生成對抗網絡一直是非常美妙且高效的方法,自 14 年 Ian Goodfellow 等人提出第一個生成對抗網絡以來,各種變體和修正版如雨後春筍般出現,它們都有各自的特性和對應的優勢。本文介紹了主流的生成對抗網絡及其對應的 PyTorch 和 Keras 實現代碼,希望對各位讀者在 GAN 上的理解與實現有所幫助。
PyTorch 實現地址:https://github.com/eriklindernoren/PyTorch-GAN
Keras 實現地址:https://github.com/eriklindernoren/Keras-GAN
生成對抗網絡及其變體的實現分爲基於 Keras 和基於 PyTorch 兩個版本。它們都是按照原論文實現的,但模型架構並不一定完全和原論文相同,作者關注於實現這些論文最核心的思想,而並不確定所有層級的配置都和原論文完全一致。本文首先將介紹各種 GAN 的論文摘要,然後提供詳細論文和實現的地址。
要使用 PyTorch 或 Keras 實現這些 GAN,我們首先需要下載兩個代碼倉庫,並安裝對應所需的依賴包。在終端運行以下命令行將下載 PyTorch-GAN 代碼庫並安裝所需的依賴包:
$ git clone https://github.com/eriklindernoren/PyTorch-GAN$ cd PyTorch-GAN/$ sudo pip3 install -r requirements.txt運行以下命令將下載並安裝 Keras-GAN 代碼庫:
$ git clone https://github.com/eriklindernoren/Keras-GAN$ cd Keras-GAN/$ sudo pip3 install -r requirements.txt實現
Auxiliary Classifier GAN
論文:Conditional Image Synthesis With Auxiliary Classifier GANs
作者:Augustus Odena、Christopher Olah 和 Jonathon Shlens
論文地址:https://arxiv.org/abs/1610.09585
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/acgan/acgan.py
合成高分辨率的真實感圖像一直是機器學習中的長期挑戰。在本論文中,作者介紹了一種用於提升 GAN 在圖像合成方面訓練效果的新方法。他們構建了一種採用標籤條件(label conditioning)的 GAN 變體,這種方法可以生成 128×128 分辨率的圖像樣本,且能展現出全局一致性。該論文擴展了以前的圖像質量評估工作,以提供兩個新的分析來評估類別條件(class-conditional)圖像合成模型中樣本的辨識度和多樣性。在 ImageNet 的 1000 個類別中,128×128 的樣本要比手動調整爲 32×32 的樣本高兩倍多的可辨識度。此外,84.7% 的類別具有與 ImageNet 真實圖像相媲美的樣本。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練 acgan:
$ cd implementations/acgan/$ python3 acgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd acgan/$ python3 acgan.py對抗自編碼器(Adversarial Autoencoder)
論文:Adversarial Autoencoders
作者:Alireza Makhzani、Jonathon Shlens、Navdeep Jaitly、Ian Goodfellow 和 Brendan Frey
論文地址:https://arxiv.org/abs/1511.05644
在這篇論文中,作者們提出了「對抗自編碼器」(AAE),它是一種概率自編碼器,且通過最近提出的生成對抗網絡實現變分推斷。簡單而言,即通過匹配自編碼器隱藏編碼向量的聚合後驗分佈(aggregated posterior)和任意的先驗分佈。匹配聚合後驗分佈和先驗分佈確保了從任意先驗空間中的採樣都能生成有意義的樣本。最後,對抗自編碼器的解碼器將學習一個深度生成模型以將先驗分佈映射到數據分佈中。作者們展示了對抗自編碼器如何應用於半監督分類、圖像內容和風格解析、無監督聚類、降維算法和數據可視化等內容。作者還實現了一些實驗,並在生成建模和半監督分類任務中取得了很好的性能。
