雷鋒網(公衆號:雷鋒網)按:本文內容來自塗圖 CTO 邱彥林在硬創公開課的分享,在未改變原意的基礎上進行了編輯整理。
幾年前圖片美顏教育了市場,到了直播時代,美顏同樣成爲直播平臺的標配。女主播要是在直播中不能自動美顏,那隻能靠更精緻的妝容來補,而實時直播美顏技術恰好解決了這個問題。
目前最新的美顏技術已經發展到了 2.0 階段,打個比方,如果美顏 1.0 只是化妝(磨皮、祛痘、膚色調整)的話,美顏 2.0 基本就能達到整容的效果——把眼睛變大,把圓臉變成瓜子臉。而實現這一效果的基礎就是人臉識別。
硬創公開課特邀專攻直播美顏的塗圖 CTO 邱彥林爲大家講述 《解密 AI 在直播美顏中起到哪些你看不到的作用》。

邱彥林:塗圖 CTO,專注於圖像技術,以及機器學習在圖像處理中的實際應用。國內最早一批 Flash 開發人員,曾出版 2 本 Flash 中文技術書籍,擅長程序架構設計。
美顏中最常見的祛痘、磨皮技術原理是什麼樣的?
從圖像處理的角度看,什麼是「痘」和「斑」?
一張圖像可以看作是一個二維的數據集合,其中每個元素都是一個像素點。如果將這些數據用幾何的方式來呈現出來,「痘」就是和周圍點差異較大的點。在圖像處理領域,這個差異是通過灰度值來衡量的灰度,也叫「亮度」。灰度圖,也就是黑白圖。將彩色圖轉換爲灰度圖,圖像的關鍵特徵不會丟失。
事實上,人的眼睛在觀察物體時,首先注意的是物體的邊緣。而在一張圖像裏面,邊緣,即與周邊灰度差異較大的點。類似的,「痘」也是與周邊點的灰度差異較大的點。相比色彩,人的眼睛對灰度更敏感。這也是爲什麼對視頻進行壓縮的時候,會偏向於丟棄色彩部分的數據,而儘量保留亮度數據。
磨皮祛痘,就是要平滑點與點之間的灰度差異,同時還要保持皮膚原有的一些細節。所以,美顏一般選擇邊界保持類平滑濾波算法。
直播美顏(動態)和圖片美顏(靜態)的區別在哪里?動態美顏要解決哪些技術難題?
最重要的區別在於:直播美顏要求實時處理,而靜態的圖像處理對實時性沒有要求,比如最近比較火的 Prisma,大家會發現處理一張圖像的速度可能需要 1~2 分鐘,甚至更長。
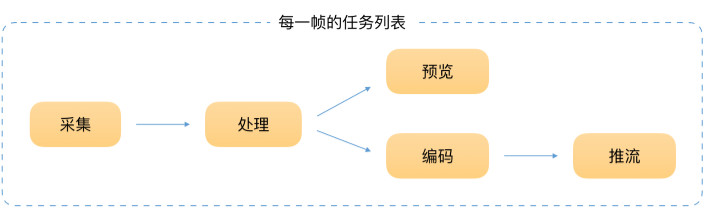
直播的實時性,最直接的體現就是在很短的時間內,完成一系列任務。所以直播中的美顏,對性能有很高的要求,無法使用特別複雜的算法。我們只能在算法和美顏效果之間找個平衡點。
在圖片處理應用中,沒有實時性的要求,所以對算法沒有什麼限制。只要能實現好的效果,再複雜的算法也可以用。
在第一個問題中,我提到了邊界保持類平滑濾波算法。這類算法有很多種,但在直播中一般均選擇雙邊濾波算法。這個算法性能高,效果也比較好,非常適合直播場景。除了磨皮算法外,調整皮膚膚色也是美顏的一個關鍵環節。關於調整膚色:一方面實現美白、紅潤的效果;另一方面則通過控制膚色,可以弱化「痘」和「斑」等,因爲磨皮算法只能在一定程度上消除噪點。調整膚色個環節,還能夠讓設計人員參與進來,來設計出更符合我們審美觀的效果來。
如何解決美顏後畫面像素變差的問題,可通過什什麼辦法在保證美顏效果和畫質之間的平衡?
從技術上講,美顏和畫質沒有關係。直播的畫質由主播端的輸出碼率決定,碼率越高,畫質越好,反之越差。 一般來說,在直播應用中,主播端輸出的碼率是固定的,或者說限制在一定範圍內。如果網絡情況好,輸出的碼率高,反之則低。目前主流的直播平臺都採用 RTMP 協議,採用其它技術比如 webRTC。此外直播畫質和直播平臺的穩定性也有一定關係。
如何實現直播時添加臉部貼圖,甚至實時整容:如把眼睛變大,把圓臉變成瓜子臉?
