選自南京大學
作者:張騰、周志華
在這篇題爲《Optimal Margin Distribution Clustering》的論文中,南京大學周志華教授、張騰博士提出了一種新方法——用於聚類的最優間隔分佈機(Optimal margin Distribution Machine for Clustering/ODMC),該方法可以用於聚類並同時獲得最優間隔分佈。在 UCI 數據集上的大量實驗表明 ODMC 顯著地優於對比的方法,從而證明了最優間隔分佈學習的優越性。
聚類是機器學習、數據挖掘和模式識別中的一個重要研究領域,其目標是分類相似的數據點。它催生出了包括信息檢索、計算機視覺、生物信息學等在內的大量新研究,並且不同的聚類算法已被提出超過十年(Jain and Dubes 1988; Xu and Wunsch 2005; Jain 2010)。
最近有一種稱爲最大間隔聚類(MMC/maximum margin clustering)的方法,它基於支持向量機的大間隔啓發(Cortes and Vapnik 1995; Vapnik 1995)。對於好的聚類方法而言,當標籤分配到不同簇時,SVM 在該數據上可以得到最大化的最小間隔。由於形式化成的極大極小問題涉及用集合 {+1, −1} 標記每一個實例,它也就不再是一個凸優化問題,而是一個更難處理的混合整數規劃(mixed-integer programming)。從那時起,爲解決這一問題做了大量努力,這些努力可被分爲兩類。第一類通過不同的凸鬆弛技術(Xu et al. 2005)首次將其鬆弛爲凸半定規劃(semi-definite programming/SDP),其中一種帶有線性約束的正半定矩陣被用於逼近標籤外積矩陣。很快,Valizadegan 和 Jin (2006) 引入一個新的形式化,其變量數明顯減少,儘管它依然是一個 SDP 問題。最後,Li et al.(2009; 2013)提出一個比 SDP 更緊緻的極大極小鬆弛,並可通過迭代地生成最違反的標籤,然後藉助多核學習整合它們而被解決。
第二類通過非凸優化的變量直接優化原始的問題。這些案例包括了交替優化(Zhang, Tsang, and Kwok 2007; 2009),其中通過連續地尋找標籤和優化一個支持向量迴歸(SVR)進行聚類;以及 CCCP(Zhao, Wang, and Zhang 2008; Wang, Zhao, and Zhang 2010),其中非凸目標函數或約束被表達爲兩個凸函數之間的差值;後者進一步替換成其線性近似,因此完全是凸的。