如果當前地址爲 PyTorch-GAN/,那麼你可以輸入以下命令行,用 PyTorch 開始訓練 AAE:
$ cd implementations/aae/$ python3 aae.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd aae/$ python3 aae.pyBoundary-Seeking GAN
論文:Boundary-Seeking Generative Adversarial Networks
作者:R Devon Hjelm、Athul Paul Jacob、Tong Che、Adam Trischler、Kyunghyun Cho 和 Yoshua Bengio
論文地址:https://arxiv.org/abs/1702.08431
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/bgan/bgan.py
生成對抗網絡(GAN)是一種學習框架,它依賴訓練判別器來度量目標和生成分佈之間的差距。正如通常所說的,GAN 依賴於生成的樣本對生成器的參數是完全可微的,因此它是適用於離散數據。作者引入了一種用離散數據訓練 GAN 的方法,該方式使用判別器的差異度量來計算生成樣本的重要權重,從而爲訓練生成器提供策略梯度。此外,重要權重與判別器的決策邊界有非常強的聯繫,因此作者們稱這種方法爲 boundary-seeking GAN(BGAN)。他們證明了該算法在離散圖像和字符級的自然語言生成任務上具有高效性。此外,搜索判別器邊界的目標可擴展到連續數據,並用來提升訓練的穩定性。最後,該論文還展示了在 Celeba、大規模臥室場景理解(LSUN)和不帶條件的 ImageNet 上具有優秀的性能。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將開始訓練 BGAN:
$ cd implementations/bgan/$ python3 bgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd bgan/$ python3 bgan.pyContext-Conditional GAN
論文:Boundary-Seeking Generative Adversarial Networks
作者:Emily Denton、Sam Gross 和 Rob Fergus
論文地址:https://arxiv.org/abs/1702.08431
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/ccgan/ccgan.py
本論文介紹了一種基於圖像的半監督學習方法,它在繪畫中將使用對抗性損失函數。我們將刪除隨機圖像塊後的圖像饋送給生成器,而生成器的任務就是根據周圍的像素填補這些刪除的圖像塊。然後將繪製後的圖像展現給判別器網絡,並判斷它們是否是真實圖像。這一任務可充當判別器標準監督訓練的正則化器。使用這種方法,我們能以半監督的方式直接訓練大規模 VGG 風格的網絡。最後,作者們還在 STL-10 和 PASSCAL 數據集上評估了該方法,它的結果能至少獲得當前業內最優的水平。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將開始訓練 CCGAN:
$ cd implementations/ccgan/$ python3 ccgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd ccgan/$ python3 ccgan.py條件 GAN
論文:Conditional Generative Adversarial Nets
作者:Mehdi Mirza 和 Simon Osindero
論文地址:https://arxiv.org/abs/1411.1784
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/cgan/cgan.py
