時有哪些坑需要避免
性價比
每個價位的最佳選擇
GPU + 深度學習
深度學習(DL)是機器學習(ML)的一個分支。深度學習使用神經網絡來解決問題。神經網絡的優點之一是自行尋找數據(特徵)模式。這和以前告訴算法需要找什麼不一樣。但是,通常這意味着該模型從空白狀態開始(除非使用遷移學習)。爲了從頭捕捉數據的本質/模式,神經網絡需要處理大量信息。通常有兩種處理方式:使用 CPU 或 GPU。
計算機的主要計算模塊是中央處理器(CPU),CPU 的設計目的是在少量數據上執行快速計算。在 CPU 上添加數倍的數字非常快,但是在大量數據上進行計算就會很慢。如,幾十、幾百或幾千次矩陣乘法。在表象背後,深度學習多由矩陣乘法之類的操作組成。
有趣的是,3D 電子遊戲同樣依賴這些操作來渲染那些美麗的風景。因此,GPU 的作用被開發出來,它們可以使用數千個核心處理大量並行計算。此外,它們還有大量內存帶寬處理數據。這使得 GPU 成爲進行 DL 的完美硬件。至少,在用於機器學習的 ASIC 如谷歌的 TPU 投入市場之前,我們還沒有其他更好的選擇。
總之,儘管使用 CPU 進行深度學習從技術上是可行的,想獲得真實的結果你就應該使用 GPU。
對我來說,選擇一個強大的圖形處理器最重要的理由是節省時間和開發原型模型。網絡訓練速度加快,反饋時間就會縮短。這樣我就可以更輕鬆地將模型假設和結果之間建立聯繫。
選擇 GPU 的時候,我們在選擇什麼?
和深度學習相關的主要 GPU 性能指標如下:
內存帶寬:GPU 處理大量數據的能力,是最重要的性能指標。
處理能力:表示 GPU 處理數據的速度,我們將其量化爲 CUDA 核心數量和每一個核心的頻率的乘積。
顯存大小:一次性加載到顯卡上的數據量。運行計算機視覺模型時,顯存越大越好,特別是如果你想參加 CV Kaggle 競賽的話。對於自然語言處理和數據分類,顯存沒有那麼重要。
常見問題
多 GPU(SLI/交火)
選擇多 GPU 有兩個理由:需要並行訓練多個模型,或者對單個模型進行分佈式訓練。
並行訓練多個模型是一種測試不同原型和超參數的技術,可縮短反饋週期,你可以同時進行多項嘗試。
分佈式訓練,或在多個顯卡上訓練單個模型的效率較低,但這種方式確實越來越受人們的歡迎。現在,使用 TensorFlow、Keras(通過 Horovod)、CNTK 和 PyTorch 可以讓我們輕易地做到分佈式訓練。這些分佈式訓練庫幾乎都可以隨 GPU 數量達成線性的性能提升。例如,使用兩個 GPU 可以獲得 1.8 倍的訓練速度。
PCIe 通道:使用多顯卡時需要注意,必須具備將數據饋送到顯卡的能力。爲此,每一個 GPU 必須有 16 個 PCIe 通道用於數據傳輸。Tim Dettmers 指出,使用兩個有 8 個 PCIe 通道的 GPU,性能應該僅降低「0—10%」。
對於單個 GPU 而言,任何桌面級處理器和芯片組如 Intel i5 7500 和 Asus TUF Z270 需要使用 16 個通道。
