雷鋒網按:本文作者何之源,復旦大學計算機科學碩士在讀,研究人工智能計算機視覺方向。本文由雷鋒網(公衆號:雷鋒網)獨家首發。
一、一個神奇的網站
前些日子在Qiita上看到了一篇神奇的帖子:Girl Friend Factory 機械學習で彼女を創る Qiita。帖子裏面提到利用GAN,通過文字描述來生成二次元圖像。這篇文章的作者還把他的想法搭建成了一個網站(網站地址:Girl Friend Factory),大概長下面這樣:
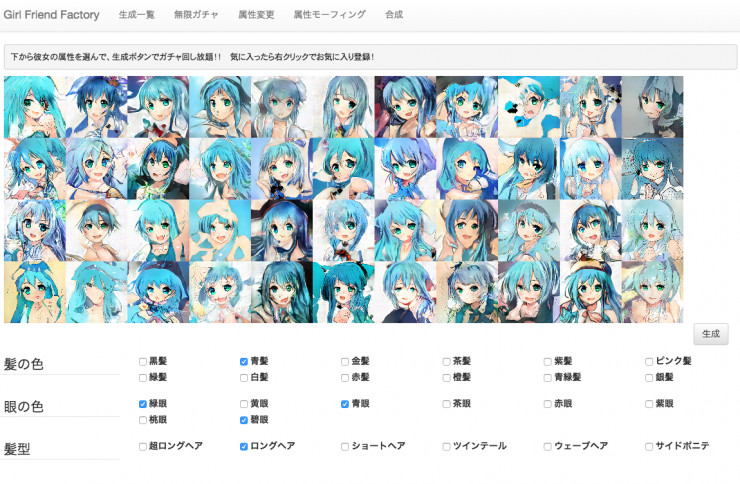
我之前也寫過一篇文章介紹瞭如何利用GAN生成簡單的二次元人物頭像,但那只是完全的隨機生成,你無法控制生成出的人物的屬性。但這篇Qiita的帖子不一樣,我們可以指定生成人物的屬性,如髮色、眼睛的顏色、髮型,甚至是服裝、裝飾物,從而生成具有指定屬性的圖像。
這個網站提供的屬性非常多,我簡單地把它們翻譯了一下:
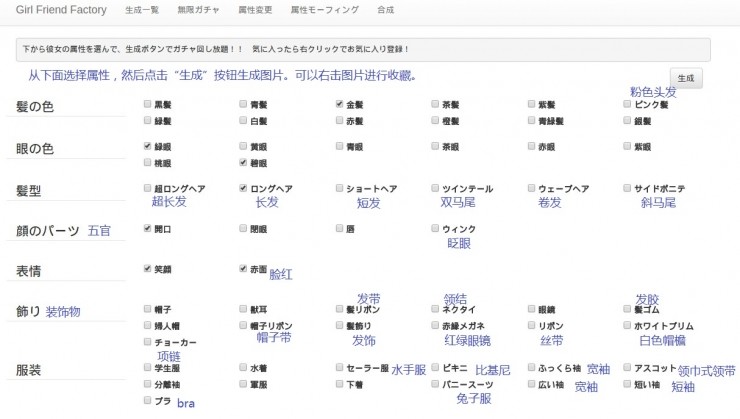
我會在後面詳細地介紹它的實現原理,在那之前,我們先來試着玩一玩這個網站。
進入網站後,首先要等待模型加載(注意:這個網站國內可能出現連接不上的問題,需要自行解決。另外網站大概會下載70M左右的模型,需要耐心等待。)加載好後,點擊上方的「無限ガチャ」(無限ガチャ實際上是「無限扭蛋器」的意思),就可以進行生成了。
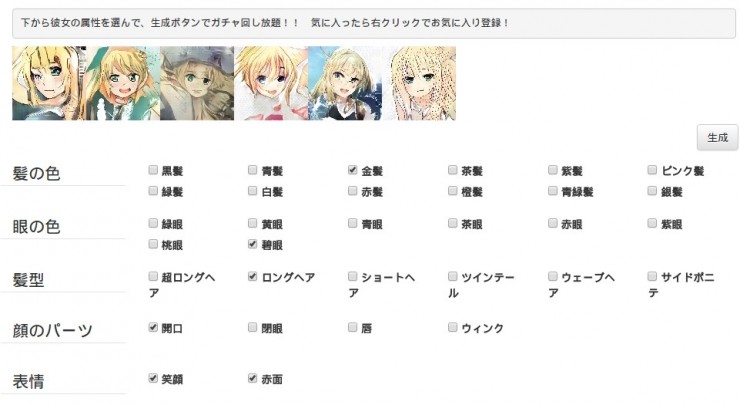
先生成一個金髮+碧眼,多次點擊生成按鈕可以生成多個,效果還可以:
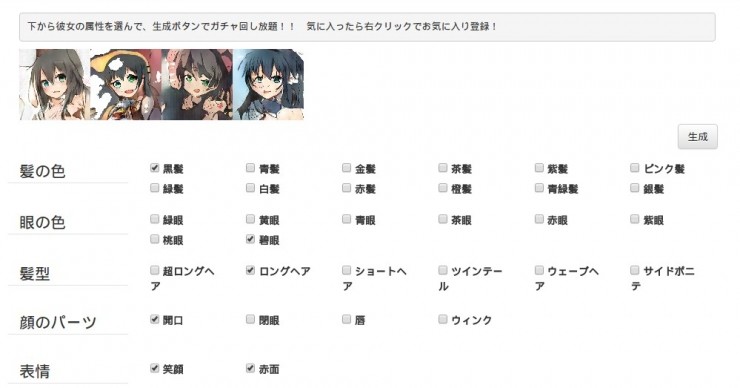
再生成黑髮+碧眼試試:
右擊圖像可以「註冊爲喜歡」,實際上就是一個收藏的功能。收藏之後可以"生成一覧"中找到。
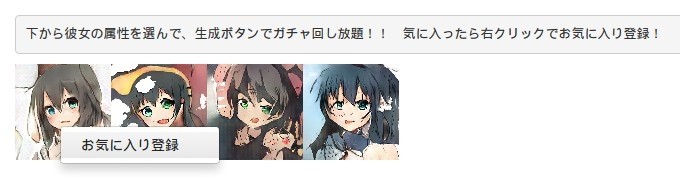
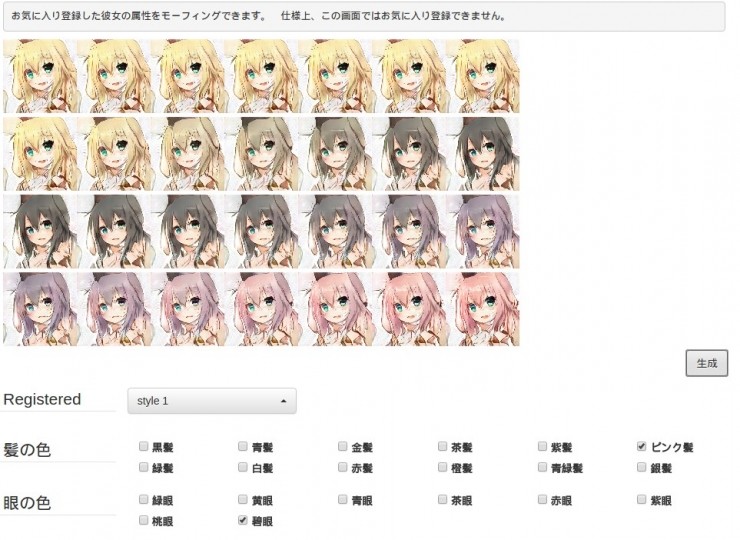