生成對抗網絡近來被引入並作爲訓練生成模型的新方法。在本論文的研究工作中,作者們介紹了生成對抗網絡的的條件約束版,即可以通過數據 y 來構建生成網絡,而我們期望生成器和判別器能加上約束條件。作者表示模型可以以類別標籤爲條件生成 MNIST 手寫數字,同時還展示瞭如何使用該模型學習多模態模型,並提供了一個應用於圖像標註的簡單示例,他們展示了這種方法如何生成不屬於訓練標註的描述性標籤。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將開始訓練 CGAN:
$ cd implementations/cgan/$ python3 cgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd cgan/$ python3 cgan.pyCycleGAN
論文:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
作者:Jun-Yan Zhu、Taesung Park、Phillip Isola 和 Alexei A. Efros
論文地址:https://arxiv.org/abs/1703.10593
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/cyclegan/cyclegan.py
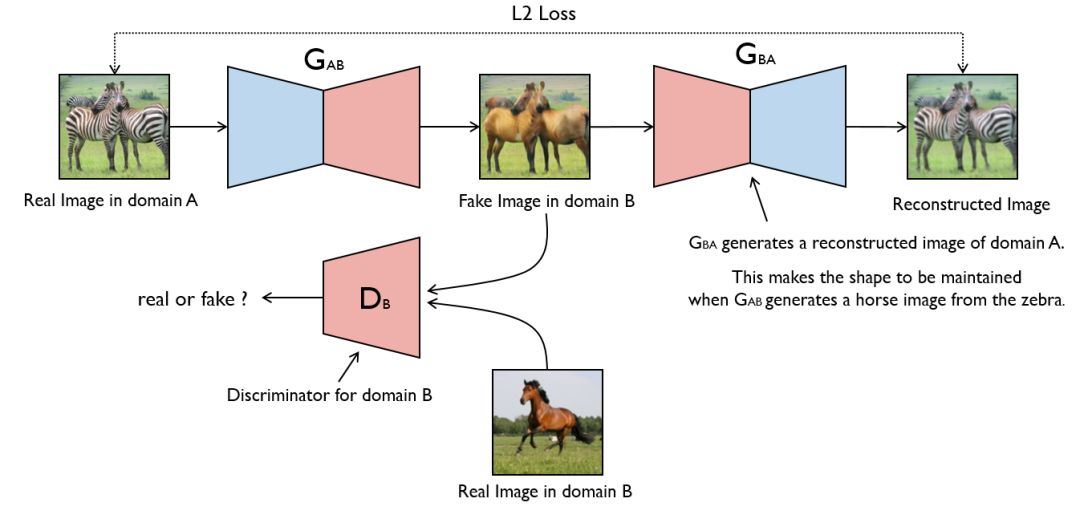
圖像到圖像變換是一種視覺和圖像問題,其目標是使用分配圖像配對的訓練集學習輸入圖像和輸出圖像之間的映射。然而,對於很多任務來說,配對的訓練數據是不可獲取的。作者提出了一種新方法,在沒有配對示例的限制下,學習從源域 X 到目標域 Y 的圖像變換。其目標是學習一個映射:X→Y,通過對抗損失使得 G(X)中的圖像分佈和 Y 的分佈是不可區分的。由於這個映射是高度受限的,作者將其和一個逆映射 F:Y→X 耦合,並引入了一個週期一致損失來迫使 F(G(X))≈X(反之亦然)。研究者在無配對訓練數據的多項任務(包括款式風格遷移、目標變形、季節遷移、照片增強等)上做了定性實驗。並且和多種之前方法的定量結果表明,該方法在性能上有優越性。
 如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd data/$ bash download_cyclegan_dataset.sh apple2orange$ cd ../implementations/cyclegan/$ python3 cyclegan.py --dataset_name apple2orange如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd cyclegan/$ bash download_dataset.sh apple2orange$ python3 cyclegan.py
第一行展示了兩個域的原始圖像。第二行展示了兩個圖像的變換版本。第三行展示了重構圖像。
Deep Convolutional GAN
論文:Deep Convolutional Generative Adversarial Network
作者:Alec Radford、Luke Metz 和 Soumith Chintala
論文地址:https://arxiv.org/abs/1511.06434
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/dcgan/dcgan.py
在 GAN 的第一篇論文出來之後的大概一年時間裏,訓練 GAN 與其說是科學,倒不如說是藝術——模型很不穩定,需要大量調整才能工作。2015 年時,Radford 等人發表了題爲《使用深度卷積生成對抗網絡的無監督表徵學習(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)》的論文,描述了之後被稱爲 DCGAN 的著名模型。
在 DCGAN 這項工作中,作者們引入一種帶有結構約束的卷積神經網絡,並證明深度卷積對抗網絡從目標到場景能學習層級表徵。
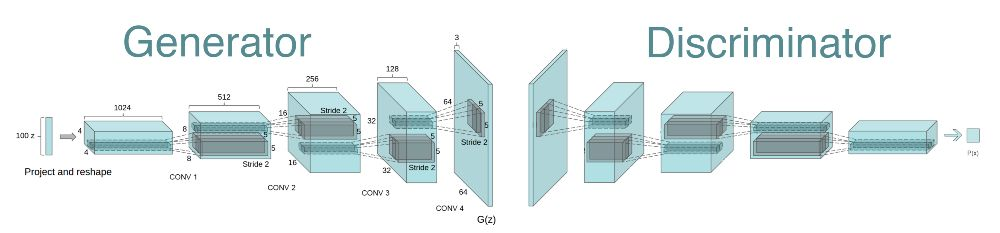
圖片來自:Radford et al., 2015
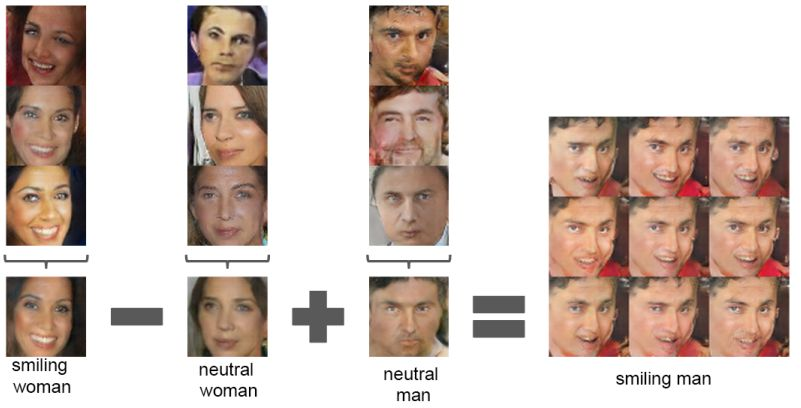
關於 DCGAN,最值得一提的是這個架構在大多數情況下都是穩定的。這是第一篇使用向量運算描述生成器學習到的表徵的固有性質的論文:這與 Word2Vec 中的詞向量使用的技巧一樣,但卻是對圖像操作的!