然而,對於雙 GPU,你可以使用 8x/8x 通道,或者使用一個處理器和支持 32PCIe 通道的主板。32 個通道超出了桌面級 CPU 的處理能力。使用 Intel Xeon 組合 MSI—X99A SLI PLUS 是可行的方案。
對於 3 個或 4 個 GPU,每個 GPU 可使用 8x 通道,組合支持 24 到 32 個 PCIe 通道的 Xeon。
如果需要使用 3 到 4 個有 16 個 PCIe 通道的 GPU,你得有一個怪獸級處理器。例如 AMD ThreadRipper(64 個通道)和相應的主板。
總之,GPU 越多,需要越快的處理器,還需要有更快的數據讀取能力的硬盤。
英偉達還是 AMD
英偉達已經關注深度學習有一段時間,並取得了領先優勢。他們的 CUDA 工具包具備紮實的技術水平,可用於所有主要的深度學習框架——TensorFlow、PyTorch、Caffe、CNTK 等。但截至目前,這些框架都不能在 OpenCL(運行於 AMD GPU)上工作。由於市面上的 AMD GPU 便宜得多,我希望這些框架對 OpenCL 的支持能儘快實現。而且,一些 AMD 卡還支持半精度計算,從而能將性能和顯存大小加倍。
今年夏天,AMD 還發布了 ROCm 平臺提供深度學習支持,它同樣適用於主流深度學習庫(如 PyTorch、TensorFlow、MxNet 和 CNTK)。目前,ROCm 仍然在不斷開發中。
然而目前而言,如果想做深度學習的話,還是選擇英偉達吧。
其它硬件
你的 GPU 還需要以下這些硬件才能正常運行:
硬盤:首先需要從硬盤讀取數據,我推薦使用固態硬盤,但機械硬盤也可以。
CPU:深度學習任務有時需要用 CPU 解碼數據(例如,jpeg 圖片)。幸運的是,任何中端現代處理器都能做得不錯。
主板:數據需要通過主板傳輸到 GPU 上。單顯卡可以使用幾乎任何芯片組都可以使用。
RAM:一般推薦內存的大小至少和顯存一樣大,但有更多的內存確實在某些場景是非常有幫助的,例如我們希望將整個數據集保存在內存中。
電源:一般來說我們需要爲 CPU 和 GPU 提供足夠的電源,至少需要超過額定功率 100 瓦。
我們總體上需要 500 到 1000 美元來獲得以上設備,當然如果買一個二手工作站會更加省錢。
GPU 性能對比(2017 年 11 月)
下面是截止目前英偉達產品線主要 GPU 的性能對比,每個 GPU 的 RAM 或內存帶寬等信息都展示在圖表中。注意 Titan XP 和 GTX 1080 Ti 儘管價格相差非常多,但它們的性能卻非常相近。
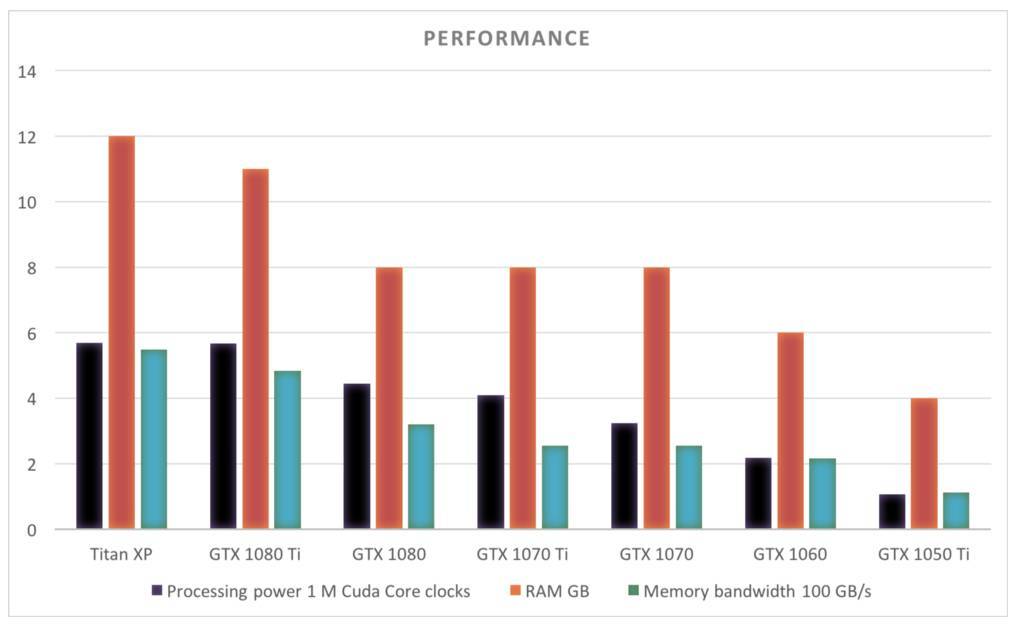
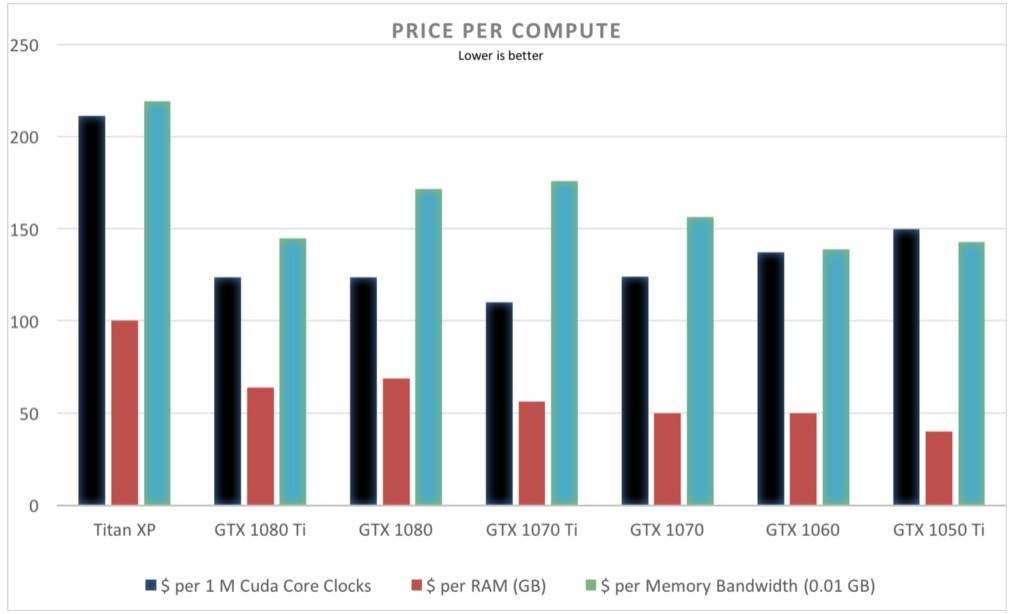
價格對比表明 GTX 1080 Ti、GTX 1070 和 GTX 1060 的性價比較高。所有GPU都是幾乎相同的比值,除了 Titan XP。
Titan XP