另外,收藏圖片後,點擊上方的"屬性モーフィング"還可以對屬性做微調,如這裏我可以更改髮色:
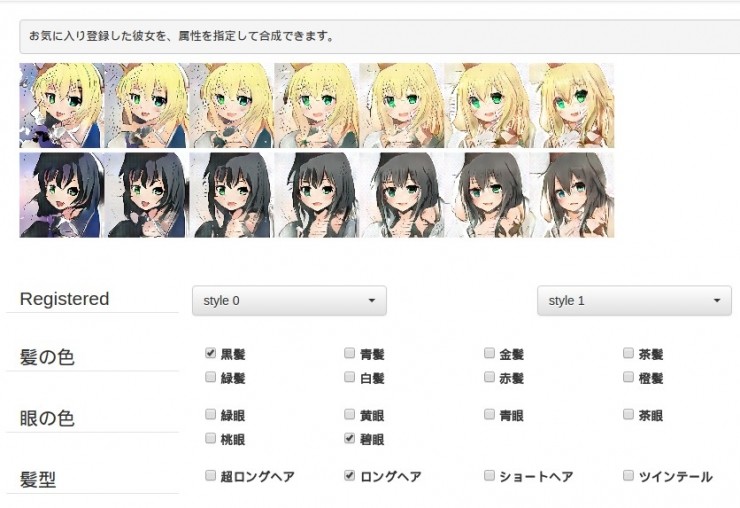
點擊上方的"合成"按鈕,你甚至可以把兩個人物合成同一個!如下圖所示:
二、基本原理
上面的網站的原理是什麼呢?原作者也提到了,其實就源於Generative Adversarial Text to Image Synthesis這篇論文。接下來就一起看一下它是怎麼做的。
我們的目標實際上是通過「文字」生成「圖像」。爲此我們需要解決以下兩個問題:
如何把文字描述表示成合適的向量。
如何利用這個描述向量生成合適的圖片。
其中,第一個問題是用了之前一篇論文中的技術,這裏就不細講了。假設文字描述爲t,我們可以通過一個函數φ將其轉換爲一個向量φ(t)。
第二個問題,如何利用向量φ(t)生成合適的圖像?這就是GAN的工作,文中GAN的結構如下圖所示:
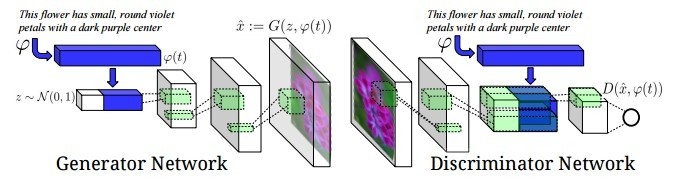
對比原始的GAN結構,這裏對生成網絡G和判別網絡D的輸入部分做了更改:
對於圖像生成網絡G,原來是接收一個無意義的噪聲z,輸出一個圖像G(z)。而這裏不僅接收噪聲z,還接收文字描述向量φ(t),用這兩部分共同生成一個圖像G(z, φ(t))。
對於判別網絡D,原來是接收圖像x, 輸出打分D(x),現在不僅接收圖像x,還接收文字描述φ(t)。最後輸出打分D(x, φ(t))
這實際上就是一個條件GAN(conditional GAN)。只需要簡單地更改一下原始GAN的結構就可以完成。到了這裏,就可以直接訓練了,也可以完成我們文字 >圖片的生成任務。但是直接訓練的生成圖片的質量不是很好,對此作者又提出了兩點改進。
三、改進一:GANCLS(針對判別器D的改進)
爲什麼直接訓練的效果不好?仔細想一下,我們會發現,在原始的GAN中,判別網絡D只需要做一件事情,即判斷生成的圖片是否正常。但在這裏,判別網絡D需要做兩件事情,一是和原始的GAN一樣,判斷圖片是否正常,二是判斷生成的圖片是否符合文字描述。