 圖片來自:Radford et al., 2015
圖片來自:Radford et al., 2015
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/dcgan/$ python3 dcgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd dcgan/$ python3 dcgan.pyDiscoGAN(學習用生成對抗網絡發現跨域關係)
論文:Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
作者:Taeksoo Kim、Moonsu Cha、Hyunsoo Kim、Jung Kwon Lee 和 Jiwon Kim
論文地址:https://arxiv.org/abs/1703.05192
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/discogan/discogan.py
人類可以輕易地識別不同領域的數據之間的關係而不需要任何的監督,但讓機器學習自動化地發現這些關係是很大的挑戰並需要很多真實的配對來展示這些關係。爲了避免代價昂貴的配對工程,通過給定的非配對數據來發現跨域關係,作者提出了基於生成對抗網絡的方法來學習發現不同領域之間的關係,即 DiscoGAN。使用發現的關係,該網絡可以成功地將一個領域的風格遷移到另一個上,同時保持關鍵的屬性,例如定向和麪部身份。
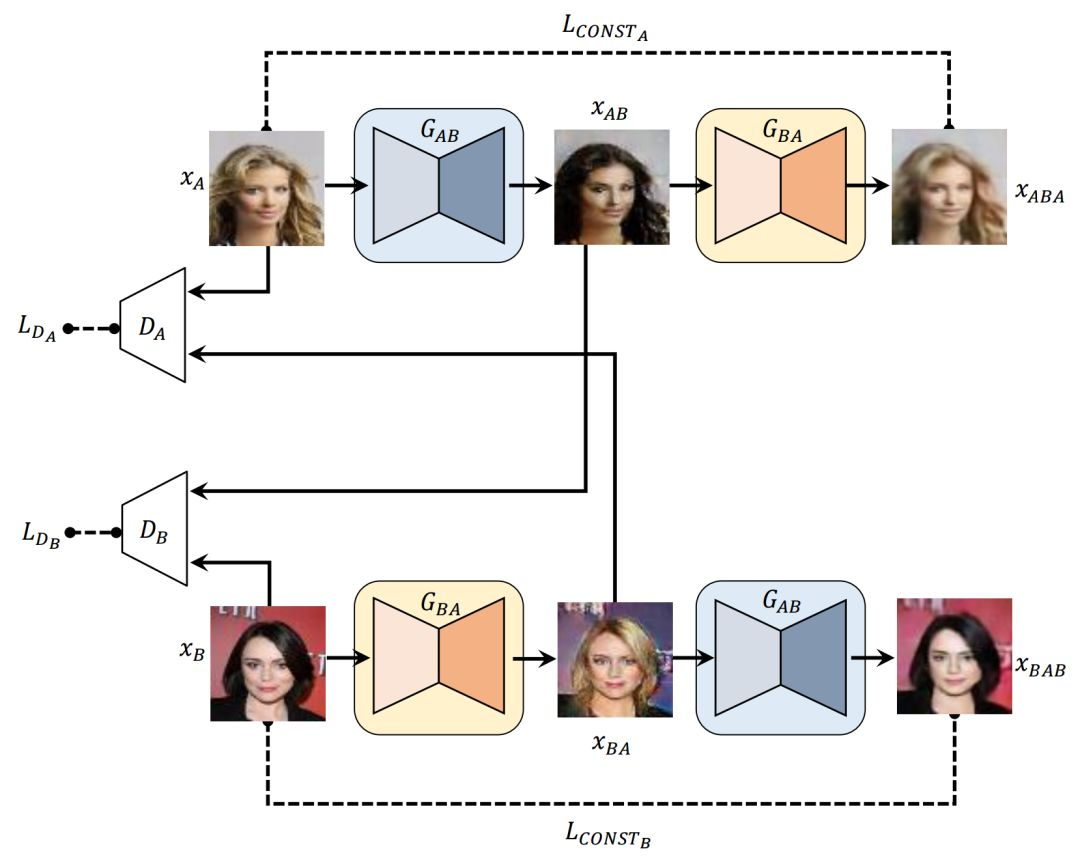
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd data/$ bash download_pix2pix_dataset.sh edges2shoes$ cd ../implementations/discogan/$ python3 discogan.py --dataset_name edges2shoes如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd discogan/$ bash download_dataset.sh edges2shoes$ python3 discogan.pyDRAGAN(改善 GAN 的收斂性和穩定性)
論文:On Convergence and Stability of GANs
作者:Naveen Kodali、Jacob Abernethy、James Hays 和 Zsolt Kira
論文地址:https://arxiv.org/abs/1705.07215
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/dragan/dragan.py
通過將 GAN 的訓練動態看成遺憾最小化過程,這和流行的角度相反(真實和生成分佈之間的偏離存在一致最小化)。作者從新的視角分析了 GAN 訓練過程的收斂行爲,易理解模式崩潰的原因。他們假定在非凸優化過程中出現的局域均衡是導致模式崩潰的原因。研究表明這些局域均衡通常導致判別器函數在某些真實數據點處的尖銳梯度,而使用一種稱爲 DRAGAN 的梯度懲罰方案可以避免這些退化的局域均衡。DRAGAN 可以讓訓練的速度更快,模型獲得更高的穩定性,以及更少的模式崩潰,在多種架構和目標函數的生成器網絡上得到更優的建模性能。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/dragan/$ python3 dragan.pyDualGAN
論文:DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
作者:Zili Yi、Hao Zhang、Ping Tan 和 Minglun Gong
論文地址:https://arxiv.org/abs/1704.02510
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/dualgan/dualgan.py