參數:
顯存(VRAM):12 GB
內存帶寬:547.7 GB/s
處理器:3840 個 CUDA 核心 @ 1480 MHz(約 5.49 億 CUDA 核心頻率)
英偉達官網價格:9700 元
Titan XP 是目前英偉達消費級顯卡的旗艦產品,正如性能指標所述,12GB 的內存宣示着它並不是爲大多數人準備的,只有當你知道爲什麼需要它的時候,它才會位列推薦列表。
一塊 Titan XP 的價格可以讓你買到兩塊 GTX 1080,而那意味着強大的算力和 16GB 的顯存。
GTX 1080 Ti
參數:
顯存(VRAM):11 GB
內存帶寬:484 GB/s
處理器:3584 個 CUDA 核心 @ 1582 MHz(約 5.67 億 CUDA 核心頻率)
英偉達官網價格:4600 元
這塊顯卡正是我目前正在使用的型號,它是一個完美的高端選項,擁有大容量顯存和高吞吐量,物有所值。
如果資金允許,它是一個很好的選擇。GTX 1080 Ti 可以讓你完成計算機視覺任務,並在 Kaggle 競賽中保持強勢。
GTX 1080
參數:
顯存(VRAM):8 GB
內存帶寬:320 GB/s
處理器:2560 個 CUDA 核心 @ 1733 MHz(約 4.44 億 CUDA 核心頻率)
英偉達官網價格:3600 元
作爲目前英偉達產品線裏的中高端顯卡,GTX 1080 的官方價格從 1080 Ti 的 700 美元降到了 550 美元。8 GB 的內存對於計算機視覺任務來說夠用了。大多數 Kaggle 上的人都在使用這款顯卡。
GTX 1070 Ti
參數:
顯存(VRAM):8 GB
內存帶寬:256 GB/s
處理器:2432 個 CUDA 核心 @ 1683 MHz(約 4.09 億 CUDA 核心頻率)
英偉達官網價格:3000 元
11 月 2 日推出的 GTX 1070 Ti 是英偉達產品線上最新的顯卡。如果你覺得 GTX 1080 超出了預算,1070 Ti 可以爲你提供同樣大的 8 GB 顯存,以及大約 80% 的性能,價格也打了八折,看起來不錯。
GTX 1070
參數:
顯存(VRAM):8 GB
內存帶寬:256 GB/s
處理器:1920 個 CUDA 核心 @ 1683 MHz(約 3.23 億 CUDA 核心頻率)
英偉達官網價格:2700 元
現在很難買到這款 GPU 了,因爲它們主要用於虛擬貨幣挖礦。它的顯存配得上這個價位,就是速度有些慢。如果你能用較便宜的價格買到一兩個二手的,那就下手吧。
GTX 1060(6 GB 版本)
參數:
顯存(VRAM):6 GB
內存帶寬:216 GB/s
處理器:1280 個 CUDA 核心 @ 1708 MHz(約 2.19 億 CUDA 核心頻率)
英偉達官網價格:2000 元
相對來說比較便宜,但是 6 GB 顯存對於深度學習任務可能不夠用。如果你要做計算機視覺,那麼這可能是最低配置。如果做 NLP 和分類數據模型,這款還可以。