因此,我們對原來的訓練步驟做一些改進。不僅給D提供生成的圖片和真實的圖片兩類樣本,還給D提供真實圖片 + 虛假描述的樣本,強化D的訓練效果,強迫D判斷生成的圖片是否真的符合文字描述。具體的訓練步驟如下:

我們可以看到,D的梯度由三部分構成:sr, sw, sf。sr是真實圖片+正確文字。sw是真實圖片 + 錯誤描述。sf是G生成的圖片 + 正確描述。這樣就可以加快D的訓練進程,提高訓練效率。
四、改進二:GANINT(針對G的改進)
要理解這部分改進,首先要明白,我們只使用了sf訓練生成網絡G(見上面的圖片)。sf是什麼呢?它只和G生成的圖片、正確的文字描述兩項有關係,也就是說,sf是和真實圖片樣本無關的。因此,我們可不可以用一種方法,增加正確文字描述的樣本數呢?
答案是可以,因爲我們只用到了文字描述的嵌入φ(t),在嵌入空間中我們實際是可以做一些簡單的加減運算的。
設一個文字描述是φ(t1),另一個文字描述是φ(t2),我們可以得到他們的一個內插值aφ(t1) +(1a)φ(t2)。其中0<a<1。這樣的內插實際上是得到了兩個文字描述的某種「中間態」,爲我們增加了樣本數量。
我們知道,對於深度學習,樣本數量越多,效果就會越好,因此這裏的GANINT是對效果的提升有幫助的,實驗中驗證了這一點。
作者把上面的兩種改進合在一起,就成了GANINTCLS,也是這篇文章的最終方法。
放一張論文作者實驗的圖,他是做了花的生成,最上面一行是Ground Truth,下面依次是GAN,GANCLS,GANINT,GANINTCLS:

五、參考資料
Girl Friend Factory 機械學習で彼女を創る Qiita
Conditional Generative Adversarial Nets
Generative Adversarial Text to Image Synthesis
雷鋒網特約稿件,未經授權禁止轉載。詳情見轉載須知。