跨域圖像到圖像變換的條件生成網絡在近期取得了很大的進步。由於任務的複雜度,訓練一個條件 GAN 需要成千上百萬張標記的圖像。然而,人類標記是代價昂貴的,甚至是不可行的,並且很多數據可能是不可用的。受自然圖像變換的對偶學習啓發,一種新型的 Dual-GAN 機制被提出,它允許在兩個域的無標記圖像集訓練以實現圖像變換。在該架構中,原始 GAN 學習從域 U 向域 V 的圖像變換,同時,對偶的 GAN 學習將任務倒轉。由原始任務和對偶任務構成的循環允許圖像從任意兩個域之一被變換然後被重構。因此可以用關於重構誤差的損失函數來訓練變換器。在多個使用無標籤數據的圖像變換任務上的實驗表明,DualGAN 相比單個 GAN 可以取得相當好的結果。對於某些任務,DualGAN 甚至可以得到相當或稍微超越條件 GAN 在全標記數據上的結果。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd data/$ bash download_pix2pix_dataset.sh facades$ cd ../implementations/dualgan/$ python3 dualgan.py --dataset_name facades如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd dualgan/$ python3 dualgan.pyGAN
論文:Generative Adversarial Network
作者:Ian J. Goodfellow、Jean Pouget-Abadie、Mehdi Mirza、Bing Xu、David Warde-Farley、Sherjil Ozair、Aaron Courville 和 Yoshua Bengio
論文地址:https://arxiv.org/abs/1406.2661
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/gan/gan.py
GAN 最初由 Ian Goodfellow 提出,它有兩個網絡:生成器和鑑別器。兩個網絡在同一時間進行訓練,並在極小極大(minimax)遊戲中相互博弈。生成器通過創建逼真的圖像來試圖欺騙鑑別器,而鑑別器被訓練從而不被生成器所愚弄。首先,生成器生成圖像。它通過從簡單分佈中(例如正態分佈)採樣向量噪聲 Z,然後將該矢量上採樣到圖像來生成圖像。在第一次迭代中,這些圖像看起來很嘈雜。然後,鑑別器被給予真、假圖像,並學習區分它們。生成器稍後通過反向傳播步驟接收鑑別器的「反饋」,在產生圖像時變得更好。最後,我們希望假圖像的分佈儘可能接近真實圖像的分佈。或者,簡單來說,我們希望假圖像看起來儘可能貌似真實。
值得一提的是,由於 GAN 中使用的極小極大(minimax)優化,訓練有可能相當不穩定。但是,有一些技巧可以用來使得訓練更魯棒。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/gan/$ python3 gan.pyKeras 示例 1:如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd gan/$ python3 gan.pyKeras 示例 2:如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd gan/
$ python3 gan_rgb.py
Least Squares GAN
論文:Least Squares Generative Adversarial Networks
作者:Xudong Mao、Qing Li、Haoran Xie、Raymond Y.K. Lau、Zhen Wang 和 Stephen Paul Smolley
論文地址:https://arxiv.org/abs/1611.04076
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/lsgan/lsgan.py