GTX 1050 Ti
參數:
顯存(VRAM):4 GB
內存帶寬:112 GB/s
處理器:768 個 CUDA 核心 @ 1392 MHz(約 1.07 億 CUDA 核心頻率)
英偉達官網價格:1060 元
這是一款入門級 GPU。如果你不確定是否要做深度學習,那麼選擇這款不用花費太多錢就可以體驗一下。
值得注意的問題
上代旗艦 Titan X Pascal 曾是英偉達最好的消費級 GPU 產品,而 GTX 1080 Ti 的出現淘汰了 Titan X Pascal,前者與後者有同樣的參數,但 1080 Ti 便宜了 40%。
英偉達還擁有一個面向專業市場的 Tesla GPU 產品線,其中包括 K40、K80、P100 和其他型號。雖然你或許很少能夠接觸到,但你可能已經通過 Amazon Web Services、谷歌雲平臺或其他雲供應商在使用這些 GPU 了。
我在之前的文章中對 GTX 1080 Ti 和 K40 進行了一些基準測試。1080 的速度是 K40 的 5 倍,是 K80 的 2.5 倍。K40 有 12 GB 顯存,K80 有 24 GB 的顯存。
理論上,P100 和 GTX 1080 Ti 應該性能差不多。但是,之前的對比(https://www.reddit.com/r/NiceHash/comments/77uxe0/gtx_1080ti_vs_nvidia_tesla_p100_xpost_from/)發現 P100 在每個基準中都比較落後。
K40 售價超過了 13,000元,K80 售價超過 20,000 元,P100 售價約 30,000 元。它們的市場正被英偉達自家的桌面級 GPU 無情吞噬。顯然,按照現在的情況,我不推薦你去購買它們。
一句話推薦
如果你不設定自己的預算,裝配電腦就成了一件困難的事。在這裏,我將給出不同預算區間下 GPU 的最佳選擇。
4600-6000 元區間:首推 GTX 1080 Ti。如果你需要雙顯卡 SLI,請購買兩塊 GTX 1070(可能不太好找)或兩塊 GTX 1070 Ti。Kaggle 排行榜,我來了!
2600-4600 元區間:可選 GTX 1080 或 GTX 1070 Ti。如果你真的需要 SLI 的話或許兩塊 GTX 1060 也是可以的,但請注意它們的 6GB 內存可能會不夠用。
2000-2600 元區間:GTX 1060 可以讓你入門深度學習,如果你可以找到成色不錯的 GTX 1070 那就更好了。
2000 元以下:在這個區間內,GTX 1050 Ti 是最佳選擇,但如果你真的想做深度學習,請加錢上 GTX 1060。
深度學習有望改變我們生活中的很多方面。然而,構建深度學習系統需要強大的硬件,希望本文能夠對你裝配自己的深度學習機器有所幫助。
原文地址:https://blog.slavv.com/picking-a-gpu-for-deep-learning-3d4795c273b9