這類效果的核心是人臉識別技術。在直播時,從相機採集到每一幀的畫面,然後進行人臉識別,再標示出關鍵點的位置,結合圖像技術得到最終的效果。
我先深入講下人臉識別,目前在人臉識別領域可分爲機器學習與深度學習兩類方案。
機器學習方案:
機器學習識別物體是基於像素特徵的我們會蒐集大量的圖像素材,再選擇一個算法,使用這個算法來解析數據、從中學習,然後對真實世界中的事件做出決策和預測。
深度學習方案:
深度學習與機器學習不同的是,它模擬我們人類自己去識別人臉的思路。比如,神經學家發現了我們人類在認識一個東西、觀察一個東西的時候,邊緣檢測類的神經元先反應比較大,也就是說我們看物體的時候永遠都是先觀察到邊緣。就這樣,經過科學家大量的觀察與實驗,總結出人眼識別的核心模式是基於特殊層級的抓取,從一個簡單的層級到一個複雜的層級,這個層級的轉變是有一個抽象迭代的過程的。
深度學習就模擬了我們人類去觀測物體這樣一種方式,首先拿到海量數據,拿到以後纔有海量樣本做訓練,抓取到核心的特徵建立一個網絡。因爲深度學習就是建立一個多層的神經網絡。有些簡單的算法可能只有四五層,但是有些複雜的,谷歌裏面有一百多層,不同的層負責不同的處理方式,如磁化層等等。
當然這其中每一層有時候會去做一些數學計算,有的層會做圖象預算,一般隨着層級往下,特徵會越來越抽象。比如我們人認識一個東西,我們可能先把桌子的幾個邊緣抓過來,結果每個邊緣和輪廓組成的可能性都很多。基於輪廓的組成,我們可把這個桌子抽象成幾層,可能第一層是這裏有個什麼線,然後逐漸往下抽象程度會由點到線到面,或者到更多的面等等這樣的過程。這是一個抽象的過程。
機器學習方案和深度學習方案的區別:
而這兩種「學習」的區別,舉個例子來說:比如要識別具體環境中的人臉,如果遇到雲霧,或者被樹遮擋一部分,人臉就變得殘缺與模糊,那基於像素的像素特徵的機器學習就無法辨認了。它太僵化,太容易受環境條件的干擾。
而深度學習則將所有元素都打碎,然後用神經元進行「檢查」:人臉的五官特徵、人臉的典型尺寸等等。最後,神經網絡會根據各種因素以及各種元素的權重,給出一個經過深思熟慮的猜測,即這個圖像有多大可能是張人臉。
移動平臺上用深度學習替換機器學習算法:
具體到應用層面,在移動設備上,採用機器學習進行人臉識別,是目前的主流做法。將深度學習遷移到移動設備上,這算是時下的研究熱點。深度學習的效果很好,但是前提是建立在大量的計算基礎上。雖然現在的手機硬件性能已經很好,但如果要運行深度學習的模型,手機的電量會是個問題。
據我瞭解,目前已經有一些公司已經成功在手機上實現了低能耗的深度學習算法。目前我們也在做相關研究,在移動平臺上用深度學習替換機器學習算法。
再回到直播中的給人臉實時貼圖或者「整容」,實現這一效果主要應用我上面提到的人臉識別技術,檢測並識別出人臉的關鍵點再進行圖像處理即可。
改變眼睛和臉型涉及到美醜的問題,如何讓計算機懂得「審美」?
改變眼睛與臉型這類美顏,因爲要涉及到人臉識別的問題,就像我剛纔說的原理,非常複雜,對計算量的要求也非常大。
目前這類美顏一般都是基於機器學習的,參數在編寫程序時已經確定好,並沒有計算機「自己」調整的過程。所以,目前的美顏的「美」,都是我們人爲的來控制。當然,這個人爲也不是說程序員自己可以隨便編,而是要與美工人員共同參與來完成的。
舉例來說:在一些比較專業的圖象處理論壇裏面,有設計師會發一些經過處理的美女圖片來。一般是發張原圖,發張經過處理之後出來一個效果圖,原圖跟效果圖之間有個差異,我們可以通過技術手段得到這個差異。然後把這個差異應用在我們做美膚裏面去,這就是調整膚色的做法。
圖片跟圖片之間可以通過一些手法去模擬到這個效果,這中間的過程都是可以計算出來的。然後在濾鏡、PS,或者是圖象處理裏的一項技術,去控制一張圖片的顏色表現。通過把技術人員跟美工人員結合起來,技術只管技術,美工只管美工,這樣就能夠開發與設計結合起來,實現所謂的「美」。
所以你看很多平臺算法都大同小異,但是爲什麼最終出來的美顏效果讓人感覺還是有差異,其實就是說裏面有很多細節在,需要花時間優化,特別是用戶的需求是什麼,怎樣更漂亮。
未來深度學習的技術更爲成熟時,電腦也許就可以憑藉海量的數據來總結出美來,進而按這種總結出的「審美」來處理圖像。但話說回來,「美」終究還是一種很主觀的事,就像之前有人通過大量美女圖片合成過各個國家標準的美女臉來,還是很多人覺得不好看,就是這個原因。
直播美顏目前面臨最大的技術難題是什麼?