最近應用生成對抗網絡(generative adversarial networks/GAN)的無監督學習被證明是十分成功且有效的。常規生成對抗網絡假定作爲分類器的辨別器是使用 sigmoid 交叉熵損失函數(sigmoid cross entropy loss function)。然而這種損失函數可能在學習過程中導致導致梯度消失(vanishing gradient)問題。爲了克服這一困難,我們提出了最小二乘生成對抗網絡(Least Squares Generative Adversarial Networks/LSGANs),該生成對抗網絡的辨別器(discriminator)採用最小平方損失函數(least squares loss function)。我們也表明 LSGAN 的最小化目標函數(bjective function)服從最小化 Pearson X^2 divergence。LSGAN 比常規生成對抗網絡有兩個好處。首先 LSGAN 能夠比常規生成對抗網絡生成更加高質量的圖片。其次 LSGAN 在學習過程中更加地穩定。我們在五個事件數據集(scene datasets)和實驗結果上進行評估,結果證明由 LSGAN 生成的圖像看起來比由常規 GAN 生成的圖像更加真實一些。我們還對 LSGAN 和常規 GAN 進行了兩個比較實驗,其證明了 LSGAN 的穩定性。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/lsgan/$ python3 lsgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd lsgan/$ python3 lsgan.pyPix2Pix
論文:Unpaired Image-to-Image Translation with Conditional Adversarial Networks
作者:Phillip Isola、Jun-Yan Zhu、 Tinghui Zhou 和 Alexei A. Efros
論文地址:https://arxiv.org/abs/1611.07004
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/pix2pix/pix2pix.py
Pix2Pix 探索了將條件 GAN 作爲圖像到圖像變換問題的通用解決方案的可行性。這些網絡不僅能學習從輸入圖像到輸出圖像的變換,還能學習一個損失函數來訓練這個損失。這使其可以應用相同的一般性方法到傳統上需要非常不同的損失函數的問題上。研究表明該方法在從標籤映射合成照片、從邊緣映射重構圖像,以及圖像上色等任務上非常有效。實際上,由於和 Pix2Pix 論文相關的 pix2pix 軟件的發佈,已經有大量的網絡用戶(其中包括很多藝術家)發佈了用該系統處理的實驗結果,進一步展示了它的廣泛應用價值和不需要參數調整的易用性。不需要手動修改映射函數和損失函數,該方法就可以取得很優越的結果。
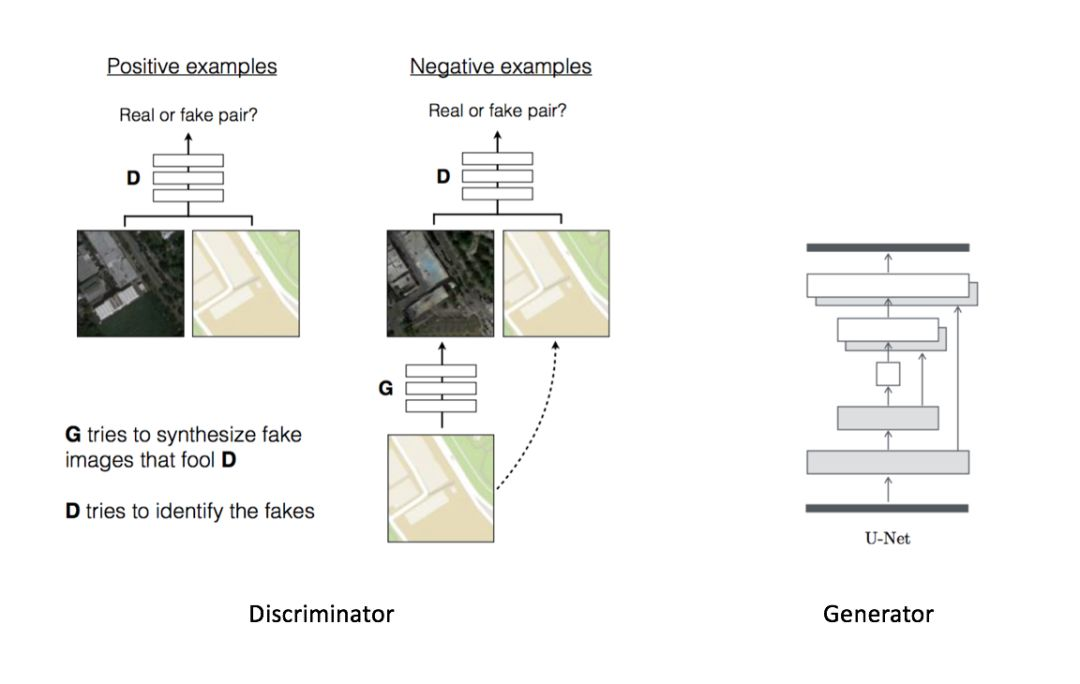
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd data/$ bash download_pix2pix_dataset.sh facades$ cd ../implementations/pix2pix/$ python3 pix2pix.py --dataset_name facades如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd pix2pix/$ bash download_dataset.sh facades$ python3 pix2pix.py
第一行展示了生成器的條件,第二行展示了輸出,第三行展示了條件對應的真實圖像。
PixelDA
論文:Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks
作者:Konstantinos Bousmalis、Nathan Silberman、David Dohan、Dumitru Erhan 和 Dilip Krishnan
論文地址:https://arxiv.org/abs/1612.05424
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/pixelda/pixelda.py