此外,很多研究嘗試將 MMC 擴展到更加普遍的學習環境。例如,Zhou 等人 2013 年假設數據具有隱變量並開發了 LMMC 框架。Niu 等人 2013 年的研究提出了 MMC 的另一種實現,稱爲最大容量聚類(maximum volume clustering,MVC),其在理論的意義上更重要。在 2016 年,MMC 的增量版本也被提出(Vijaya Saradhi and Charly Abraham 2016)。
上述的 MMC 方法全部基於大間隔理論,即嘗試最大化訓練實例的最小間隔。然而,間隔理論的近年研究(Gao and Zhou 2013)表明最小間隔的最大化並不必然導致更好的性能,而優化間隔分佈纔是關鍵。受此啓發,Zhang 和 Zhou (2014; 2016; 2017) 提出了最優間隔分佈機(optimal margin distribution machine,ODM),相比基於大間隔的方法可以獲得更好的泛化性能。之後,Zhou 和 Zhou(2016)將該思想擴展爲可利用無標籤數據和控制不均衡誤分類代價的方法。最優間隔分佈學習的成功預示着在 MMC 方法上還存在很大的提升空間。
在本文中,作者提出了一種新的方法——ODMC(Optimal margin Distribution Machine for Clustering,用於聚類的最優間隔分佈機),該方法可以用於聚類並同時獲得最優間隔分佈。特別地,他們利用一階和二階統計量(即間隔均值和方差)描述間隔分佈,然後應用 Li 等人 2009 年提出的極小極大凸鬆弛法(已證明比 SDP 鬆弛法更嚴格)以獲得凸形式化(convex reformulation)。作者擴展了隨機鏡像下降法(stochastic mirror descent method)以求解因而產生的極小極大問題,在實際應用中可以快速地收斂。此外,我們理論上證明了 ODMC 與當前最佳的割平面算法有相同的收斂速率,但每次迭代的計算消耗大大降低,因此我們的方法相比已有的方法有更好的可擴展性。在 UCI 數據集上的大量實驗表明 ODMC 顯著地優於對比的方法,從而證明了最優間隔分佈學習的優越性。
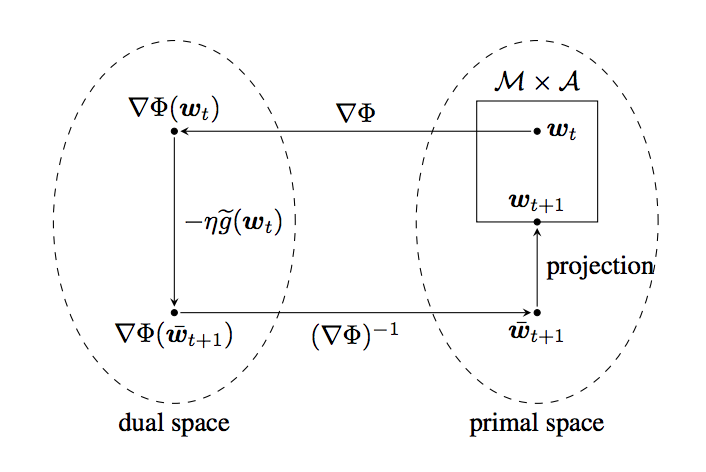
圖 1:隨機鏡像下降方法的一次迭代的圖示。

算法 1:用於 ODMC 的隨機鏡像下降。