暫時沒有很大的技術難題,Android 設備適配可以算一個。由於 Android 設備和系統類型較多,導致在 Android 平臺上,直播美顏很難做到兼容所有設備。Android 直播,從技術上分爲硬編和軟編兩種方案。
硬編:即採用硬件加速,通過 GPU 進行視頻編碼。特性是省電、性能好,是目前最佳的方案。但無法支持個別機型。Android 4.3 + 以上的系統才支持這個方案。(這其實不是問題了,現在主流的設備都是 Android 5.0 以上);另一方面,一些廠商在硬件層和軟件層做適配時,缺乏相關支持。
軟編:通過 CPU 進行視頻編碼,比較耗電、性能差,但能兼容絕大部分設備。主流的直播平臺一般是根據進行來自動適配,保證最佳效果。
羣友問答環節
美顏技術如何嵌入在硬件中,如美圖手機和卡西歐自拍神器?
美圖手機使用的是 Android 系統,在軟件層面,和一般的應用開發應該是相似的:也就是開發一款拍照應用,通過調用系統 API 訪問相機,採集到畫面,然後通過美顏處理。
在 Android 平臺一般使用 OpenGL ES 進行圖像處理。在 OpenGL ES 中編寫算法,實現效果,最後將處理的結果傳輸給 CPU,然後生成最終的照片。
至於卡西歐自拍神器,據我所知這個應該使用的是廠商自己的系統。我分析整個運行流程和 Android 系統相似。它的效果比較好,除了算法之外,在硬件上應該也有自己獨特的處理元件。
動態美顏怎麼保證在時序下不同角度的同一人物的美顏效果相同?
這個沒法保證。不過,不同角度、不同光照使得人物看起來本來就是不同的效果。
運動物體檢測 + 跟蹤,然後把人臉部分單獨提取出來做美化,這樣做對於性能的要求是提高了還是會降低?
一般都沒有把人臉單獨提取出來做美化,美化是通過膚色檢測來確定美顏範圍的。運動物體檢測 + 跟蹤,指的是人臉檢測嗎?如果是,對性能的要求肯定是提高了。如果要追蹤的比較緊,需要每幀都做檢測,性能要求肯定是非常高,以毫秒計。
雙邊濾波的多數實現似乎也無法達到實時性的需求,請問這裏有什麼 trick 嗎?
主要是性能優化吧,比如一般圖像卷積處理,是選周圍 8 個點,可以減少爲 4個。OpenGL ES 腳本按順序執行,我們需要逐點處理,減少處理的點,這樣速度會提上去。GPUImage 開源庫裏有可參考的代碼。
深度學習類算法應用於哪些方面呢?相比傳統的基於特徵的算法,性能差距至少是兩個數量級吧?
深度學習採用的多層神經網絡,運算量大,相比傳統的機器學習算法,一般來說,差距至少是好幾個數量級,這個和網絡結構、層級等有直接關係。應用的範圍很廣,包括圖像識別、語音識別、翻譯、數據挖掘等。
在移動設備上,使用深度學習來實現一些圖像識別的功能,這是時下的一個研究熱點。前段時間 Caffe 的作者在手機上實現了實時處理視頻添加類似 Prisma 的網絡結構,使用的是經過優化的 Caffe2 版本。隨着手機硬件越來越高,在上面跑多層神經網絡逐漸成爲可能,甚至是實時處理都已經不是問題。
iOS 9 開始,蘋果就提供了深度學習 API ,在 iOS 10,相關 API 得到更新。可以理解爲, iPhone 7 以後,進行深度學習的開發,已經逐漸成熟了。
想要隨時隨地跟大牛嘉賓交流嗎?想要第一時間掌握公開課信息嗎?想要找到志同道合的小夥伴嗎?
歡迎掃描下方二維碼,關注 AI 科技評論公衆號。