對於很多任務而言,收集標註良好的圖像數據集來訓練機器學習算法是代價昂貴的。一個有吸引力的替代方案是渲染合成數據,其中真實標籤是自動生成的。不幸的是,純粹在渲染圖像上訓練的模型通常無法泛化到真實圖像上,爲了解決這個弊端,以前的研究通過引入無監督域適應算法來實現兩個領域的表徵映射,並學習提取域不變的特徵。在 PixelDA 中,作者提出了一個新的方法,以無監督的方式在像素空間中實現域變換。該基於生成對抗網絡的方法將源域的圖像渲染成像是來自目標域的圖像。該方法不僅能生成可信的樣本,還在多個無監督域適應場景中大幅超越了當前最佳方法。最後,研究表明該適應過程可以泛化到訓練過程中未見過的目標類別。
從 MNIST 到 MNIST-M 的分類性能
PixelDA 在 MNIST 上訓練一個分類器,並可以變換到和 MNIST-M 相似的圖像(通過執行無監督的圖像到圖像域適應)。該模型和在 MNIST 上訓練分類器並在 MNIST-M 上評估的樸素方法對比。樸素方法在 MNIST 上取得了 55% 的準確率,而在域適應上訓練的模型獲得了 95% 的分類準確率。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/pixelda/$ python3 pixelda.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd pixelda/$ python3 pixelda.py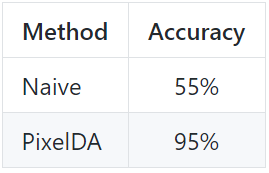

第一行展示了 MNIST 域的原始圖像。中間行展示了第一行圖像的變換版本。最後一行展示了 MNIST-M 域的圖像示例。
Semi-Supervised GAN
論文:Semi-Supervised Learning with Generative Adversarial Networks
作者:Augustus Odena
論文地址:https://arxiv.org/abs/1606.01583
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/sgan/sgan.py
半監督生成對抗網絡通過強制判別器網絡輸出類別標籤將生成對抗網絡(GAN)擴展到半監督情境中。論文作者在一個數據集上訓練了一個生成器 G 和判別器 D,其中每個輸入屬於 N 個類別之一。在訓練時,D 被用於預測輸入屬於 N+1 個類別的哪一個,其中額外的類別對應於 G 的輸出。研究表明該方法可以用於構建一個數據高效的分類器,相比於常規的 GAN,它可以生成更加高質量的樣本。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/sgan/$ python3 sgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd sgan/$ python3 sgan.pySuper-Resolution GAN
論文:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
作者:Christian Ledig、Lucas Theis、Ferenc Huszar、Jose Caballero、Andrew Cunningham、Alejandro Acosta、Andrew Aitken、Alykhan Tejani、Johannes Totz、Zehan Wang 和 Wenzhe Shi
論文地址:https://arxiv.org/abs/1609.04802
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/srgan/srgan.py
儘管使用更快和更深的卷積神經網絡在單張圖像超分辨率上已經得到了準確率和速度的突破,仍然有一箇中心問題爲得到解決:如何在大的粗化(upscaling)係數時的超分辨率恢復精細紋理細節?基於優化的超分辨率方法的行爲在原則上是由目標函數的選擇驅動的。近期的研究主要聚焦於最小化重構均方誤差。得到的評估結果具有很高峯值的信噪比,但它們通常缺少高頻細節,並無法在高分辨率上匹配期望的保真度。