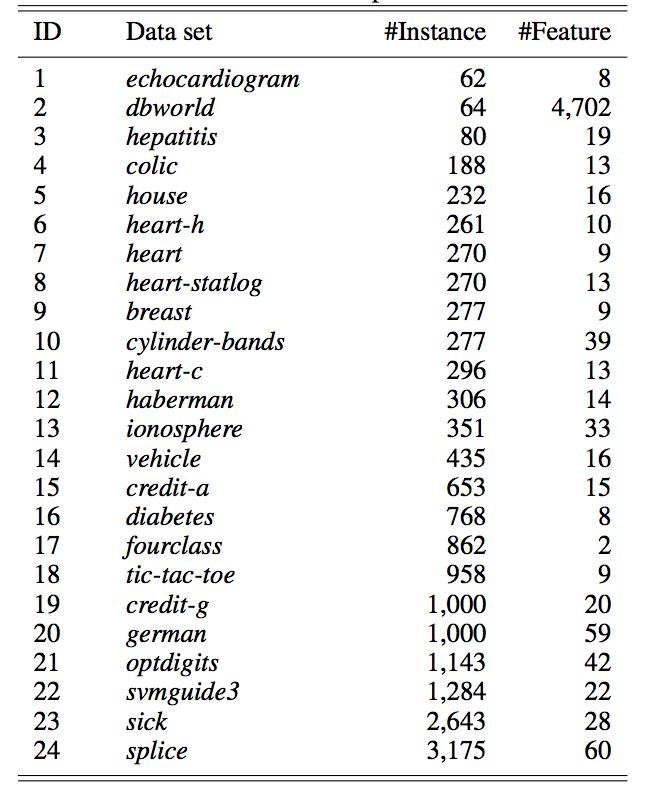
表 1:實驗數據集的統計。
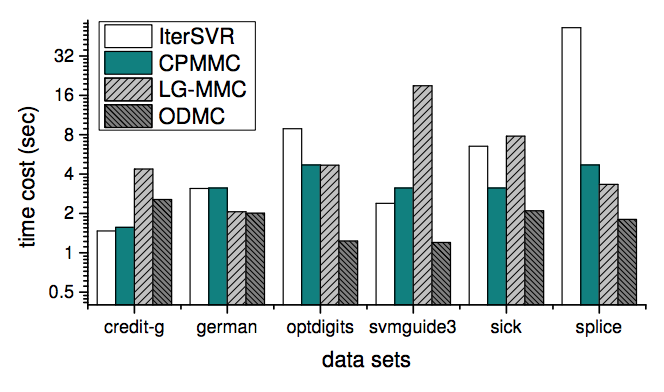
圖 2:IterSVR、CPMMC、LG-MMC、ODMC 的單次迭代的平均時間消耗。
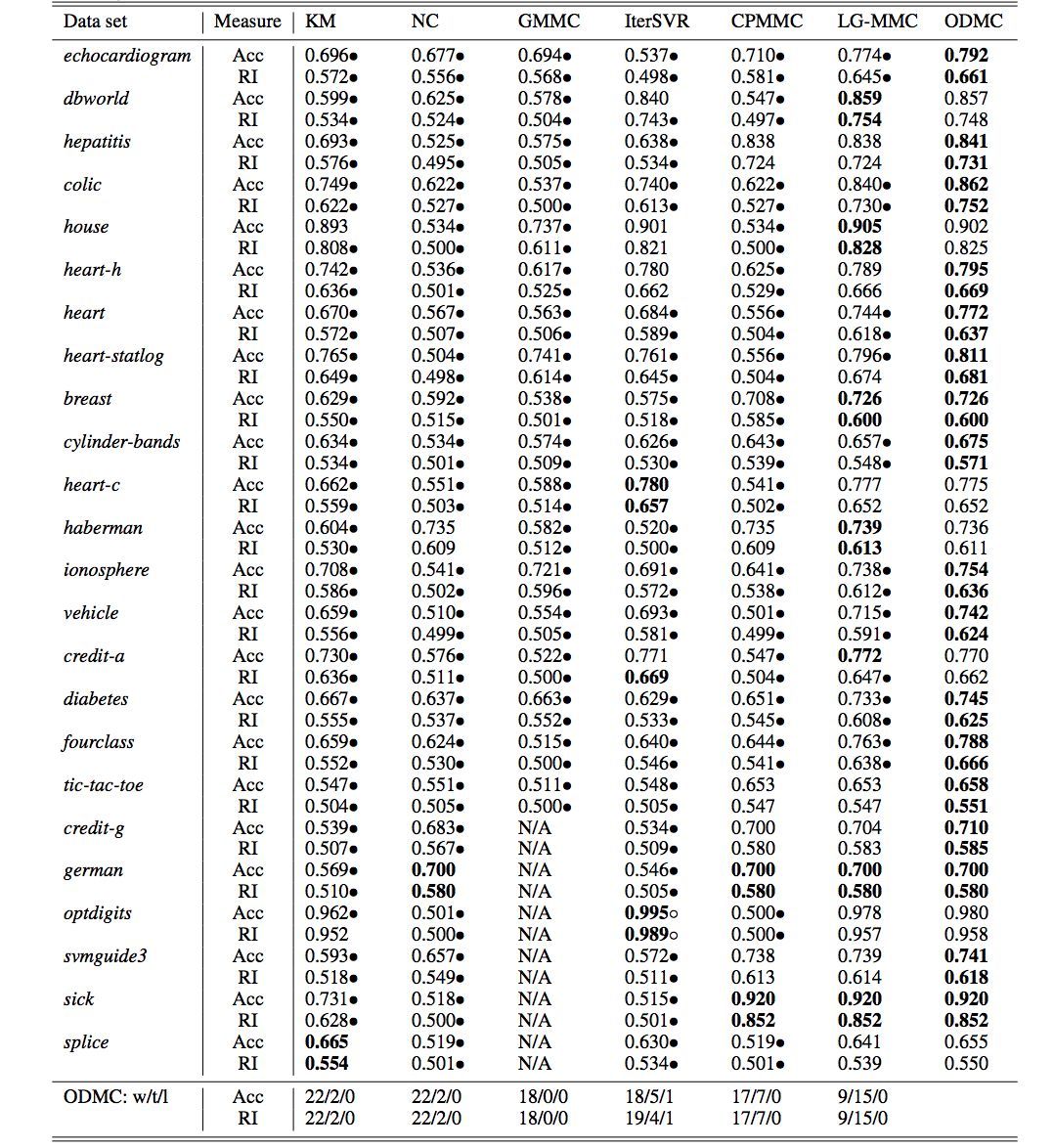
表 2:在 24 個 UCI 數據集上的聚類準確率(Acc)和 Rand Index(RI)的對比。粗體表示在該數據集上的最佳性能結果。黑點表示 ODMC 方法顯著地優於對比的方法(配對 t-檢驗在 95% 的顯著性水平)。最後兩行總結了 ODMC 相對其它方法的優/平/劣的數量。GMMC 在某些數據集上無法在兩天內返回結果。
下一步工作
在未來,作者將應用重要性採樣以進一步加速 ODMC 方法,並將其擴展到其它的學習環境,即半監督學習。
論文:Optimal Margin Distribution Clustering
論文鏈接:https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/aaai18odmc.pdf
最大間隔聚類(Maximum margin clustering,MMC)基於支持向量機(SVM)的大間隔啓發,相比傳統的聚類方法有更高的準確率。可以直覺地理解爲,對於一個足夠好的聚類方法,當給不同的聚類分配標籤時,SVM 可以在該數據上得到很大的最小間隔。然而,最近的研究揭示出最小間隔的最大化並不必然導致更好的性能,而優化間隔分佈纔是關鍵。在本文中,我們提出了一種新的方法——用於聚類的最優間隔分佈機(Optimal margin Distribution Machine for Clustering,ODMC),該方法可以用於聚類並同時獲得最優間隔分佈。特別地,我們利用一階和二階統計量(即間隔平均和方差)描述間隔分佈,並擴展了一種隨機鏡像下降法(stochastic mirror descent method)以求解因而產生的極小極大問題。此外,我們理論地證明了 ODMC 結合當前最佳的割平面(cutting plane)算法能得到相同的收斂速率,但每次迭代的計算消耗大大降低,因此我們的方法相比已有的方法有更好的可擴展性。在 UCI 數據集上的大量實驗表明 ODMC 顯著地優於對比的方法,從而證明了最優間隔分佈學習的優越性。