SRGAN 是一個用於圖像超分辨率的生成對抗網絡。這是首個能在 4x 粗化係數上推斷照片級自然圖像的框架。爲了達到這個目的,論文作者提出了一個感知損失函數,它一個對抗損失和一個內容損失構成。通過訓練判別網絡來區分超分辨圖像和原始照片級圖像,對抗損失迫使網絡生成自然圖像流形。此外,內容損失是通過感知相似性驅動的而不是像素空間的相似性。該架構使用的深度殘差網絡可以從公開基準的嚴重下采樣的圖像上恢復照片級紋理。擴展的平均意見分數(MOS)測試表明,使用 SRGAN 可以大大提高感知質量。使用 SRGAN 獲得的 MOS 分數和那些原始高分辨率圖像很相近,高於所有當前最佳方法。
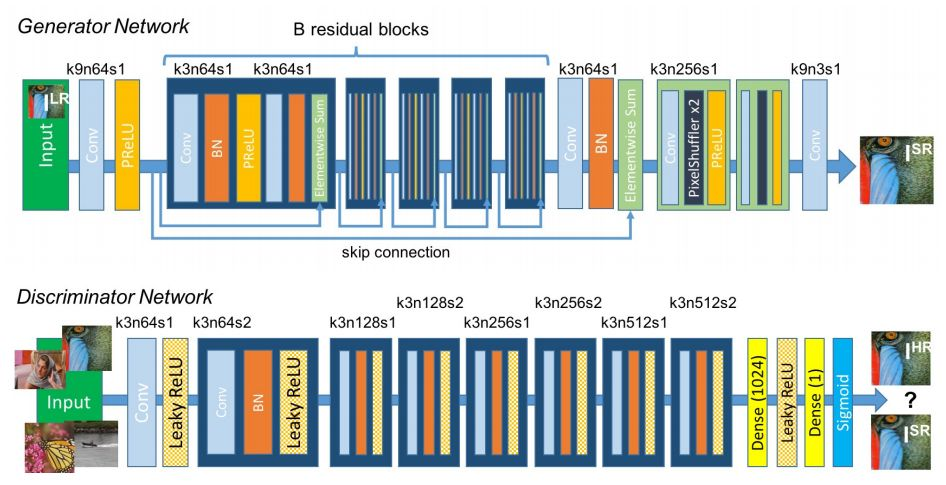
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/srgan/
$ python3 srgan.py
如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd srgan/
$ python3 srgan.py

第一行由 SRGAN 生成,第二行是全分辨率圖像。
Wasserstein GAN(WGAN)
論文:Wasserstein GAN
作者:Martin Arjovsky, Soumith Chintala, Léon Bottou
論文地址:https://arxiv.org/abs/1701.07875
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/wgan/wgan.py
通過改變損失函數以包含 Wasserstein 距離,WGAN 具有與圖像質量相關的損失函數。此外,訓練穩定性也提高了,而且不依賴於架構。
GAN 一直在收斂性方面存在問題,結果是,你不知道何時停止訓練。換句話說,損失函數與圖像質量不相關。這是一個頭痛的大問題,因爲:
你需要不斷查看樣本,以瞭解你的模型是否在正確訓練。
你不知道何時應該停止訓練(沒有收斂)。
你沒有一個量化數值告訴你調整參數的效果如何。
GAN 可被解釋以最小化 Jensen-Shannon 發散,如果真和假的分佈不重疊(通常是這種情況),則它爲 0。所以,作者使用了 Wasserstein 距離,而不是最小化 JS 發散,它描述了從一個分佈到另一個分佈的「點」之間的距離。因此,WGAN 具有與圖像質量相關的損失函數並能夠實現收斂。它也更加穩定,也就意味着它不依賴於架構。例如,即使你去掉批處理歸一化或嘗試奇怪的架構,它也能很好地工作。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/wgan/$ python3 wgan.py如果當前地址爲 Keras-GAN/,那麼我們需要使用 Keras 實現訓練:
$ cd wgan/$ python3 wgan.pyWasserstein GAN GP
論文:Improved Training of Wasserstein GANs
作者:Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville
論文地址:https://arxiv.org/abs/1704.00028
代碼地址:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/wgan_gp/wgan_gp.py
生成對抗網絡(GAN)是很強大的生成模型,但會遭遇訓練不穩定的問題。最近提出的 WGAN 提高了 GAN 的訓練穩定性,但有時候仍然會生成低質量的樣本或無法收斂。論文作者發現這些問題是由於 WGAN 中使用的權重修剪,以強制在判別器上添加一個 Lipschitz 約束,這會導致不希望出現的行爲。他們提出了權重修剪的替代方案:懲罰判別器的關於它的輸入的梯度範數。該方法相比標準的 WGAN 表現更好,在多種 GAN 架構中實現穩定的訓練,而幾乎不需要超參數的調整,包括 101 層的 ResNet 和離散數據上的語言模型。該方法可以在 CIFAR-10 和 LSUNbedrooms 數據集上生成高質量的圖像。
如果當前地址爲 PyTorch-GAN/,那麼使用以下命令行將使用 PyTorch 開始訓練:
$ cd implementations/wgan_gp/$ python3 wgan_gp.py